Python 爬取 热词并进行分类数据分析-[简单准备] (2020年寒假小目标05)
日期:2020.01.27
博客期:135
星期一
【本博客的代码如若要使用,请在下方评论区留言,之后再用(就是跟我说一声)】
所有相关跳转:
a.【简单准备】(本期博客)
b.【云图制作+数据导入】
c.【拓扑数据】
d.【数据修复】
e.【解释修复+热词引用】
f.【JSP演示+页面跳转】
g.【热词分类+目录生成】
h.【热词关系图+报告生成】
i . 【App制作】
j . 【安全性改造】
今天问了一下老师,信息领域热词从哪里爬,老师说是IT方面的新闻,嗯~有点儿意思了!
我找到了好多IT网站,但是大多数广告又多,名词也不专一针对信息领域,所以啊我就暂且用例一个相对还好的例子:
数据来源网址:https://news.51cto.com/(最终不一定使用此网站的爬取数据)
网站的相关热词来源截图:
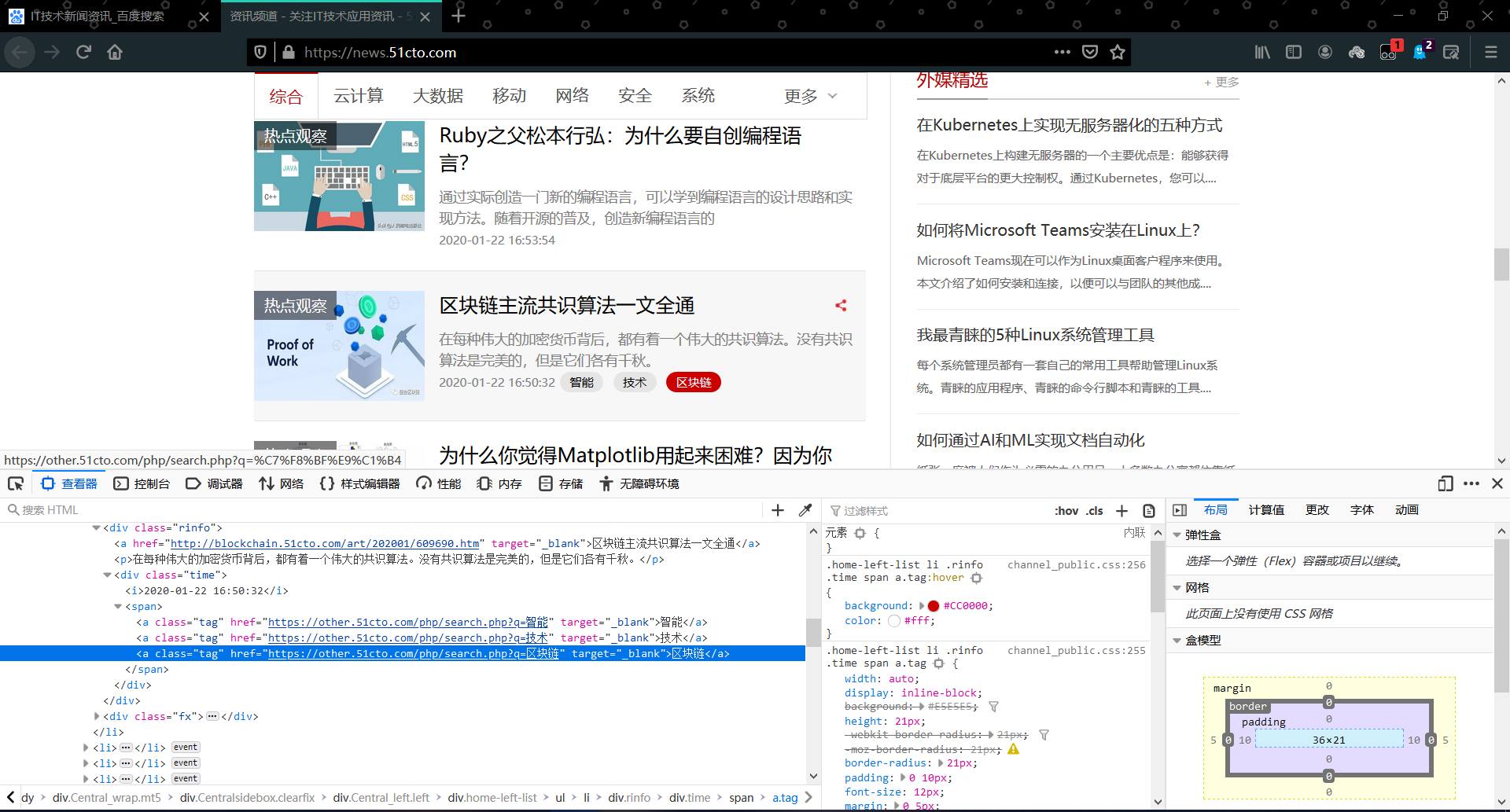
如图,“智能”、“技术”、“区块链”为爬取目标
进行爬取(因为每一次执行js都会加重爬取任务的负担),当你执行到第100次的时候,你现在要执行第101次的JS,它所消耗的时间大概是27s!所以,这种方法我就爬100次,得到5607条数据:

爬取代码:
import parsel
from urllib import request
import codecs
from selenium import webdriver
import time # [ 对字符串的特殊处理方法-集合 ]
class StrSpecialDealer:
@staticmethod
def getReaction(stri):
strs = str(stri).replace(" ","")
strs = strs[strs.find('>')+1:strs.rfind('<')]
strs = strs.replace("\t","")
strs = strs.replace("\r","")
strs = strs.replace("\n","")
return strs class StringWriter:
filePath = ""
def __init__(self,str):
self.filePath = str
pass def makeFileNull(self):
f = codecs.open(self.filePath, "w+", 'utf-8')
f.write("")
f.close() def write(self,stri):
f = codecs.open(self.filePath, "a+", 'utf-8')
f.write(stri + "\n")
f.close() # [ 连续网页爬取的对象 ]
class WebConnector:
profile = ""
sw = ""
# ---[定义构造方法]
def __init__(self):
self.profile = webdriver.Firefox()
self.profile.get('https://news.51cto.com/')
self.sw = StringWriter("../testFile/info.txt")
self.sw.makeFileNull() # ---[定义释放方法]
def __close__(self):
self.profile.quit() # 获取 url 的内部 HTML 代码
def getHTMLText(self):
a = self.profile.page_source
return a # 获取页面内的基本链接
def getFirstChanel(self):
index_html = self.getHTMLText()
index_sel = parsel.Selector(index_html)
links = index_sel.css('.tag').extract()
num = links.__len__()
print("Len="+str(num))
for i in range(0,num):
tpl = StrSpecialDealer.getReaction(links[i])
self.sw.write(tpl) def getMore(self):
self.profile.find_element_by_css_selector(".listsmore").click()
time.sleep(1) def main():
