使用Keras进行深度学习:(三)使用text-CNN处理自然语言(上)
欢迎大家关注我们的网站和系列教程:http://www.tensorflownews.com/,学习更多的机器学习、深度学习的知识!
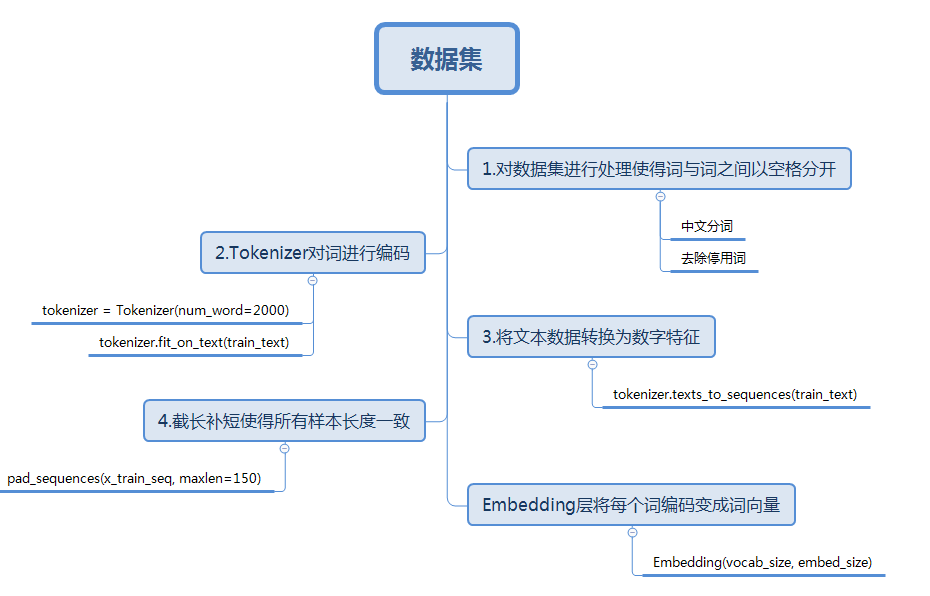
上一篇文章中一直围绕着CNN处理图像数据进行讲解,而CNN除了处理图像数据之外,还适用于文本分类。CNN模型首次使用在文本分类,是Yoon Kim发表的“Convolutional Neural Networks for Sentence Classification”论文中。在讲解text-CNN之前,先介绍自然语言处理和Keras对自然语言的预处理。
自然语言处理就是通过对文本进行分析,从文本中提取关键词来让计算机处理或理解自然语言,完成一些有用的应用,如:情感分析,问答系统等。比如在情感分析中,其本质就是根据已知的文字和情感符号(如评论等)推测这段文字是正面还是负面的。想象一下,如果我们能够更加精确地进行情感分析,可以大大提升人们对于事物的理解效率。比如不少基金公司利用人们对于某家公司的看法态度来预测未来股票的涨跌。
接下来将使用imdb影评数据集简单介绍Keras如何预处理文本数据。该数据集在这里下载。由于下载得的是tar.gz压缩文件,可以使用python的tarfile模块解压。解压后的目录为:
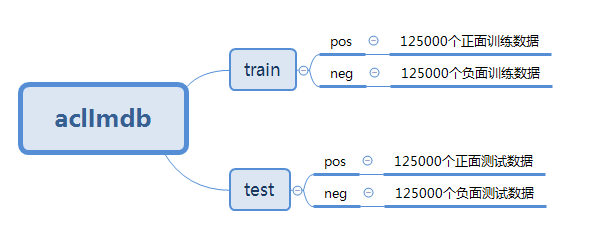
1.读取imdb数据集
我们通过以下函数分别读取train和test中的所有影评
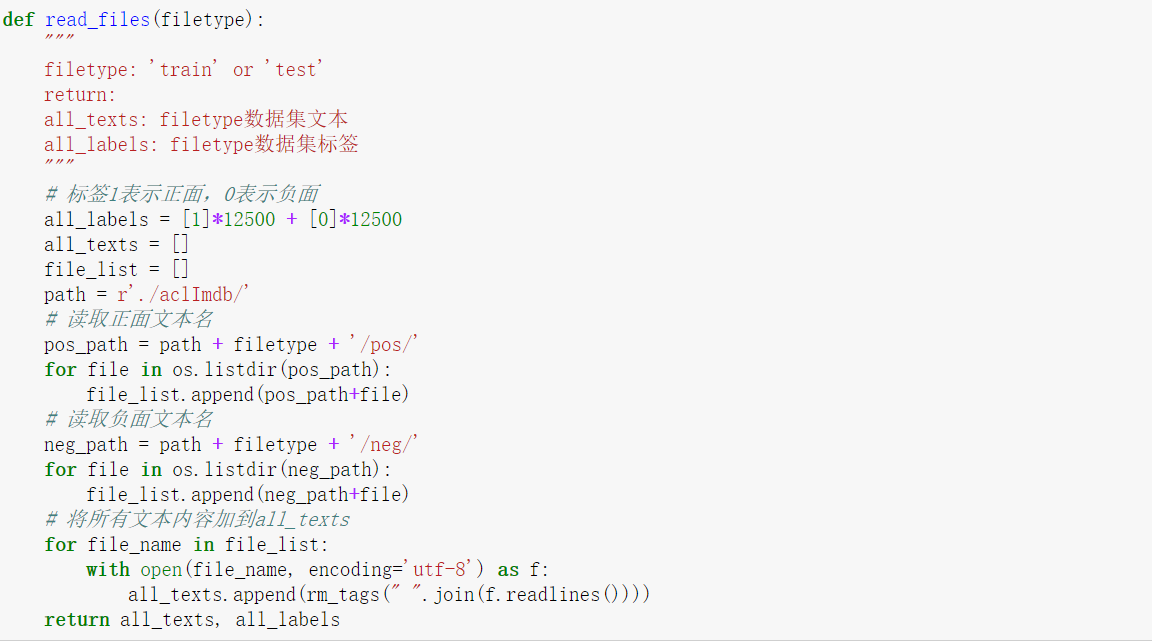
得到的影评如下图,每条影评用双引号包住。

2.使用Tokenizer将影评文字转换成数字特征
在上文中已经得到了每条影评文字了,但是text-CNN的输入应该是数字矩阵。可以使用Keras的Tokenizer模块实现转换。
