ELK:日志收集分析平台
简介
ELK是一个日志收集分析的平台,它能收集海量的日志,并将其根据字段切割。一来方便供开发查看日志,定位问题;二来可以根据日志进行统计分析,通过其强大的呈现能力,挖掘数据的潜在价值,分析重要指标的趋势和分布等,能够规避灾难和指导决策等。ELK是Elasticsearch公司出品的一组套件,官方站点:https://www.elastic.co,本文中ELK需要用的组件有Elasticsearch、Logstash、Kibana、Filebeat(Beats组合中的一个),主要介绍该集群的建设部署以及一些注意事项,希望对需要的小伙伴有所帮助,对于文中错误,欢迎批评指正。
环境说明
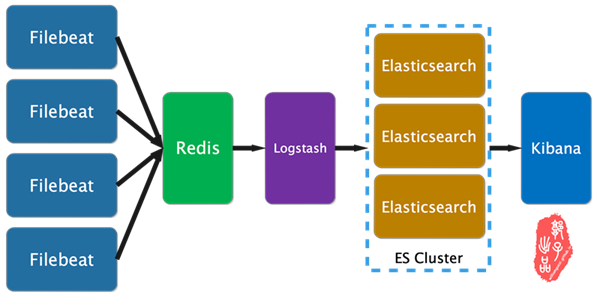
下面是本文的逻辑架构图,其中filebeat为采集日志的客户端,其安装在产生日志的机器上,收集的日志插入到redis消息队列中,logstash从redis取出数据并做相应的处理,其中包括字段拆分定义,并将数据输出到ES集群中,ES集群将数据处理、分片、索引等,最终kibana作为页面展示,将从ES集群取出数据做分析、统计、处理、展示,当然,其中有用到x-pack插件做数据分析、统计和展现(就是一些漂亮的实时图表)。
- 本文采用软件版本均为6.3.
Filebeat 部署
yum -y install epel-release
mkdir /data/soft -pv
cd /data/soft/
yum install wget vim -y
wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-6.3.1-x86_64.rpm
yum install filebeat-6.3.1-x86_64.rpm -y
web上采集配置文件
cat > /etc/filebeat/filebeat.conf <<"EOF"
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/nginx/crmwww-dev-access.log
- /var/log/nginx/manager2018crm-dev-access.log
- /var/log/nginx/hybrid-dev-access.log
- /var/log/nginx/cfdwww-dev-access.log
- /var/log/nginx/manager2018cfd-dev-access.log
- /var/log/nginx/market2018cfd-dev-access.log
- /var/log/nginx/api2018cfd-dev-access.log
fields:
project: cfds
env: dev
role: web
logtype: access
ip: 192.168.0.152
fields_under_root: true
#采集信息追加字段,便于分组,fields_under_root指定字段的访问模式为直接访问,不必使用fields.project
- type: log
enabled: true
paths:
- /var/log/nginx/manager2018crm-dev-error.log
- /var/log/nginx/manager2018cfd-dev-error.log
- /var/log/nginx/market2018cfd-dev-error.log
- /var/log/nginx/cfdwww-dev-error.log
- /var/log/nginx/hybrid-dev-error.log
- /var/log/nginx/crmwww-dev-error.log
- /var/log/nginx/api2018cfd-dev-error.log
fields:
project: cfds
env: dev
role: web
logtype: error
ip: 192.168.0.152
fields_under_root: true
#将日志输出到redis
output.redis:
hosts: ["redis.glinux.top"]
key: "cfds"
db: 0
password: "123456"
timeout: 15
#可通过以下配置测试输出结果,输入内容在/tmp/filebeat/filebeat
#output.file:
## path: "/tmp/filebeat"
## filename: filebeat
EOF
app上采集配置文件
cat > /etc/filebeat/filebeat.conf <<"EOF"
filebeat.inputs:
- type: log
enabled: true
paths:
- /data/logs/crm/error/crm.log
fields:
project: cfds
env: dev
role: crm
logtype: error
ip: 192.168.0.155
fields_under_root: true
#处理多行数据,如果不以时间开头的行归为上一行的数据,接到上一行数据后面
multiline.pattern: '^[0-9]{4}-[0-9]{2}-[0-9]{2}'
multiline.negate: true
multiline.match: after
multiline.timeout: 10s
- type: log
enabled: true
paths:
- /data/logs/crm/info/crm.log
fields:
project: cfds
env: dev
role: crm
logtype: info
ip: 192.168.0.155
fields_under_root: true
multiline.pattern: '^[0-9]{4}-[0-9]{2}-[0-9]{2}'
multiline.negate: true
multiline.match: after
multiline.timeout: 10s
output.redis:
hosts: ["redis.glinux.top"]
key: "cfds"
db: 0
password: "123456"
timeout: 15