wc = WebConnector()
for i in range(0,100):
print(i)
wc.getMore()
wc.getFirstChanel()
wc.__close__() main()
Director.py
之后再使用MapReduce进行次数统计,就可以了(还可以配合维基百科和百度百科获取(爬取)相关热词的其他信息)
然后是词频统计(因为测试用,数据量不大,就写了简单的Python词频统计程序):
import codecs class StringWriter:
filePath = "" def __init__(self,str):
self.filePath = str
pass def makeFileNull(self):
f = codecs.open(self.filePath, "w+", 'utf-8')
f.write("")
f.close() def write(self,stri):
f = codecs.open(self.filePath, "a+", 'utf-8')
f.write(stri + "\n")
f.close() class Multi:
filePath = "" def __init__(self, filepath):
self.filePath = filepath
pass def read(self):
fw = open(self.filePath, mode='r', encoding='utf-8')
tmp = fw.readlines()
return tmp class Bean :
name = ""
num = 0 def __init__(self,name,num):
self.name = name
self.num = num def __addOne__(self):
self.num = self.num + 1 def __toString__(self):
return self.name+"\t"+str(self.num) def __isName__(self,str):
if str==self.name:
return True
else:
return False class BeanGroup:
data = [] def __init__(self):
self.data = [] def __exist__(self, str):
num = self.data.__len__()
for i in range(0, num):
if self.data[i].__isName__(str):
return True
return False def __addItem__(self,str):
# 存在
if self.__exist__(str):
num = self.data.__len__()
for i in range(0, num):
if self.data[i].__isName__(str):
self.data[i].__addOne__()
# 不存在
else :
self.data.append(Bean(str,1)) def __len__(self):
return self.data.__len__() def takenum(ele):
return ele.num def main():
sw = StringWriter("../testFile/output.txt")
sw.makeFileNull()
bg = BeanGroup()
m = Multi("../testFile/info.txt")
lines = m.read()
num = lines.__len__()
for i in range(0,num):
strs = str(lines[i]).replace("\n","").replace("\r","")
bg.__addItem__(strs)
bg.data.sort(key=takenum,reverse=True)
nums = bg.__len__()
for i in range(0,nums):
sw.write(str(bg.data[i].__toString__())) main()
Multi.py
统计结果如下:
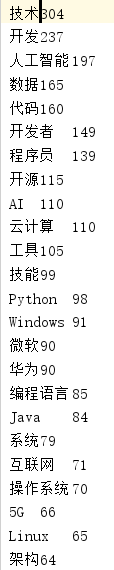
突然发现哈,找到的结果里存在Github和GitHub这两个完全相同的词语,我给当成区分的了!导入数据库的时候就出来问题了,哈哈哈!
