hadoop知识整理(1)之HDFS
一、HDFS是一个分布式文件系统
体系架构: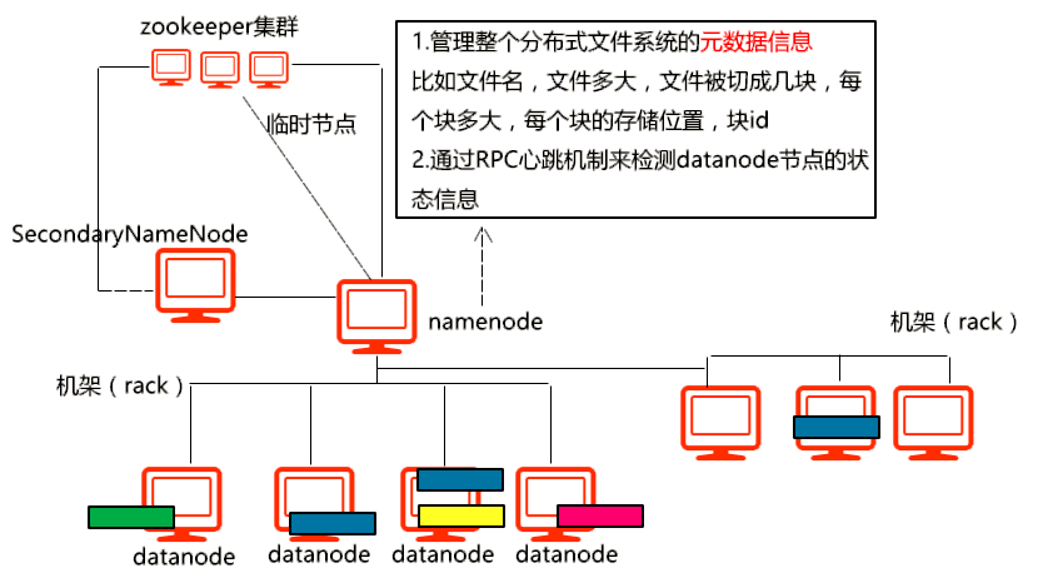
hdfs主要包含了3部分,namenode、datanode和secondaryNameNode
namenode主要作用和运行方式:
1)管理hdfs的元数据信息,文件名字,大小,切成几块,有几个副本,切成块和副本分别存储在datanode的位置,块id、大小;
2)通过rpc心跳机制,来检测datanode的运行状态;
3)简单说,元数据的存储信息都放在namenode之上,为了快速查取,所以内存中有一份,但是为了保证元数据信息不丢,所以磁盘还要存一份,元数据极其重要的,元数据如果丢失,那么hdfs就会丢失数据;
4)namenode持久化元数据位置在于core-site.xml中的dfs.tmp.dir属性决定,此参数不配置,默认元数据放在/tmp,所以建议配置此选项;
5)namenode通过两个文件来存储元数据的信息,edits文件和fsimage文件
其中,edits文件存储了,hdfs的所有操作记录
fsimage存储了hdfs当前的快照,简单说,edits中包含了hdfs的实时操作状态,而fsimage是旧时元数据状态,所以两个文件需要定期合并。
两个文件合并周期为默认1小时。
datanode主要作用:
1)存储文件块的服务器;
2)当hdfs启动时,每个datanode会向namenode汇报自身存储的信息,namenode收到所有datanodes的信息进行汇总和检测,检测数据的完整性和副本的完整性,如果检测出现问题,hdfs会进入安全模式,安全模式会做数据元复原,复原完成,安全模式自动推出。安全模式中,hdfs只对外提供读服务,不提供写服务。
3)hdfs默认每个存储的文件块大小为128M,举例,一个257M的文件,在不修改hdfs文件块参数的情况下,会在hdfs中存储为3个文件块,128+128+1M。
secondaryNameNode的主要作用:
1)是namenode的备用节点,当namenode主节点挂了之后,会立马顶上,这种主备HA方式是通过ZooKeeper实现的,简单讲就是在hdfs配置文件中配置ZK集群后,namenode主节点会在zk中创建临时节点,而secondaryNameNode会监控这个临时节点,当临时节点消失后,secondaryNameNode会从stardby转换为active从而做到主备HA。