#可通过以下配置测试输出结果,输入内容在/tmp/filebeat/filebeat
#output.file:
## path: "/tmp/filebeat"
## filename: filebeat
EOF
filebeat test config /etc/filebeat/filebeat.yml #测试配置文件
systemctl enable filebeat
systemctl restart filebeat
Redis 部署
yum -y install epel-release
yum -y install redis
配置文件
仅需要添加密码认证即可
cat >> /etc/redis.conf << "EOF"
requirepass "123456"
systemctl enable redis
systemctl start redis
Logstash 部署
yum -y install epel-release
mkdir /data/soft -pv
cd /data/soft/
yum install wget vim -y
wget https://artifacts.elastic.co/downloads/logstash/logstash-6.3.1.rpm
yum install logstash-6.3.1.rpm -y
rpm -ql logstash #查看安装路径
cat > /etc/profile.d/logstash.sh <<"EOF"
export PATH=/usr/share/logstash/bin/:$PATH
EOF
. /etc/profile.d/logstash.sh #读取环境变量
yum -y install java-1.8.0-openjdk
配置文件
cat > /etc/logstash/logstashserver.conf <<"EOF"
input {
redis {
host => ["127.0.0.1"]
key => "ftms"
port => 6379
password => "123456"
data_type => ["list"]
}
redis {
host => ["127.0.0.1"]
key => "cfds"
port => 6379
password => "123456"
data_type => ["list"]
}
}
filter {
if [role] == "web" and [logtype] == "access" {
grok {
patterns_dir => ["/usr/share/logstash/vendor/bundle/jruby/2.3.0/gems/logstash-patterns-core-4.1.2/patterns"]
match => ["message" , "%{NGINXACCESS}"]
}
}
if [role] == "web" and [logtype] == "error" {
grok {
patterns_dir => ["/usr/share/logstash/vendor/bundle/jruby/2.3.0/gems/logstash-patterns-core-4.1.2/patterns"]
match => ["message" , "%{NGINXERROR}"]
}
}
else {
grok {
patterns_dir => ["/usr/share/logstash/vendor/bundle/jruby/2.3.0/gems/logstash-patterns-core-4.1.2/patterns"]
match => ["message" , "%{TIMESTAMP_ISO8601:logdatetime} %{LOGLEVEL:level} \[%{DATA:thread}\] %{JAVACLASS:class} \[%{JAVAFILE:file}(?::%{NUMBER:line})?\] - %{GREEDYDATA:message}"]
}
}
}
output {
elasticsearch {
hosts => ["http://192.168.30.36:9200","http://192.168.30.37:9200","192.168.30.38:9200"]
index => "%{project}-%{env}-%{role}-%{logtype}-%{+YYYY.MM.dd}"
}
}
EOF
logstash -f /etc/logstash/logstashserver.conf -t #测试配置文件是否有误
systemctl enable logstash
systemctl restart logstash
Elasticsearch 集群部署
yum install java-1.8.0-openjdk -y
yum -y install epel-release
mkdir /data/soft -pv
cd /data/soft/
yum install wget vim -y
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.3.1.rpm
yum install elasticsearch-6.3.1.rpm -y
rpm -ql elasticsearch
cat > /etc/profile.d/elasticsearch.sh <<"EOF"
export PATH=/usr/share/elasticsearch/bin/:$PATH
EOF
. /etc/profile.d/elasticsearch.sh
配置文件
node1
cat > /etc/elasticsearch/elasticsearch.yml <<"EOF"
cluster.name: logs
node.name: node-36-2
#node.master: false
#node.data: true
path.data: /data/server/elasticsearch
path.logs: /var/log/elasticsearch
network.host: 0.0.0.0
http.port: 9200
transport.tcp.port: 9300
