golang版并发爬虫
准备爬取内涵段子的几则笑话,先查看网址:http://www.budejie.com/text/
简单分析后发现每页的url呈加1趋势
第一页: http://www.budejie.com/text/1
第二页:http://www.budejie.com/text/2
...
每页的段子:
<a href="/detail-28278217.html"> 内容</a>
<a href="/detail-28270675.html"> 内容</a>
....
所以正则表达式的解释规则是<a href="/detail-\d{8}.html">(?s:(.*?))</a>,第一个分组的内容就是需要的文字。
代码如下:
package main
import (
"fmt"
"regexp"
"strconv"
"net/http"
"log"
"os"
"strings"
) func onespider(n int, ch chan int) {
url := "http://www.budejie.com/text/" + strconv.Itoa(n)
resp, err := http.Get(url)
if err != nil {
log.Fatal("get error")
}
defer resp.Body.Close()
reg, err1 := regexp.Compile(`<a href="/detail-\d{8}.html">(?s:(.*?))</a>`)
if err1 != nil {
log.Fatal("compile error")
}
var respstring string
buf := make([]byte, )
for {
n, _ := resp.Body.Read(buf)
if n == {
break
}
respstring += string(buf[:n])
} cont := reg.FindAllStringSubmatch(respstring, -)
file, _ := os.OpenFile("./爬虫/"+"第"+strconv.Itoa(n)+"页爬虫.txt", os.O_RDWR|os.O_TRUNC|os.O_CREATE, )
defer file.CLose()
var i int
for _, value := range cont {
if len(value[]) < {
continue
}
value[] = strings.Replace(value[], "<br />", "\n", -)
index := strconv.Itoa(i+)
file.Write([]byte("第"+index+"则段:\n"+value[]+"\n\n\n"))
i++
}
ch <- n
}
func Spider(s, e int) {
ch := make(chan int)
for i := s; i <= e; i++ {
go onespider(i, ch)
}
for i := s; i <= e; i++ {
n := <- ch
fmt.Printf("第%d页爬取完毕\n", n)
}
}
func main(){
var start, end int
fmt.Println("输入起始页")
fmt.Scan(&start)
fmt.Println("输入终止页")
fmt.Scan(&end)
Spider(start, end)
}
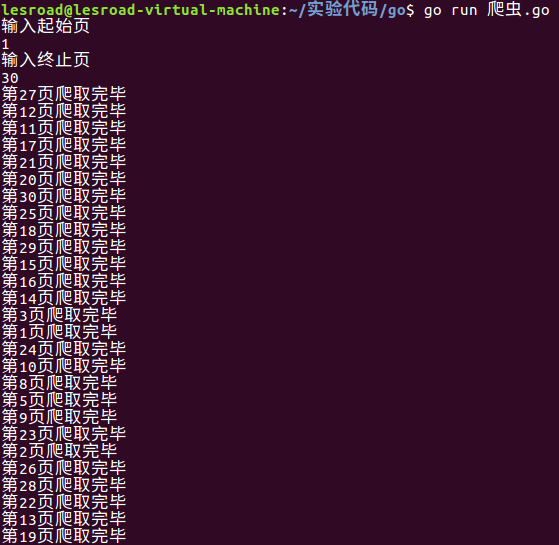
运行截图:
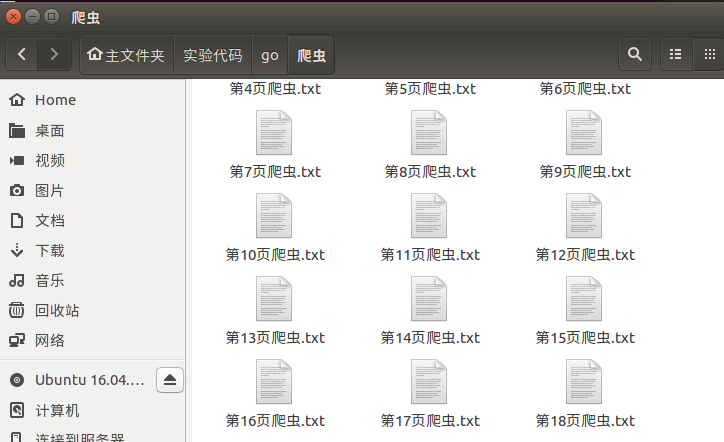
效果截图:
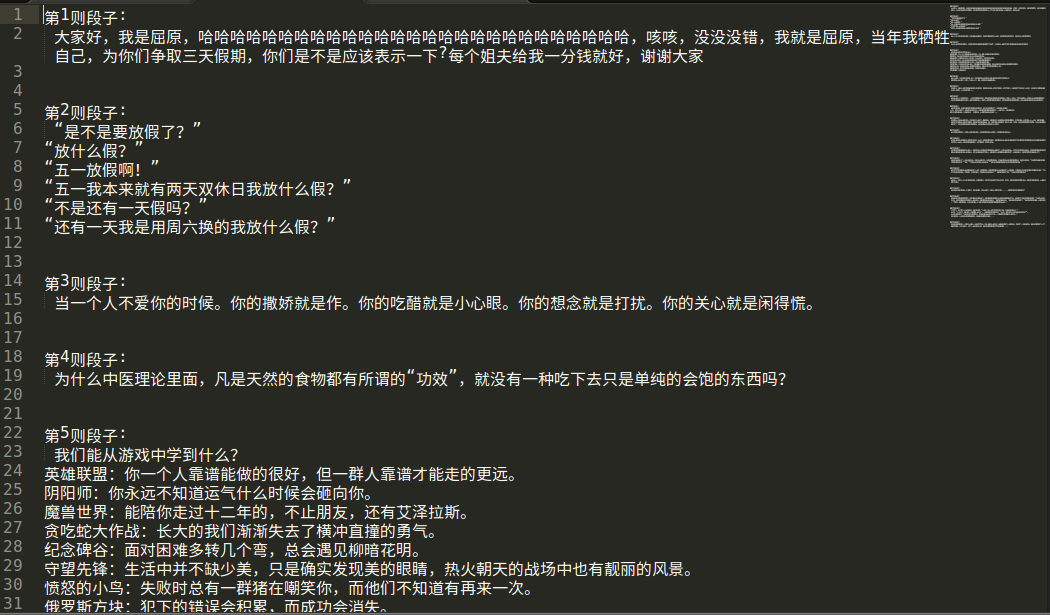
最后我发现第2页之后的段子都是重复的。。。
golang版并发爬虫的更多相关文章
- golang实现并发爬虫三(用队列调度器实现)
欲看此文,必先可先看: golang实现并发爬虫一(单任务版本爬虫功能) gollang实现并发爬虫二(简单调度器) 上文中的用简单的调度器实现了并发爬虫. 并且,也提到了这种并发爬虫的实现可以提高爬 ...