2)在hadoop的1.0中,secondaryNameNode还有一个重要作用为异地进行edits和fsimage文件合并操作,然后发给namenode主节点进行更新。
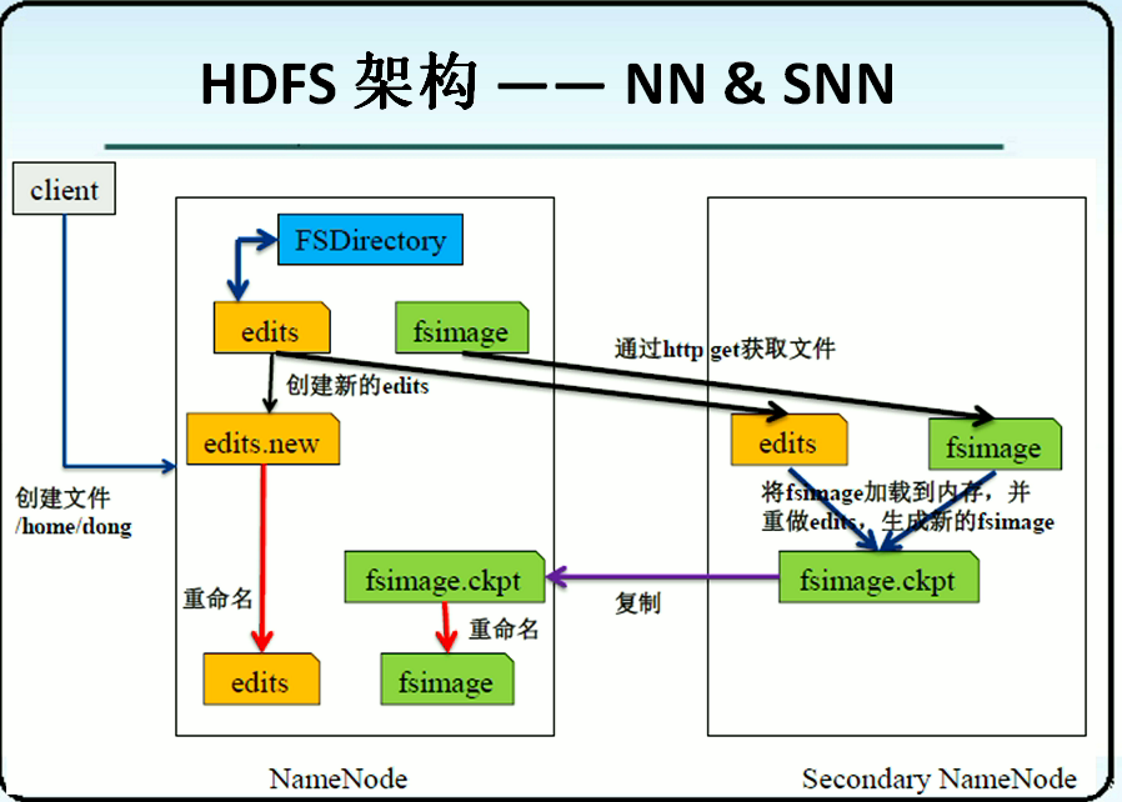
在这里补充一些hadoop2.0中高可用HA的实现:
首先需要搞明白为什么废除1.0的namenode的高可用,举一个示例:把检查点称为edits和fsimage合并的完成的时间点。当检查点后namenode挂了,那么secondaryNameNode成为active状态,但是在检查点之后的edits操作,只存储在namenode之中,那么将会全部丢失。会存在丢失数据元的情况,所以在2.0中引入一个日志架构:quorum journal manager,群体日志管理器,体现在2.0中为journalNode,简称JN节点,JN节点的数量一般为namenode数量*2+1,故一般为3,JN日志架构的设计与ZK有类似之处,需要满足过半性原则,下面详细说明一下。在此HA架构中,存在active的NN1节点和standby的SNN2节点,以及3个JN节点。SNN2节点和NN1节点存储着上一个检查点之后的数据,这时候有新的操作进来,除了NN1要记录在edits_new中,还需要将日志发送给JN节点,并且需要满足一半以上的JN节点确实记录下了操作日志,这时候假使NN1挂了,且即使恰好JN其中一个节点和NN1在一起也不怕,当SNN2成为active状态之后,会从JN节点中恢复日志操作,所以假使这时候,JN已经挂了一个,那么既然满足了过半性原则,SNN2也能把所有的元数据操作恢复回来。再假如,这时候连SNN2都挂了,那么,当启动额外的备用NN时,冷启动也是一个办法,至少datanode和JN可以恢复数据。
其中的关键点在于,JN在一个时间里,只允许一个NN向其中进行写数据。
二、关于Edits和Fsimage文件那点事
在看了上文之后,都知道在一定的时间,edits和fsimage文件会在每一个时间点或者hdfs启动时进行合并操作,默认合并的时间间隔是3600s,这个每次合并的时间点叫做检查点。
