使用条件随机场模型解决文本分类问题(附Python代码)
对深度学习感兴趣,热爱Tensorflow的小伙伴,欢迎关注我们的网站!http://www.tensorflownews.com。我们的公众号:磐创AI。
一. 介绍
世界上每天都在生成数量惊人的文本数据。Google每秒处理超过40,000次搜索,而根据福布斯报道,每一分钟我们都会发送1600万条短信,并在Facebook上发布510,00条评论。那么一个外行人来说,是否真的很难处理如此庞大的数据量?

仅新闻网站和其他在线媒体每小时就会产生大量的文本内容。如果没有合适的工具,分析文本数据的模式则是令人生畏的。今天我们将讨论一种对文本进行实体识别的方法,称为条件随机场(CRF)。
本文通过自己注释一个数据集来解释条件随机场概念,并给出一个python的实现。这是一个非常有趣的概念,相信你会享受理解它的过程!
目录
- 什么是实体识别?
- 案例研究目标和理解不同的方法
- 公式化条件随机场(CRF)
- 使用GATE对文本数据进行打标注释
- 用Python构建和训练CRF模块
二. 什么是实体识别?
随着对自然语言处理(NLP)受到更多的关注,实体识别最近也变得越发流行。我们通常可以将实体定义为文本中数据科学家更感兴趣的一部分。一些被经常提取的实体示例是人名,地址,帐号,位置等。这些只是简单的示例,我们可以针对自己手动特定的问题定义自己的实体。
举一个采用实体识别的简单应用:如果数据集中存在任何带有“伦敦”的文本,算法会自动将这段文本归类或分类为一个位置。
让我们以一个简单的案例研究来更好地理解我们的主题。
三. 案例研究目标和理解不同的方法
假设你是保险公司分析团队的一员,每天索赔团队会收到客户关于其索赔的数千封电子邮件。索赔运营团队会检查每封电子邮件,并在处理这些电子邮件之前使用邮件中的详细信息来更新线上表单。
系统会要求您与IT团队合作,自动完成预填充在线表单的过程。对于这个任务,分析团队需要实现自定义实体识别算法。
要识别文本中的实体,必须能够识别它的模式。例如,如果我们要识别索赔号,我们可以查看它周围的单词,例如“我的ID是”或“我的号码是”等。下面提到的几种方法都可以用来来识别模式。
- 正则表达式:正则表达式(RegEx)是有限状态自动机的一种形式。它非常有助于识别遵循特定结构的模式。例如,可以使用RegEx很好地识别电子邮件ID,电话号码等。然而,这种方法的缺点是需要知道在索赔号之前出现的所有可能的确切词。这不是一种自学习的方法,而是一种蛮力的方法
- 隐马尔可夫模型(HMM):这是一种识别和学习模式的序列建模算法。尽管HMM考虑了通过观察估计实体周围的未来状态来学习它的模式,但它假设这些特征彼此独立。这种方法比正则表达式更好,因为我们不需要对确切的单词集进行建模。但就性能而言,它并非实体识别的最佳方法
- MaxEnt Markov模型(MEMM):这也是一种序列建模算法。这并不假设特征彼此独立,也不考虑观察未来状态来学习模式。在性能方面,它也并非实体识别的最佳方法
- 条件随机场(CRF):这也是一种序列建模算法。这不仅假设特征相互依赖,而且在学习模式时也考虑未来的观察。这结合了HMM和MEMM的优点。在性能方面,它被认为是解决实体识别问题的最佳方法
四. 条件随机场的公式表达
单词包(BoW)方法适用于多文本分类问题。这种方法假定单词的存在或不存在比单词的顺序更重要。然而,在诸如实体识别,词性识别之类的问题中,单词序列则显得更重要。条件随机场(CRF)在这时候就可以发挥作用了,因为它使用到了单词序列而不仅仅是单词。
现在让我们了解下CRF的公式表达。
下面是CRF的公式,其中Y是隐藏状态(例如词性),X是观察到的变量(在我们的示例中,就是实体单词或其周围的其他单词)。
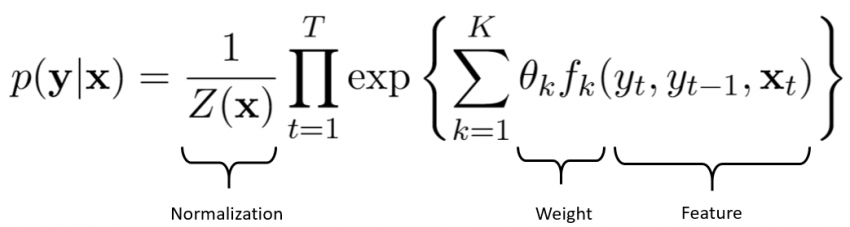
从广义上讲,CRF公式有两个组成部分:
归一化:你可能已经观察到在我们具有权重和特征的等式的右侧没有概率。但是左边是概率,因此需要归一化。归一化常数Z(x)是所有可能的状态序列的总和,使得总和为1。你可以在本文的参考部分中找到更多详细信息,以了解我们如何得到这个值。
权重和特征:这部分可以被视为具有权重和相应特征的逻辑回归公式。通过最大似然估计来进行权重估计,并由我们自己定义特征。
五. 注释训练数据
现在您已了解CRF模型,让我们着手准备训练数据。这样做的第一步是注释。注释是使用相应的实体标记标记单词的过程。为简单起见,我们假设我们只需要2个实体来填充在线表格,即索赔人姓名和索赔号。