简单讲解Tokenizer如何实现转换。当我们创建了一个Tokenizer对象后,使用该对象的fit_on_texts()函数,可以将输入的文本中的每个词编号,编号是根据词频的,词频越大,编号越小。可能这时会有疑问:Tokenizer是如何判断文本的一个词呢?其实它是以空格去识别每个词。因为英文的词与词之间是以空格分隔,所以我们可以直接将文本作为函数的参数,但是当我们处理中文文本时,我们需要使用分词工具将词与词分开,并且词间使用空格分开。具体实现如下:

使用word_index属性可以看到每次词对应的编码,可以发现类似”the”、”a”等词的词频很高,但是这些词并不能表达文本的主题,我们称之为停用词。对文本预处理的过程中,我们希望能够尽可能提取到更多关键词去表达这句话或文本的中心思想,因此我们可以将这些停用词去掉后再编码。网上有许多归纳好的停用词,大家可以下载了之后,去除该文本中的停用词。

对每个词编码之后,每句影评中的每个词就可以用对应的编码表示,即每条影评已经转变成一个向量了:

3.让每句数字影评长度相同
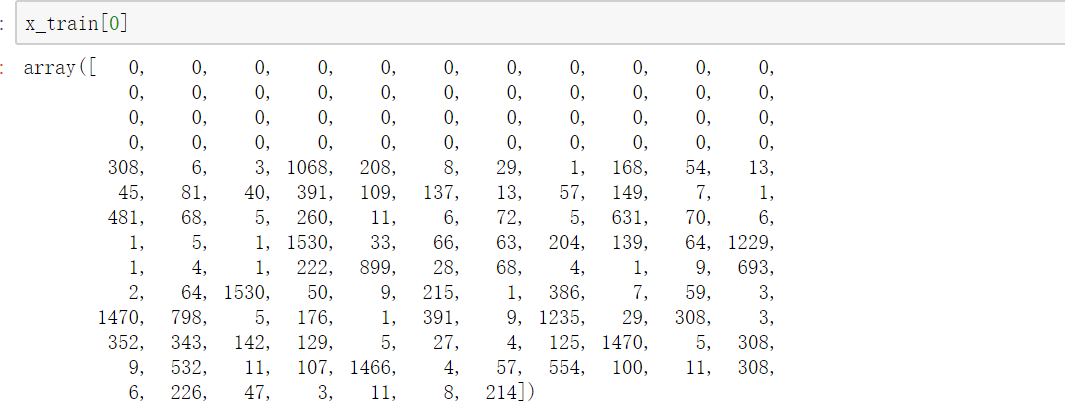
对每个词编码之后,每句影评中的每个词就可以用对应的编码表示,即每条影评已经转变成一个向量。但是,由于影评的长度不唯一,需要将每条影评的长度设置一个固定值。

每个句子的长度都固定为150,如果长度大于150,则将超过的部分截掉;如果小于150,则在最前面用0填充。每个句子如下:
4.使用Embedding层将每个词编码转换为词向量
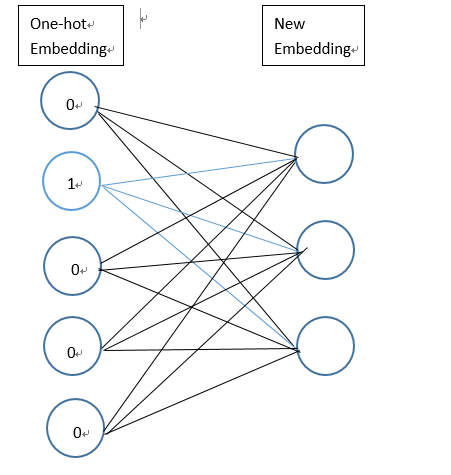
通过以上操作,已经将每个句子变成一个向量,但上文已经提及text-CNN的输入是一个数字矩阵,即每个影评样本应该是以一个矩阵,每一行代表一个词,因此,需要将词编码转换成词向量。使用Keras的Embedding层可以实现转换。Embedding层基于上文所得的词编码,对每个词进行one-hot编码,每个词都会以一个vocabulary_size(如上文的2000)维的向量;然后通过神经网络的训练迭代更新得到一个合适的权重矩阵(具体实现过程可以参考skip-gram模型),行大小为vocabulary_size,列大小为词向量的维度,将本来以one-hot编码的词向量映射到低维空间,得到低维词向量。