两个文件合并的条件有:1、启动或重启hdfs;2、达到检查点;3、手动合并:命令:hadoop dfsadmin -rollEdits
合并的操作会在secondaryNameNode节点进行。
下文会说一些关于edits和fsimage文件的基本解析和合并操作流程。
edits文件解析:
1)edits文件主要存储了hdfs的事务操作,如mkdir、put、mv等,每一个操作,都会分配一个事务id,然后写入到edits文件中;
2)当启动hdfs时,会生成edits文件;
3)每生成一个新的edits文件,会以begin log为开头,并且以end log结尾;其中存储着这个edits文件所以关于hdfs的事务操作;
4)edits_inprogress文件记录了目前正在进行的事务操作,有事务id进行命名;
5)当hdfs操作过多时,edits文件会变得过大。
fsimage文件解析:
1)文件的目录和数据元信息持久化地存在于fsimage文件中,hdfs每次启动时从fsimage文件中加载文件目录树;
2)fsimage是一个二进制文件,主要记录了:
文件地版本号、NN地命名空间ID、存储地文件数量、创建目录生成的时间戳、块生成的时间戳、文件路径、文件块的数量、上传时间、访问时间、块编号、切块大小、块的实际大小、块存储的DN节点信息、目录创建者、目录创建者的属组、目录的权限等。
edits文件和fsimage文件的合并流程:
1)首先由1.0的secondaryNameNode节点,2.0叫standby NameNode,都简称SNN节点,判断是否应该达到检查点,需要进行文件的合并操作;
2)SNN节点会直接合并两个文件,fsimage从本地NN中获得,而edits可以实时从JN节点拿下来,合并后,生成一个fsimage_ckpt文件,并且随之生成一个关于新fsimage的md5文件,然后将fsimage_ckpt覆盖原fsimage;
3)然后活跃的active NameNode节点收到SNN节点发来的fsimage_ckpt文件,也生成一个md5文件,在与SNN的md5文件进行核对,假如一致,就确定拿到了最新的fsimage文件,然后修改本地fsimage文件。
其中的重点在于由于由JN的存在,所以active namenode和standby namenode都相当于有最新的edits文件。