以下是按原样收到的示例电子邮件。需要对这些电子邮件进行注释,以便可以训练CRF模型。带注释的文本需要采用XML格式。虽然您可以选择以您的方式注释文档,但我将引导您使用GATE这个提供文本基础服务的软件来执行这个操作。
收到的电邮:
“Hi,
I am writing thisemail to claim my insurance amount. My id is abc123 and I claimed iton 1st January 2018. I did not receive any acknowledgement. Please help.
Thanks,
randomperson”
带注释的电子邮件:
“<document>Hi, Iam writing this email to claim my insurance amount. My idis <claim_number>abc123</claim_number> and I claimed on1st January 2018. I did not receive any acknowledgement. Please help.Thanks, <claimant>randomperson</claimant></document>”
使用GATE的注释功能:
让我们了解如何使用文本工程通用架构(GATE)。请按照以下步骤安装GATE。
从以下链接下载最新版本:
https://gate.ac.uk/download/#latest
通过执行下载的安装程序按安装步骤安装GATE平台。
安装后,运行应用程序可执行文件。应用程序打开后,右键单击“LanguageResources”>New>GATE Document,将电子邮件迭代加载到语言资源中。给每个电子邮件命名,将编码设置为“utf-8”,这样就没有Python方面的问题,通过单击sourceUrl部分的图标导航到需要注释的电子邮件。
一次打开一封电子邮件并开始注释练习。构建注释有两种方法。
A. 将注释好的xml加载到GATE并使用它
B. 在GATE中即时创建注释并使用它们。在本文中,我们将演示这种方法。
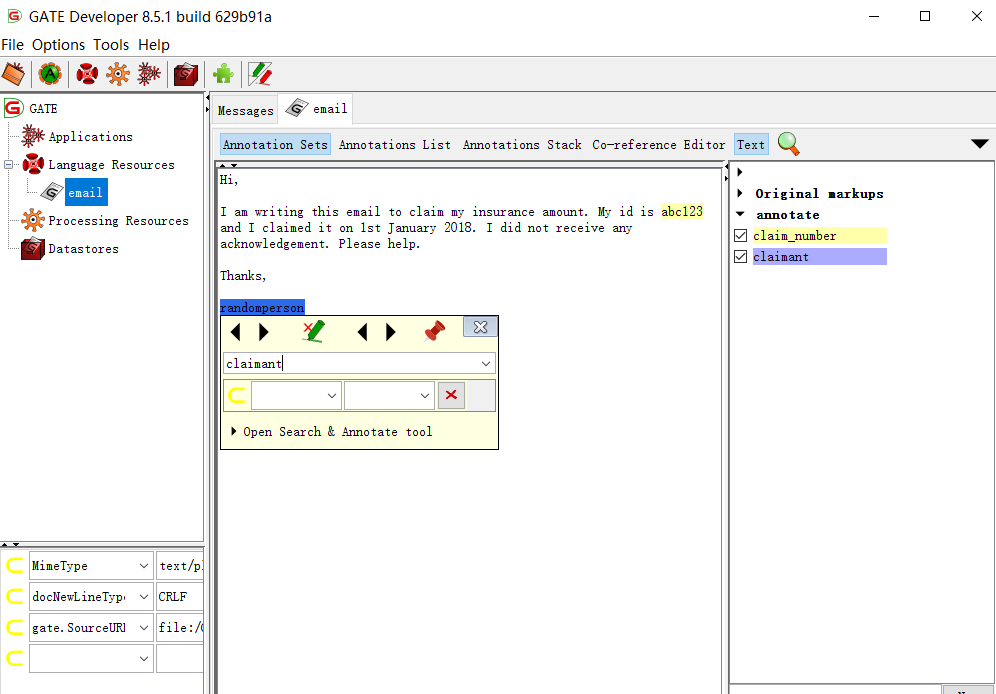
单击“LanguageResources”部分中的电子邮件打开它。单击“Annotation Sets”,然后选择单词或单词并将光标放在其上几秒钟就会出现注释的弹出窗口,然后您可以输入注释代替“_NEW_”并按Enter键,这将创建一个新注释,如下所示。对每封电子邮件的所有注释重复这个操作。
一旦所有要训练的电子邮件都被注释,通过导航到Language Resources> NEW> GATE Corpus创建易于使用的语料库。
通过右键单击语料库并导航到“InlineXML(.xml)”,将语料库保存到你电脑上的文件夹里。
在下一个弹出窗口中,选择预先填充的注释类型并将其删除。手动键入注释并添加它们以代替预先填充的注释。通过单击将“includeFeatures”选项设置为false,然后在rootElement框中键入“document”。完成所有这些更改后,单击“save as”图标将文件保存到计算机上的文件夹中。

由GATE生成好的注释邮件
重复上述过程将所有带注释的电子邮件保存在一个文件夹中。
六. 用Python构建和训练CRF模块
首先下载pycrf模块。对于PIP安装,命令是“ pip install python-crfsuite ”,对于conda安装,命令是“ conda install -cconda-forge python-crfsuite ”。
安装完成后,您就可以开始训练和构建自己的CRF模块了。好,咱们开工吧!
#导入需要的工具包
from bs4 import BeautifulSoup as bs
from bs4.element import Tag
import codecs
import nltk
from nltk import word_tokenize, pos_tag
from sklearn.model_selection import train_test_split
import pycrfsuite
import os, os.path, sys
import glob
from xml.etree import ElementTree
import numpy as np