- golang实现并发爬虫一(单任务版本爬虫功能)
目的是写一个golang并发爬虫版本的演化过程. 那么在演化之前,当然是先跑通一下单任务版本的架构. 正如人走路之前是一定要学会爬走一般. 首先看一下单任务版本的爬虫架构,如下: 这是单任务版本爬虫的 ...
- golang实现并发爬虫二(简单调度器)
上篇文章当中实现了单任务版爬虫. 那么这篇文章就大概说下,如何在上一个版本中进行升级改造,使之成为一个多任务版本的爬虫.加快我们爬取的速度. 话不多说,先看图: 其实呢,实现方法就是加了一个sched ...
- golang的并发
Golang的并发涉及二个概念: goroutine channel goroutine由关键字go创建. channel由关键字chan定义 channel的理解稍难点, 最简单地, 你把它当成Un ...
- Golang版protobuf编译
官方网址: https://developers.google.com/protocol-buffers/ (需要FQ) 代码仓库: https://github.com/google/protobu ...
- golang的并发不等于并行
先 看下面一道面试题: func main() { runtime.GOMAXPROCS(1) wg := sync.WaitGroup{} wg.Add(20) for i := 0; i < ...
- [Golang] kafka集群搭建和golang版生产者和消费者
一.kafka集群搭建 至于kafka是什么我都不多做介绍了,网上写的已经非常详尽了. 1. 下载zookeeper https://zookeeper.apache.org/releases.ht ...
- Go语言之进阶篇简单版并发服务器
1.简单版并发服务器 示例1: package main import ( "fmt" "net" "strings" ) //处理用户请求 ...
- swing版网络爬虫-丑牛迷你采集器2.0
swing版网络爬虫-丑牛迷你采集器2.0 http://www.javacoo.com/code/704.jhtml 整合JEECMS http://bbs.jeecms.com/fabu/3186 ...
随机推荐
- webpack.dev.conf.js详解
转载自:https://www.cnblogs.com/ye-hcj/p/7087205.html webpack.dev.conf.js详解 //引入当前目录下的utils.js文件模块var ut ...
- Apple 的命令行交付工具“Transporter”
Apple 的命令行交付工具“Transporter” 占坑... https://help.apple.com/itc/transporteruserguide/#/apdATD1E1026-D1E ...
- REST API Design
- docker使用Mesos
https://github.com/PyreneGitHub/mesos_use/tree/master
- 20145216史婧瑶《Java程序设计》第9周学习总结
20145216 <Java程序设计>第9周学习总结 教材学习内容总结 第十六章 整合数据库 16.1 JDBC入门 撰写应用程序是利用通信协议对数据库进行指令交换,以进行数据的增删查找. ...
- 通过Excel生成批量SQL语句
项目中有时会遇到这样的要求:用户给发过来一些数据,要我们直接给存放到数据库里面,有的是Insert,有的是Update等等,少量的数据我们可以采取最原始的办法,也就是在SQL里面用Insert int ...
- 解读:Hadoop序列化类
序列化(serialization)是指将结构化的对象转化字节流,以便在进程间通信或写入硬盘永久存储. 反序列化(deserialization)是指将字节流转回到结构化对象的过程. 需要注意的是,能 ...
- PHP爬取知乎日报图片显示不了问题
在爬取知乎日报的内容时,虽然能拿到图片的地址,在窗口中也能打开图片,但是在前端却显示不了,报403错误. 经查证,这是因为知乎对图片做了防盗链处理,其中一个解决方法是添加meta标签: <met ...
- Java 线程池Future和FutureTask
Future表示一个任务的周期,并提供了相应的方法来判断是否已经完成或者取消,以及获取任务的结果和取消任务. Future接口源码: public interface Future<V> ...
- 采用OpenReplicator解析MySQL binlog
Open Replicator是一个用Java编写的MySQL binlog分析程序.Open Replicator 首先连接到MySQL(就像一个普通的MySQL Slave一样),然后接收和分析b ...