三、关于上传和下载文件的过程,以及部分源码刨析
下载:
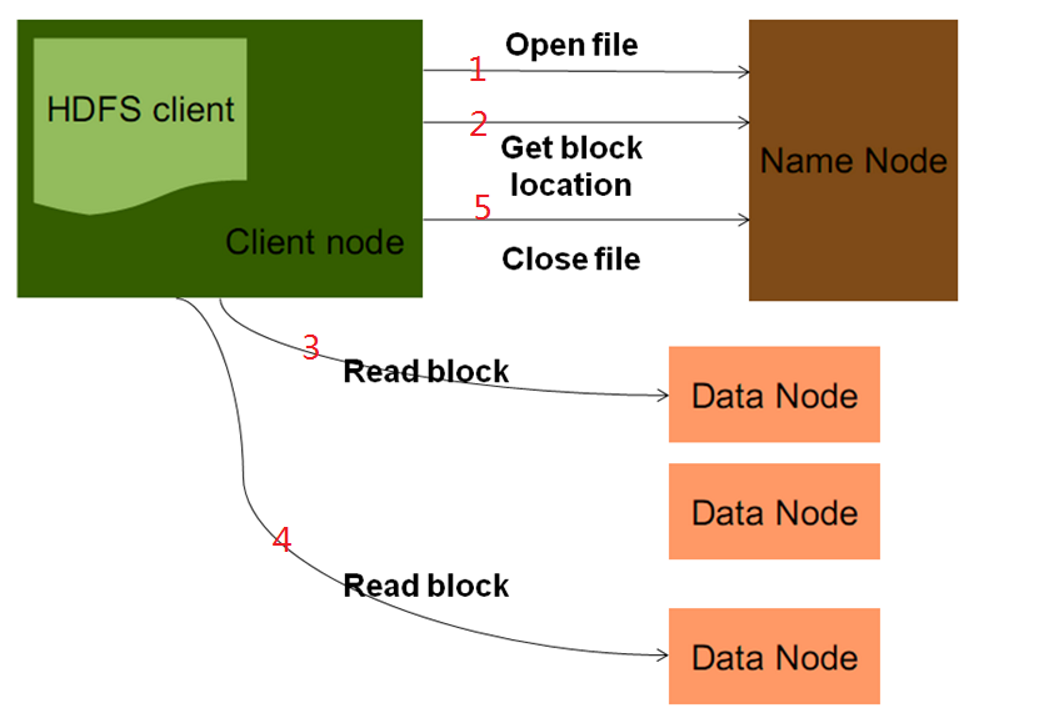
1)客户端向namenode发起open file,目的是获取需要下载的输入流;namenode收到请求之后,会检查路径的合法性,还有客户端的权限;
2)当客户端在发起open file请求之后,会调用getBlockLocation(获取文件块)。当nn检查通过后,将文件块存储信息封装到输入流,返回给客户端;
3)客户端收到了返回的输入流,根据其中的元数据块信息,去对应的datanode节点取文件数据,读取按照blockid的顺序进行读取,拼成一个完整文件,结束后关闭流等。
上传:
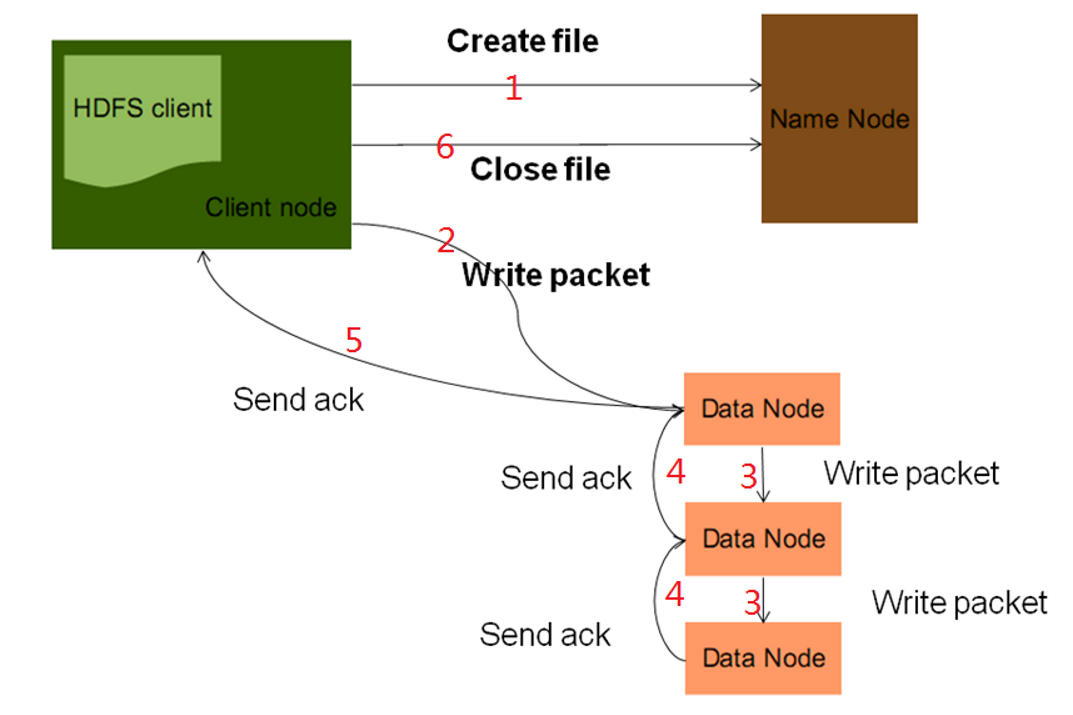
1)客户端发起create file,目的是获取nn的输出流,nn节点同样,收到请求后会检查路径以及权限合法性;
2)检测都通过后,nn会为这个文件分配数据块信息,然后将数据元信息放在输出流中,返回给客户端;
3)客户端拿到输出流,采用数据流管道机制做上传,pipeline,简单总结就是,文件被切割成packet发送给第一个dn节点,dn节点再将剩下的packet发给跟着的dn节点,然后底层的dn节点向上层dn节点做ack,最终客户端收到ack信息,上传结束,关闭输出流。
部分源码:
下载文件时,客户端获取NN的getBlockLocation
static LocatedBlocks callGetBlockLocations(ClientProtocol namenode,
String src, long start, long length)
throws IOException {
try {
return namenode.getBlockLocations(src, start, length);
} catch(RemoteException re) {
throw re.unwrapRemoteException(AccessControlException.class,
FileNotFoundException.class,
UnresolvedPathException.class);
}
}