整治以后代码:
import codecs class StringWriter:
filePath = "" def __init__(self,str):
self.filePath = str
pass def makeFileNull(self):
f = codecs.open(self.filePath, "w+", 'utf-8')
f.write("")
f.close() def write(self,stri):
f = codecs.open(self.filePath, "a+", 'utf-8')
f.write(stri + "\n")
f.close() class Multi:
filePath = "" def __init__(self, filepath):
self.filePath = filepath
pass def read(self):
fw = open(self.filePath, mode='r', encoding='utf-8')
tmp = fw.readlines()
return tmp class Bean :
name = ""
num = 0 def __init__(self,name,num):
self.name = name
self.num = num def __addOne__(self):
self.num = self.num + 1 def __toString__(self):
return self.name+"\t"+str(self.num) def __toSql__(self):
return "Insert into data VALUES ('" + self.name + "'," + str(self.num) + ");" def __isName__(self,str):
if compare(str,self.name):
return True
else:
return False class BeanGroup:
data = [] def __init__(self):
self.data = [] def __exist__(self, str):
num = self.data.__len__()
for i in range(0, num):
if self.data[i].__isName__(str):
return True
return False def __addItem__(self,str):
# 存在
if self.__exist__(str):
num = self.data.__len__()
for i in range(0, num):
if self.data[i].__isName__(str):
self.data[i].__addOne__()
# 不存在
else :
self.data.append(Bean(str,1)) def __len__(self):
return self.data.__len__() def takenum(ele):
return ele.num def compare(str,dud):
if str == dud :
return True
else:
if str.lower() == dud.lower() :
return True
else:
return False def main():
sw = StringWriter("../testFile/output.txt")
sw.makeFileNull()
bg = BeanGroup()
m = Multi("../testFile/info.txt")
lines = m.read()
num = lines.__len__()
for i in range(0,num):
strs = str(lines[i]).replace("\n","").replace("\r","")
bg.__addItem__(strs)
bg.data.sort(key=takenum,reverse=True)
nums = bg.__len__()
for i in range(0,nums):
sw.write(str(bg.data[i].__toString__())) main()
Multi.py
这就没问题了!

Python 爬取 热词并进行分类数据分析-[简单准备] (2020年寒假小目标05)的更多相关文章
- Python 爬取 热词并进行分类数据分析-[解释修复+热词引用]
日期:2020.02.02 博客期:141 星期日 [本博客的代码如若要使用,请在下方评论区留言,之后再用(就是跟我说一声)] 所有相关跳转: a.[简单准备] b.[云图制作+数据导入] c.[拓扑 ...
- Python 爬取 热词并进行分类数据分析-[云图制作+数据导入]
日期:2020.01.28 博客期:136 星期二 [本博客的代码如若要使用,请在下方评论区留言,之后再用(就是跟我说一声)] 所有相关跳转: a.[简单准备] b.[云图制作+数据导入](本期博客) ...