比如the的编号为1,则对应的词向量为权重矩阵的第一行向量。如下图,蓝色线对应权重值组成了该词的词向量。需要声明一点的是Embedding层是作为模型的第一层,在训练模型的同时,得到该语料库的词向量。当然,也可以使用已经预训练好的词向量表示现有语料库中的词。
至此已经将文本数据预处理完毕,将每个影评样本转换为一个数字矩阵,矩阵的每一行表示一个词向量。下图梳理了处理文本数据的一般步骤。在此基础上,可以针对相应数据集的特点对数据集进行特定的处理。比如:在该数据集中影评可能含有一些html标签,我们可以使用正则表达式将这些标签去除。
下一篇文章,我们将介绍text-CNN模型,利用该模型对imdb数据集进行情感分析,并在文末给出整个项目的完整代码链接。欢迎持续关注!
本篇文章出自http://www.tensorflownews.com,对深度学习感兴趣,热爱Tensorflow的小伙伴,欢迎关注我们的网站!
使用Keras进行深度学习:(三)使用text-CNN处理自然语言(上)的更多相关文章
- 使用Keras进行深度学习:(七)GRU讲解及实践
####欢迎大家关注我们的网站和系列教程:http://www.tensorflownews.com/,学习更多的机器学习.深度学习的知识! 介绍 GRU(Gated Recurrent Unit) ...
- [ZZ] 深度学习三巨头之一来清华演讲了,你只需要知道这7点
深度学习三巨头之一来清华演讲了,你只需要知道这7点 http://wemedia.ifeng.com/10939074/wemedia.shtml Yann LeCun还提到了一项FAIR开发的,用于 ...
- 基于 Keras 用深度学习预测时间序列
目录 基于 Keras 用深度学习预测时间序列 问题描述 多层感知机回归 多层感知机回归结合"窗口法" 改进方向 扩展阅读 本文主要参考了 Jason Brownlee 的博文 T ...