from sklearn.metrics import classification_report让我们再定义一些函数。
# 获得所有邮件添加到一个列表中
def append_annotations(files):
xml_files = glob.glob(files+"/*.xml")
xml_element_tree = None
new_data = ""
for xml_file in xml_files:
data =ElementTree.parse(xml_file).getroot()
#printElementTree.tostring(data)
temp =ElementTree.tostring(data)
new_data += (temp)
return(new_data)
# 该函数移除文本中的特殊符号
def remov_punct(withpunct):
punctuations ='''!()-[]{};:'"\,<>./?@#$%^&*_~'''
without_punct = ""
char = 'nan'
for char in withpunct:
if char not inpunctuations:
without_punct =without_punct + char
return(without_punct)
# 该函数将从每条邮件文本中提取我们想要的特征
def extract_features(doc):
return [word2features(doc, i)for i in range(len(doc))]
def get_labels(doc):
return [label for (token,postag, label) in doc]接着我们导入注释好的训练数据。
files_path = "./Annotated"
allxmlfiles = append_annotations(files_path)
soup = bs(allxmlfiles, "html5lib")
#对带注释的单词进行标记
docs = []
for d in soup.find_all("document"):
sents = []
for wrd in d.contents:
tags = []
NoneType = type(None)
if isinstance(wrd.name,NoneType) == True:
withoutpunct =remov_punct(wrd)
temp =word_tokenize(withoutpunct)
for token in temp:
tags.append((token,'NA'))
else:
withoutpunct =remov_punct(wrd)
temp =word_tokenize(withoutpunct)
for token in temp:
tags.append((token,wrd.name))
sents = sents + tags
docs.append(sents)下面这部分代码的功能是生成特征,这些特征是使用nltk工具包生成的,作为命名实体识别算法的输入,你也可以用其他特定工具生成特征。(例如在中文语料上可以用HanLP,FNLP等工具生成特征)。
data = []
for i, doc in enumerate(docs):
tokens = [t for t, label indoc]
tagged =nltk.pos_tag(tokens)
data.append([(w, pos, label)for (w, label), (word, pos) in zip(doc, tagged)])
def word2features(doc, i):
word = doc[i][0]
postag = doc[i][1]
# 这里添加的特征都是适用于所有单词的通用特征,你可以根据自己的需求在这里添加更多的特征。
features = [
'bias',
'word.lower=' +word.lower(),
'word[-3:]=' +word[-3:],
'word[-2:]=' +word[-2:],
'word.isupper=%s' %word.isupper(),
'word.istitle=%s' %word.istitle(),
'word.isdigit=%s' %word.isdigit(),
'postag=' + postag
]
#若单词不在结尾处
if i > 0:
