spark foreachPartition foreach
1.foreach
val list = new ArrayBuffer()
myRdd.foreach(record => {
list += record
})
2.foreachPartition
val list = new ArrayBuffer
rdd.foreachPartition(it => {
it.foreach(r => {
list += r
})
})
说明:
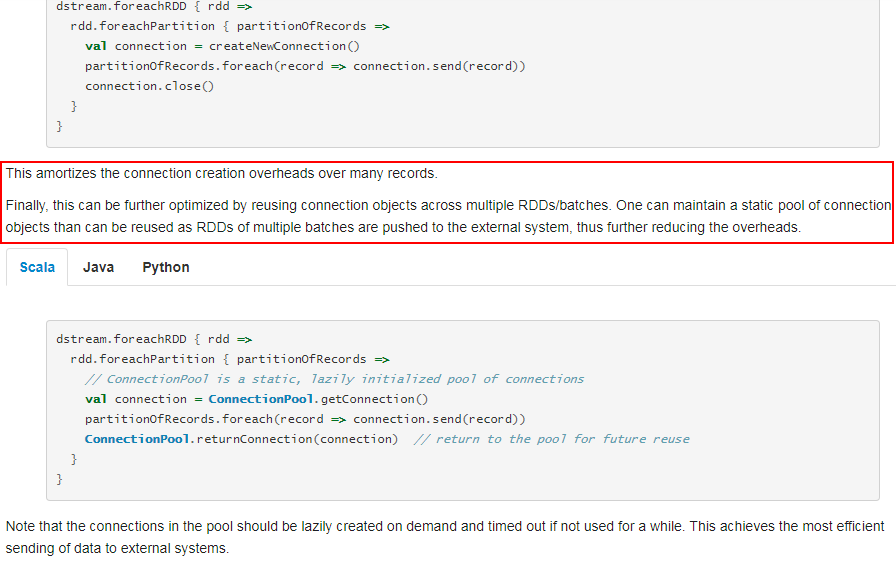
foreachPartition属于算子操作,可以提高模型效率。比如在使用foreach时,将RDD中所有数据写Mongo中,就会一条数据一条数据地写,每次函数调用可能就会创建一个数据库连接,此时就势必会频繁地创建和销毁数据库连接,性能是非常低下;但是如果用foreachPartitions算子一次性处理一个partition的数据,那么对于每个partition,只要创建一个数据库连接即可,然后执行批量插入操作,此时性能是比较高的。
参考官网的说明:
https://spark.apache.org/docs/latest/streaming-programming-guide.html
spark foreachPartition foreach的更多相关文章
- Spark算子--foreach和foreachPartition
转载请标明出处http://www.cnblogs.com/haozhengfei/p/6776fe93f754daf60d00d2cb509422a1.html foreach和foreachPar ...
- spark源代码action系列-foreach与foreachPartition
RDD.foreachPartition/foreach的操作 在这个action的操作中: 这两个action主要用于对每一个partition中的iterator时行迭代的处理.通过用户传入的fu ...
- Spark 3.x Spark Core详解 & 性能优化
Spark Core 1. 概述 Spark 是一种基于内存的快速.通用.可扩展的大数据分析计算引擎 1.1 Hadoop vs Spark 上面流程对应Hadoop的处理流程,下面对应着Spark的 ...
- Codis连接异常问题处理
报错信息可以看出:由于没有正常的关闭连接,导致连接异常 Caused by: redis.clients.jedis.exceptions.JedisConnectionException: Unex ...
- Fink| API| Time与Window
1. Flink 批处理Api 1.1 Source Flink+kafka是如何实现exactly-once语义的 Flink通过checkpoint来保存数据是否处理完成的状态: 有JobMana ...
- Flink的流处理API(二)
一.Environment 1,getExecutionEnvironment getExecutionEnvironment会根据查询运行的方式决定返回什么样的运行环境,是最常用的一种创建执行环境的 ...
- Spark:如何替换sc.parallelize(List(item1,item2)).collect().foreach(row=>{})为并行?
代码场景: 1)设定的几种数据场景,遍历所有场景:依次统计满足每种场景条件下的数据,并把统计结果存入hive: 2)已有代码如下: case class IndoorOTTCalibrateBuild ...
- spark基础知识介绍(包含foreachPartition写入mysql)
数据本地性 数据计算尽可能在数据所在的节点上运行,这样可以减少数据在网络上的传输,毕竟移动计算比移动数据代价小很多.进一步看,数据如果在运行节点的内存中,就能够进一步减少磁盘的I/O的传输.在spar ...
- 【Spark】SparkStreaming-foreachrdd foreachpartition
SparkStreaming-foreachrdd foreachpartition foreachrdd foreachpartition_百度搜索 SparkStreaming之foreachRD ...
随机推荐
- 【Weiss】【第03章】练习3.21:单数组模拟双栈
[练习3.21] 编写仅用一个数组而实现两个栈的例程.除非数组的每一个单元都被使用,否则栈例程不能有溢出声明. Answer: 很简单,一个栈从数组头起,一个栈从数组尾起,分别保留左右栈头索引. 如l ...
- 大数据软件安装之Flume(日志采集)
一.安装地址 1) Flume官网地址 http://flume.apache.org/ 2)文档查看地址 http://flume.apache.org/FlumeUserGuide.html 3) ...
- JAVA为什么不能通过构造函数传参来设置数组长度。
今天我们来说说 JAVA通过构造函数传递的参数来设置数组长度的问题. 问题在于我们没有明确知晓JVM的运行顺序.在new对象的时候,先调用构造函数,但是并没有将执行构造函数的代码,随机之后就初始化了 ...
- Quantitative Proteomics of Enriched Esophageal and Gut Tissues from the Human Blood Fluke Schistosoma mansoni Pinpoints Secreted Proteins for Vaccine Development (解读人:张聪敏)
文献名:Quantitative Proteomics of Enriched Esophageal and Gut Tissues from the Human Blood Fluke Schist ...
- Mol. Cell. Proteomics | 癌细胞衍生的小细胞外囊体通过促进HGF-Met途径促进受体细胞转移
题目:Cancer cell derived small extracellular vesicles contribute to recipient cell metastasis through ...
- linux入门系列19--数据库管理系统(DBMS)之MariaDB
前面讲完Linux下一系列服务的配置和使用之后,本文简单介绍一款数据库管理系统(MySQL的兄弟)MariaDB. 如果你有MySQL或其他数据的使用经验,MariaDB使用起来将非常轻松. 本文讲解 ...
- python 清空list的几种方法
本文介绍清空list的四种方法,以及 list=[ ] 和 list.clear() 在使用中的区别(坑). 1.使用clear()方法 lists = [1, 2, 1, 1, 5] lists.c ...
- 洛谷1258 Tire字典树
直接上代码: #include<bits/stdc++.h> using namespace std; typedef unsigned int ui; typedef long long ...
- 自定义实现 PyQt5 下拉复选框 ComboCheckBox
一.前言 由于最近的项目需要具有复选功能,但过多的复选框会影响界面布局和美观,因而想到把 PyQt5 的下拉列表和复选框结合起来,但在 PyQt5 中并没有这样的组件供我们使用,所以想要自己实现一个下 ...
- 【Excel使用技巧】vlookup函数
背景 前不久开发了一个运营小工具,运营人员上传一个id的列表,即可导出对应id的额外数据.需求本身不复杂,很快就开发完了,但上线后,运营反馈了一个问题,导出后的数据跟导出之前的数据顺序不一致. 经过沟 ...