注意,NN和客户端,DN和客户端之间的通信都为RPC。
当客户端向hdfs上传文件时,会启动2个队列和2个线程。
2个队列分别为,packet数据队列
private final LinkedList<Packet> dataQueue = new LinkedList<Packet>();
ack反馈队列
private final LinkedList<Packet> ackQueue = new LinkedList<Packet>();
2个线程,streamer线程,不停的从dataQueue中取出packet,发送给DN
private DataStreamer streamer = new DataStreamer();
response线程,不停地接收datanode的反馈信息:
private ResponseProcessor response = null;
数据传输过程:
1)文件数据以字节数组进行传输,封装成一个一个的packet,每个packet大小为64KB,扔进dataQueue中;
2)streamer不停从dataQueue中取出消息,通过socket发送给datanode,并且将未反馈信息放入ackQueue中;
3)然后response从blockReplySteam即DN反馈的信息中获取ack,再将原来ackQueue中未确认的消息清除。
hadoop知识整理(1)之HDFS的更多相关文章
- 转:hadoop知识整理
文章来自于:http://tianhailong.com/hadoop%E7%9F%A5%E8%AF%86%E6%95%B4%E7%90%86.html 按照what.how.why整理了下文章,帮助 ...
- hadoop知识整理(2)之MapReduce
之前写的关于MR的文章的前半部分已丢. 所以下面重点从3个部分来谈MR: 1)Job任务执行过程,以及主要进程-ResourceManager和NodeManager作用: 2)shuffle过程: ...
- hadoop知识整理(4)之zookeeper
一.介绍 一个分布式协调服务框架: 一个精简的文件系统,每个节点大小最好不大于1MB: 众多hadoop组件依赖于此,比如hdfs,kafka,hbase,storm等: 旨在,分布式应用中,提供一个 ...