word1 = doc[i-1][0]
postag1 = doc[i-1][1]
features.extend([
'-1:word.lower=' +word1.lower(),
'-1:word.istitle=%s' %word1.istitle(),
'-1:word.isupper=%s' %word1.isupper(),
'-1:word.isdigit=%s' %word1.isdigit(),
'-1:postag=' + postag1
])
else:
# 注明该单词位于文本开头
features.append('BOS')
# 若单词不在结尾处
if i < len(doc)-1:
word1 = doc[i+1][0]
postag1 = doc[i+1][1]
features.extend([
'+1:word.lower=' +word1.lower(),
'+1:word.istitle=%s' %word1.istitle(),
'+1:word.isupper=%s' %word1.isupper(),
'+1:word.isdigit=%s' %word1.isdigit(),
'+1:postag=' + postag1
])
else:
# 注明该单词位于文本结尾
features.append('EOS')
return features
#提取出特征和标签,并划分为测试数据和训练数据。
X = [extract_features(doc) for doc in data]
y = [get_labels(doc) for doc in data]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# 加载模型测试一下
tagger = pycrfsuite.Tagger()
tagger.open('crf.model')
y_pred = [tagger.tag(xseq) for xseq in X_test]
# 通过选择行标来查看预测值
i = 0
for x, y in zip(y_pred[i], [x[1].split("=")[1] for x inX_test[i]]):
print("%s (%s)" % (y, x))
# 创建一个标签的索引
labels = {"claim_number": 1, "claimant":1,"NA": 0}
# 将预测出来的标签序列转化为一维ndarray
predictions = np.array([labels[tag] for row in y_pred for tag in row])
truths = np.array([labels[tag] for row in y_test for tag in row])
# 打印分类报告
print(classification_report(
truths, predictions,
target_names=["claim_number","claimant","NA"]))到目前为止,你已经了解如何注释训练数据,如何使用Python训练CRF模型,以及最后如何从文本中识别实体。虽然此算法提供了一些基本功能,但你也可以提出自己的一组功能来提高模型的准确性。
对深度学习感兴趣,热爱Tensorflow的小伙伴,欢迎关注我们的网站!http://www.tensorflownews.com。我们的公众号:磐创AI。
使用条件随机场模型解决文本分类问题(附Python代码)的更多相关文章
- NLP大赛冠军总结:300万知乎多标签文本分类任务(附深度学习源码)
NLP大赛冠军总结:300万知乎多标签文本分类任务(附深度学习源码) 七月,酷暑难耐,认识的几位同学参加知乎看山杯,均取得不错的排名.当时天池AI医疗大赛初赛结束,官方正在为复赛进行平台调 ...
- 使用scikit-learn解决文本多分类问题(附python演练)
来源 | TowardsDataScience 译者 | Revolver 在我们的商业世界中,存在着许多需要对文本进行分类的情况.例如,新闻报道通常按主题进行组织; 内容或产品通常需要按类别打上标签 ...
- 百度EasyDL文本分类自定义API示例代码 python
因为需要将命名实体中的组织机构名进一步区分为政府.企业.社会组织等,在easydl上做了一个文本分类模型,但是要用这个接口时候发现, 官方文档中竟然还在用urllib2的库,且不完整.好多地方会报错, ...