- 使用Keras进行深度学习:(二)CNN讲解及实践
欢迎大家关注我们的网站和系列教程:http://www.tensorflownews.com/,学习更多的机器学习.深度学习的知识! 现今最主流的处理图像数据的技术当属深度神经网络了,尤其是卷积神经网 ...
- 深度学习之卷积神经网络CNN及tensorflow代码实例
深度学习之卷积神经网络CNN及tensorflow代码实例 什么是卷积? 卷积的定义 从数学上讲,卷积就是一种运算,是我们学习高等数学之后,新接触的一种运算,因为涉及到积分.级数,所以看起来觉得很复杂 ...
- 深度学习(一)——CNN算法流程
深度学习(一)——CNN(卷积神经网络)算法流程 参考:http://dataunion.org/11692.html 0 引言 20世纪60年代,Hubel和Wiesel在研究猫脑皮层中用于局部敏感 ...
- 深度学习之卷积神经网络CNN及tensorflow代码实现示例
深度学习之卷积神经网络CNN及tensorflow代码实现示例 2017年05月01日 13:28:21 cxmscb 阅读数 151413更多 分类专栏: 机器学习 深度学习 机器学习 版权声明 ...
- [AI开发]centOS7.5上基于keras/tensorflow深度学习环境搭建
这篇文章详细介绍在centOS7.5上搭建基于keras/tensorflow的深度学习环境,该环境可用于实际生产.本人现在非常熟练linux(Ubuntu/centOS/openSUSE).wind ...
- 分别基于TensorFlow、PyTorch、Keras的深度学习动手练习项目
×下面资源个人全都跑了一遍,不会出现仅是字符而无法运行的状况,运行环境: Geoffrey Hinton在多次访谈中讲到深度学习研究人员不要仅仅只停留在理论上,要多编程.个人在学习中也体会到单单的看理 ...
随机推荐
- java.lang.SecurityException: class "javax.servlet.AsyncContext"'s signer information does not match signer information of other classes in the same package
最近在写个Http协议的压测挡板时,遇到以下错误. 2018-03-08 10:34:07.808:INFO:oejs.Server:jetty-8.1.9.v20130131 2018-03-08 ...
- 树莓派3B安装OpenWrt打造超级路由器
网上有很多树莓派安装OpenWrt的教程,我这里写一下个人安装体验以及踩过的坑
- 利用短信通知的方式在Tasker中实现收到Android手机短信自动转发到邮箱
利用短信的通知实现短信内容转发到微信 code[class*="language-"] { padding: .1em; border-radius: .3em; white-sp ...
- ES6的函数
1,带参数默认值的函数 JS函数有个独特的行为:可以接受任意数量的参数,而无视函数声明的形参数量.未提供的参数会使用默认值来代替.实际传递的参数允许少于或多于正式指定的参数. 在ES6中可以直接在形参 ...
- CMAKE交叉编译快速入门
cmake 工具 cmake 使用非常简单,最常用的用法是 cmake . 在当前目录执行cmake 官方帮助 -D <var>:<type>=<value> -D ...
- linux-TFTP服务
1.TFTP协议简介TFTP,全称是 Trivial File Transfer Protocol(简单文件传输协议),基于 UDP 实现,该协议简单到只能从远程服务器读取数据或向远程服务器上传数据. ...
- Python装饰器及内置函数
装饰器 听名字应该知道这是一个装饰的东西,我们今天就来讲解一下装饰器,有的铁子们应该听说,有的没有听说过.没有关系我告诉你们这是一个很神奇的东西 这个有多神奇呢? 我们先来复习一下闭包 def fun ...
- (转)GNU风格ARM汇编语法指南(非常详细)3
原文地址:http://zqwt.012.blog.163.com/blog/static/120446842010111482023804/ 3.GNU汇编程序中的分段 <1> . ...
- 第3章 C++中的C
用union节省内存 使用场合:有时一个程序会使用同一个变量处理不同的数据类型,对于这种情况,有两种选择:可以创建一个struct,其中包含所有可能的不同类型的数据:也可以使用联合union,它能把所 ...
- Canvas方法总结
渲染上下文 getContext() // 获得渲染上下文和它的绘画功能 绘制形状 绘制矩形 fillRect(x, y, width, height) // 绘制一个填充的矩形 strokeRect ...