discovery.zen.ping.unicast.hosts: ["192.168.30.36","192.168.30.37","192.168.30.38"]
discovery.zen.minimum_master_nodes: 2
node2
cat > /etc/elasticsearch/elasticsearch.yml <<"EOF"
cluster.name: logs
node.name: node-37-1
#node.master: false
#node.data: true
path.data: /data/server/elasticsearch
path.logs: /var/log/elasticsearch
network.host: 0.0.0.0
http.port: 9200
transport.tcp.port: 9300
discovery.zen.ping.unicast.hosts: ["192.168.30.36","192.168.30.37","192.168.30.38"]
discovery.zen.minimum_master_nodes: 2
node3
cat > /etc/elasticsearch/elasticsearch.yml <<"EOF"
cluster.name: logs
node.name: node-38-3
#node.master: false
#node.data: true
path.data: /data/server/elasticsearch
path.logs: /var/log/elasticsearch
network.host: 0.0.0.0
http.port: 9200
transport.tcp.port: 9300
discovery.zen.ping.unicast.hosts: ["192.168.30.36","192.168.30.37","192.168.30.38"]
discovery.zen.minimum_master_nodes: 2
systemctl enable elasticsearch
systemctl start elasticsearch
systemctl status elasticsearch
查看集群状态
curl 'localhost:9200/_cat/nodes?v'

Kibana 部署
yum -y install epel-release
mkdir -pv /data/soft
cd /data/soft/
yum install wget vim -y
wget https://artifacts.elastic.co/downloads/kibana/kibana-6.3.1-x86_64.rpm
yum install kibana-6.3.1-x86_64.rpm -y
cat > /etc/kibana/kibana.yml <<"EOF"
server.host: "0.0.0.0"
elasticsearch.url: "http://escluster.glinux.top:9200"
EOF
systemctl enable kibana.service
systemctl start kibana.service
端口转发,普通程序不能监听在1024以下的端口,解决方法
cat > /etc/sysctl.conf <<"EOF"
net.ipv4.ip_forward = 1 #重新加载
sysctl -p /etc/sysctl.conf
iptables -A PREROUTING -t nat -p tcp --dport 80 -j REDIRECT --to-port 5601
注意事项
grok模式匹配日志
logstash模式匹配拆分日志可谓关键的一环其中有些注意要点
- logstash 模式匹配的pattern放在/usr/share/logstash/vendor/bundle/jruby/2.3.0/gems/logstash-patterns-core-4.1.2/patterns目录下
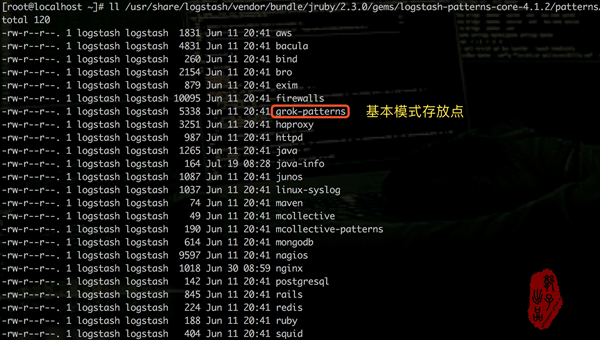
- 测试模式匹配样例,最终匹配到的字段会在kibana中显示,作为可供筛选的关键字
kibana索引添加
索引的制定能加快查询速度和项目分类,索引分为es的索引和kibana的索引。
- 针对es的索引,我的处理方式是在filebeat收集日志的时候给每条日志添加fileds字段,如下:
- project: cfds
- env: dev
- logtype: access
- ip: 192.168.0.152
logstash 在拿到日志后将%{project}-%{env}-%{role}-%{logtype}-%{+YYYY.MM.dd}作为索引将日志分类送给es集群。
2. kibana的索引,就是将es的索引做综合归类。
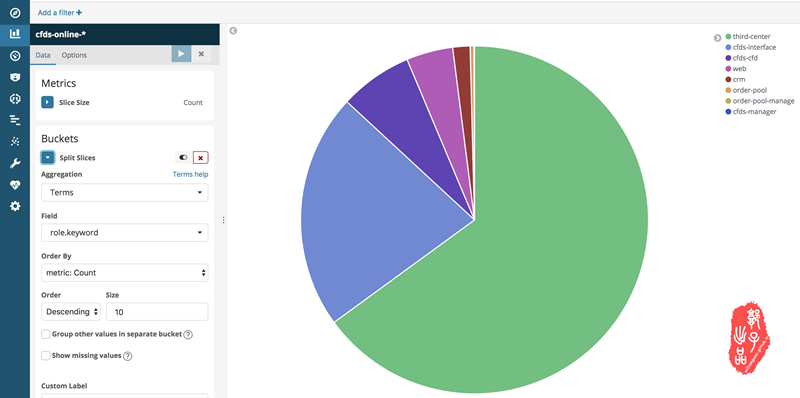
x-pack图表配置
x-pack可以试用,网络上有破解方式,其可根据字段做数据统计呈现,呈现方式众多,实时更新,可做数据挖掘,数据报告。下面贴上我做的一个示例。
参考文档
- Filebeat配置文档: https://www.elastic.co/guide/en/beats/filebeat/current/index.html
- Logstash配置文档: https://www.elastic.co/guide/en/logstash/current/configuration.html
- ES集群参考文档: https://www.jianshu.com/p/149a8da90bbc
- 集群状态查看参考文档: https://segmentfault.com/a/1190000010975383
- logstash优化: http://jaminzhang.github.io/elk/Logstash-Performance-Troubleshooting-Guide
ELK:日志收集分析平台的更多相关文章
- ELK日志收集分析平台部署使用
一.ELK介绍 开源实时日志分析ELK平台能够完美的解决我们上述的问题,ELK由ElasticSearch.Logstash和Kiabana三个开源工具组成: 1.ElasticSearch是一个基于 ...