- 一文详解如何用 TensorFlow 实现基于 LSTM 的文本分类(附源码)
雷锋网按:本文作者陆池,原文载于作者个人博客,雷锋网已获授权. 引言 学习一段时间的tensor flow之后,想找个项目试试手,然后想起了之前在看Theano教程中的一个文本分类的实例,这个星期就用 ...
- KNN分类算法及python代码实现
KNN分类算法(先验数据中就有类别之分,未知的数据会被归类为之前类别中的某一类!) 1.KNN介绍 K最近邻(k-Nearest Neighbor,KNN)分类算法是最简单的机器学习算法. 机器学习, ...
- 决策树分类算法及python代码实现案例
决策树分类算法 1.概述 决策树(decision tree)——是一种被广泛使用的分类算法. 相比贝叶斯算法,决策树的优势在于构造过程不需要任何领域知识或参数设置 在实际应用中,对于探测式的知识发现 ...
- 医学图像 | 使用深度学习实现乳腺癌分类(附python演练)
乳腺癌是全球第二常见的女性癌症.2012年,它占所有新癌症病例的12%,占所有女性癌症病例的25%. 当乳腺细胞生长失控时,乳腺癌就开始了.这些细胞通常形成一个肿瘤,通常可以在x光片上直接看到或感觉到 ...
- 条件随机场(conditional random field,CRF)模型初探
0. 引言 0x1:为什么会有条件随机场?它解决了什么问题? 在开始学习CRF条件随机场之前,我们需要先了解一下这个算法的来龙去脉,它是在什么情况下被提出的,是从哪个算法演进而来的,它又解决了哪些问题 ...
- NLP学习(2)----文本分类模型
实战:https://github.com/jiangxinyang227/NLP-Project 一.简介: 1.传统的文本分类方法:[人工特征工程+浅层分类模型] (1)文本预处理: ①(中文) ...
随机推荐
- 配置github——每次提交后使contributions有记录(有小绿格子)
# 配置github--每次提交后使contributions有记录(有小绿格子) 这几天都有将自己的代码提交到github上,但是在profile里的contributions的表格中没有我提交的记 ...
- sql03
1.约束 约束详解 ->约束的目的:保证数据的完整性. not null ->默认值约束.可空约束.主键约束.外键约束.唯一键约束.检查约束 1) 用sql语句为表添加新的字段 2) 为字 ...
- Markdown 语法简要规则
Markdown简介 Markdown 是一种轻量级的「标记语言」,它的优点很多,目前也被越来越多的写作爱好者,撰稿者广泛使用.看到这里请不要被「标记」.「语言」所迷惑,Markdown 的语法十分简 ...
- ionic监听android返回键(实现“再按一次退出”功能)
在android平台上的app,在主页面时经常会遇到"再按一次退出app"的功能,避免只按一下返回键就退出app提升体验优化. 1.这个功能需要我们用到ionic提供的regist ...
- HTML5历史管理状态机制
前言:想要不刷新页面同时改变url 可以用HTML5 window对象的 hashChange 事件.同时介绍两个相关的api 和 1个事件. 两个API:1.history.pushState({n ...
- intel硬件视频加速介绍
目录 硬件视频加速技术 intel 硬件加速技术 intel 的开源媒体栈 VA-API 安装 样例 Intel Quick Sync(QSV) API支持情况 vaapi/mfx比较 安装 样例 硬 ...
- Hibernage错误:Could not open Hibernate Session for transaction
今天客户发来的错误,是SSH框架做的项目,是用户在登陆时候出现的错误,但刷新之后就没问题. 提示错误:Could not open Hibernate Session for transaction. ...
- 小程序Echarts 构建中国地图并锚定区域点击事件
小程序Echarts 构建中国地图并锚定区域点击事件 Step1 效果展示 使用的绘图框架为 Echarts for Wexin 具体API文档地址请点击 ----> Step2 条件准备 1. ...
- 02 JPA
JPA概述 JPA的全称是Java Persistence API, 即Java 持久化API,是SUN公司推出的一套基于ORM的规范,内部是由一系列的接口和抽象类构成. JPA通过JDK ...
- 【PG】Greenplum-db-6.2.1的安装部署
目录 1配置host文件(所有节点) 2 配置用户 3 配置/etc/sysctl.conf文件 4 limit文件,后面添加[不影响安装] 5 安装greenplum-db-6.2.1-rhel7- ...