k-means|k-mode|k-prototype|PAM|AGNES|DIANA|Hierarchical cluster|DA|VIF|
聚类算法:
对于数值变量,k-means eg:k=4,则选出不在原数据中的4个点,计算图形中每个点到这四个点之间的距离,距离最近的便是属于那一类。标准化之后便没有单位差异了,就可以相互比较。
对于分类变量,k-mode:
对于数值和分类变量:k-prototype
连续变量与分类变量的权重,K=1则等权重;K<1则分类变量;K>1则数值变量。
PAM:两种因素排序,坐标是(a,b),若k=2,则在其中(通过计算原数据集某一类所有点到某一点距离最短找到该点)选出2个点,计算图形中每个点到这四个点之间的距离,距离最近的便是属于那一类,没有方向性。
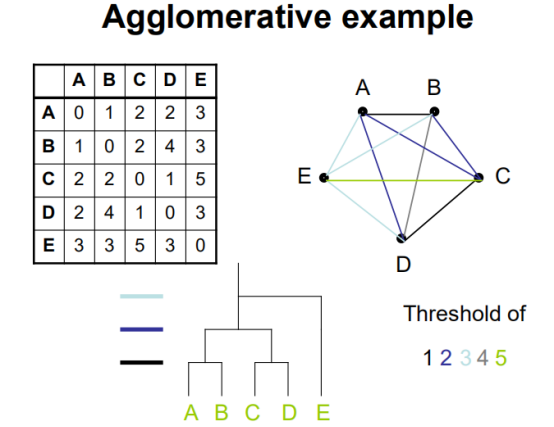
AGNES
DIANA
Cluster之间的比较
通过各种距离计算方式将变量联系在一起,成为聚类的依据。
Hierarchical cluster:将每个变量的不同因素(a,b,c,d,e,f,g)描点成网络,网络变成矩阵(其中网络权重(距离)为矩阵处数值),矩阵变成树形图。
判别函数:
回归是连续变量x解释连续变量y
方差分析是分类变量x解释连续变量y
判别分析(DA)是连续变量x解释分类变量y
使用DA的前提:
样本量是因素种类的4-5倍。
正态性即数据总体是正态分布。
方差齐性即各方面保持均匀。
判断独立性VIF膨胀系数
线性判别函数不够用时,使用线性平方判别函数。

即DA使用判别函数作为分类依据,是有目标的supervised。Cluster使用距离作为分类依据,是没目标unsupervised。
k-means|k-mode|k-prototype|PAM|AGNES|DIANA|Hierarchical cluster|DA|VIF|的更多相关文章
- [CareerCup] 13.1 Print Last K Lines 打印最后K行
13.1 Write a method to print the last K lines of an input file using C++. 这道题让我们用C++来打印一个输入文本的最后K行,最 ...
- 一些简单的问题. 2的10次方与k (涉及到b k m的要用乘来解读)
2的10次方是k k就表示2的10次方 2的16次方,解读为 2的6次方(64)*2的10次方(k) 简写为64k 64k=64*k 同理2的20次方 解读为2的10次方*2的10次方 k ...
- 机器学习 —— 基础整理(三)生成式模型的非参数方法: Parzen窗估计、k近邻估计;k近邻分类器
本文简述了以下内容: (一)生成式模型的非参数方法 (二)Parzen窗估计 (三)k近邻估计 (四)k近邻分类器(k-nearest neighbor,kNN) (一)非参数方法(Non-param ...
- 快速排序/快速查找(第k个, 前k个问题)
//快速排序:Partition分割函数,三数中值分割 bool g_bInvalidInput = false; int median3(int* data, int start, int end) ...
- 在数组a中,a[i]+a[j]=a[k],求a[k]的最大值,a[k]max——猎八哥fly
在数组a中,a[i]+a[j]=a[k],求a[k]的最大值,a[k]max. 思路:将a中的数组两两相加,组成一个新的数组.并将新的数组和a数组进行sort排序.然后将a数组从大到小与新数组比较,如 ...
- [LeetCode] Top K Frequent Words 前K个高频词
Given a non-empty list of words, return the k most frequent elements. Your answer should be sorted b ...
- [LeetCode] K Inverse Pairs Array K个翻转对数组
Given two integers n and k, find how many different arrays consist of numbers from 1 to n such that ...
- [Swift]LeetCode373. 查找和最小的K对数字 | Find K Pairs with Smallest Sums
You are given two integer arrays nums1 and nums2 sorted in ascending order and an integer k. Define ...
- Top K Frequent Elements 前K个高频元素
Top K Frequent Elements 347. Top K Frequent Elements [LeetCode] Top K Frequent Elements 前K个高频元素
随机推荐
- Essay写作常见问题解析
Essay是西方大学的主要考核形式之一.其理念是考核学生对资料信息的吸取和观点的输出能力.可是对于刚踏入美国大学的国际留学生来说,写Essay就像是一种水土不服.各种不适和挣扎是不可避免的!今天小编来 ...
- 查看 vps 进程网络流量
弄好了 vps 以后,感觉网络流量走的有点多,决定查查看到底什么情况. 首先安装 sar 来看看各个设备消耗的流量 apt-get install sysstat sar 的参数 DEV 表示网口, ...
- Sqlserver 增删改查----增
注意我说的常见查询,可不是简单到一个表得增删改查,做过实际开发得人都知道,在实际开发中,真正牵扯到一个表得增删改查只能说占很小得一部分,大多都是好几个表的关联操作的. 下面我就说一下我在实际开发中经常 ...
- Spring Boot without the web server
https://stackoverflow.com/questions/26105061/spring-boot-without-the-web-server/28565277 1. spring.m ...
- Android群英传神兵利器读书笔记——第二章:版本控制神器——Git
本人一直是徐医生的真爱粉,由于参加比赛耽误了8天,导致更新得有点慢,大家见谅 2.1 Git的前世今生 Git是什么 Git安装与配置 2.2 创建Git仓库 Git init Git clone 2 ...
- POJ 1164:The Castle
The Castle Time Limit: 1000MS Memory Limit: 10000K Total Submissions: 6677 Accepted: 3767 Descri ...
- HTTP协议(三):状态码
前言 作者说:在上一节的内容中,HTTP大佬介绍了他是怎么让服务器和用户达成信息交互的,详细的说明了连接建立过程中用到的一些基本的技术原理,包括请求报文响应报文.建立持久化连接用的Cookie技术等内 ...
- SeetaFaceQt:写一个简单的界面
关于这个界面,我用到了几个控件,这些控件通过Qt是非常容易构建的,窗口的话用的是QWidget,之前说了,QWidget是Qt里面几乎大部分控件的父类,QWidget的布局我使用了简单的水平布局(QH ...
- python一个正则表达式的不解
htmlSource="data-lazy=\"http://gtms01.alicdn.com/tps/i1/T1faOCFQXXXXc2jIrl-.png\"&quo ...
- java课程之团队开发冲刺阶段1.8
一.总结昨天进度 1.实现预装sqlite数据库,将数据库放在app的assets目录下,该目录在打包的时候不会压缩,所以数据库文件可以在安装之后继续使用,然后APP安装之后检测外部存储空间是否有这个 ...