- hadoop知识整理(3)之MapReduce之代码编写
前面2篇文章知道了HDFS的存储原理,知道了上传和下载文件的过程,同样也知晓了MR任务的执行过程,以及部分代码也已经看到,那么下一步就是程序员最关注的关于MR的业务代码(这里不说太简单的): 一.关于 ...
- hadoop知识整理(5)之kafka
一.简介 来自官网介绍: 翻译:kafka,是一个分布式的流处理平台.LinkedIn公司开发.scala语言编写. 1.支持流处理的发布订阅模式,类似一个消息队列系统: 2.多备份存储,副本冗余 ...
- 吴裕雄--天生自然HADOOP操作实验学习笔记:hdfs简单的shell命令
实验目的 了解bin/hadoop脚本的原理 学会使用fs shell脚本进行基本操作 学习使用hadoop shell进行简单的统计计算 实验原理 1.hadoop的shell脚本 当hadoop集 ...
- js事件(Event)知识整理
事件(Event)知识整理,本文由网上资料整理而来,需要的朋友可以参考下 鼠标事件 鼠标移动到目标元素上的那一刻,首先触发mouseover 之后如果光标继续在元素上移动,则不断触发mousemo ...
- Kali Linux渗透基础知识整理(四):维持访问
Kali Linux渗透基础知识整理系列文章回顾 维持访问 在获得了目标系统的访问权之后,攻击者需要进一步维持这一访问权限.使用木马程序.后门程序和rootkit来达到这一目的.维持访问是一种艺术形式 ...
- Kali Linux渗透基础知识整理(二)漏洞扫描
Kali Linux渗透基础知识整理系列文章回顾 漏洞扫描 网络流量 Nmap Hping3 Nessus whatweb DirBuster joomscan WPScan 网络流量 网络流量就是网 ...
随机推荐
- SAP Basis 客户端拷贝
一.版本.系统配置信息 软件 版本信息 操作系统 AIX 6.1 SAP ECC6.0 SAP_BASIS 7.00SP15kernel 720 600 oracle 11.2.0.2.0 DB大小 ...
- HTML5 Canvas绘图如何使用
--------------复制而来--原地址http://jingyan.baidu.com/article/ed15cb1b2e642a1be369813e.html HTML5 Canvas绘图 ...
- 谈谈C#中各种线程的使用及注意项~
说到线程,很多人会想到timer吧, 接下来我们就来学习一下 timer 吧,摇摇脑袋,清醒一下,接下来开始学习.... 一.基本概念 1.什么是进程? 当一个程序开始运行时,它就是一个 ...
- 大清朝早亡了,还没有入门 Spring Boot?
由于读者的数量越来越多,难免会被问到一些我自己都觉得不好意思的问题,比如说前几天小王就问我:"二哥,快教教我,怎么通过 Spring Boot 创建一个 Hello World 项目啊?&q ...
- 28-2 类型转换函数Cast-Convet
------------------------类型转换函数------------------------ --cast(表达式 as 数据类型) --convert(数据类型,表达式) ' as ...
- tp5插入百万条数据处理优化
<?php namespace app\index\controller; use think\Controller; use think\Db; class Charu extends Con ...
- js 滚动条滑动
toTop() { let top = document.documentElement.scrollTop || document.body.scrollTop; // 实现滚动效果 const t ...
- Consul+upsync+Nginx实现动态负载均衡
上一篇文章 <C# HttpClient 使用 Consul 发现服务> 解决了内部服务之间的调用问题, 对外提供网关服务还没有解决, 最后我选择了 nginx-upsync-module ...
- [Unity2d系列教程] 005.Unity如何使用外部触控插件FingerGuesture
用过Unity的都知道自带的Input.touches并不支持鼠标输入,给我们的调试带来很大的不方便.那么我们会发现其实有很多触控方面的插件,如inputtouches,easy touch,fing ...
- sku算法详解及Demo~接上篇
前言 做过电商项目前端售卖的应该都遇见过不同规格产品库存的计算问题,业界名词叫做sku(stock Keeping Unit),库存量单元对应我们售卖的具体规格,比如一部手机具体型号规格,其中ipho ...