- Python 爬取 热词并进行分类数据分析-[数据修复]
日期:2020.02.01 博客期:140 星期六 [本博客的代码如若要使用,请在下方评论区留言,之后再用(就是跟我说一声)] 所有相关跳转: a.[简单准备] b.[云图制作+数据导入] c.[拓扑 ...
- Python 爬取 热词并进行分类数据分析-[热词分类+目录生成]
日期:2020.02.04 博客期:143 星期二 [本博客的代码如若要使用,请在下方评论区留言,之后再用(就是跟我说一声)] 所有相关跳转: a.[简单准备] b.[云图制作+数据导入] c.[ ...
- Python 爬取 热词并进行分类数据分析-[拓扑数据]
日期:2020.01.29 博客期:137 星期三 [本博客的代码如若要使用,请在下方评论区留言,之后再用(就是跟我说一声)] 所有相关跳转: a.[简单准备] b.[云图制作+数据导入] c.[拓扑 ...
- Python 爬取 热词并进行分类数据分析-[App制作]
日期:2020.02.14 博客期:154 星期五 [本博客的代码如若要使用,请在下方评论区留言,之后再用(就是跟我说一声)] 所有相关跳转: a.[简单准备] b.[云图制作+数据导入] c.[拓扑 ...
- Python 爬取 热词并进行分类数据分析-[JSP演示+页面跳转]
日期:2020.02.03 博客期:142 星期一 [本博客的代码如若要使用,请在下方评论区留言,之后再用(就是跟我说一声)] 所有相关跳转: a.[简单准备] b.[云图制作+数据导入] c.[拓扑 ...
- Python 爬取 热词并进行分类数据分析-[热词关系图+报告生成]
日期:2020.02.05 博客期:144 星期三 [本博客的代码如若要使用,请在下方评论区留言,之后再用(就是跟我说一声)] 所有相关跳转: a.[简单准备] b.[云图制作+数据导入] c.[拓扑 ...
- python爬取信息到数据库与mysql简单的表操作
python 爬取豆瓣top250并导入到mysql数据库中 import pymysql import requests import re url='https://movie.douban.co ...
随机推荐
- Logarithmic-Trigonometric积分系列(一)
\[\Large\displaystyle \int_{0}^{\frac{\pi }{2}}x^{2}\ln\left ( \sin x \right )\ln\left ( \cos x \rig ...
- SpringMVC的三种处理器适配器
SpringMVC具有三种处理器适配器,他们分别是BeanNameUrlHandlerMapping.SimpleControllerHandlerAdapter.ControllerClassNam ...
- 题解 P4568 【[JLOI2011]飞行路线】
P4568 [JLOI2011]飞行路线 分层图模板题,相似的题还有P4822 [BJWC2012]冻结,P2939 [USACO09FEB]改造路Revamping Trails,其实做惯了也就不难 ...
- django+vue 基础框架 :vue
<template> <div> <p>用户名:<input type="text" v-model="name"&g ...
- ReLU 函数
线性整流函数(Rectified Linear Unit, ReLU),又称修正线性单元,是一种人工神经网络中常用的激活函数(activation function),通常指代以斜坡函数及其变种 为代 ...
- c语言实现面向对象编程
1.通用校验器接口(validator.h) #ifndef VALIDATOR_H_INCLUDED #define VALIDATOR_H_INCLUDED #include<stdbool ...
- mysql带条件的计数
在网站开发的过程中,经常会用到数据统计功能,因此条件计数查询便是不可避免的,下面介绍几种方法来解决此问题. 例(假设): mysql> select * from count_demo; +-- ...
- 校准产品质量,把控出海航向,腾讯WeTest《2019中国移动游戏质量白皮书》正式开放预约
作者:wetest小编 商业转载请联系腾讯WeTest获得授权,非商业转载请注明出处. 原文链接:https://wetest.qq.com/lab/view/483.html 每当步入一个新的年份, ...
- Linux - 命令 - top命令
负载检查:https://blog.csdn.net/HANLIPENGHANLIPENG/article/details/79172053 参考:https://blog.csdn.net/gxia ...
- Windows10+eclipse+hadoop2.7.1环境配置+wordcount-折腾笔记
刚用Ambari搭建好Hadoop,就开始写Hello World! 一.背景 1.Hadoop版本 经查看为2.7.1 Shell 1 2 3 4 5 6 7 [root@T ...