- ELK日志收集分析平台 (Elasticsearch+Logstash+Kibana)使用说明
使用ELK对返回502的报警进行日志的收集汇总 eg:Server用户访问网站返回502 首先在zabbix上找到Server的IP 然后登录到elk上使用如下搜索条件: pool_select:X. ...
- ELK/EFK——日志收集分析平台
ELK——日志收集分析平台 ELK简介:在开源的日志管理方案之中,最出名的莫过于ELK了,ELK由ElasticSearch.Logstash和Kiabana三个开源工具组成.1)ElasticSea ...
- ELKF-分布式日志收集分析平台搭建 最小化 配置过程 - 查看收集日志(windows10下搭建)
前言 Elasticsearch是与名为Logstash的数据收集和日志解析引擎以及名为Kibana的分析和可视化平台一起开发的.这三个产品被设计成一个集成解决方案,称为“Elastic Stack” ...
- ELK日志收集分析系统配置
ELK是日志收益与分析的利器. 1.elasticsearch集群搭建 略 2.logstash日志收集 我这里的实现分如下2步,中间用redis队列做缓冲,可以有效的避免es压力过大: 1.n个ag ...
- 用ELK搭建简单的日志收集分析系统【转】
缘起 在微服务开发过程中,一般都会利用多台服务器做分布式部署,如何能够把分散在各个服务器中的日志归集起来做分析处理,是一个微服务服务需要考虑的一个因素. 搭建一个日志系统 搭建一个日志系统需要考虑一下 ...
- FILEBEAT+ELK日志收集平台搭建流程
filebeat+elk日志收集平台搭建流程 1. 整体简介: 模式:单机 平台:Linux - centos - 7 ELK:elasticsearch.logstash.kiban ...
- SpringBoot使用ELK日志收集
本文介绍SpringBoot应用配合ELK进行日志收集. 1.有关ELK 1.1 简介 在之前写过一篇文章介绍ELK日志收集方案,感兴趣的可以去看一看,点击这里-----> <ELK日志分 ...
- springboot 集成 elk 日志收集功能
Lilishop 技术栈 官方公众号 & 开源不易,如有帮助请点Star 介绍 官网:https://pickmall.cn Lilishop 是一款Java开发,基于SpringBoot研发 ...
随机推荐
- Ant Design中getFieldDecorator方法的特殊用法(小bug)
记录Ant Design中getFieldDecorator方法的特殊的一个用法 了解Ant Design表单的小伙伴都知道,getFieldDecorator在大部分情况下是用来绑定一个控件的,即像 ...
- POJ 2456 Aggressive cows (二分)
题目传送门 POJ 2456 Description Farmer John has built a new long barn, with N (2 <= N <= 100,000) s ...
- UGUI源码之EventSystem
今天研究下UGUI的源码,先从EventSystem入手.EventSystem是用来处理点击.键盘输入以及触摸等事件的. 1.BaseInputModule EventSystem开头声明了两个变量 ...
- 在IIS上发布netcore项目
保证电脑上有.net core sdk或者.net core runtime; 需要安装AspNetCoreModule托管模块:DotNetCore.2.0.5-WindowsHosting.exe ...
- python封装简介
1.效果图: 对比一: 对比二: 2.学习来源代码: # 封装是面向对象的三大特性之一 # 封装指的是隐藏对象中一些不希望被外部所访问到的属性或方法 # 如何隐藏一个对象中的属性? # - 将对象的属 ...
- 一文搞定Spring Boot + Vue 项目在Linux Mysql环境的部署(强烈建议收藏)
本文介绍Spring Boot.Vue .Vue Element编写的项目,在Linux下的部署,系统采用Mysql数据库.按照本文进行项目部署,不迷路. 1. 前言 典型的软件开发,经过" ...
- 《C# 爬虫 破境之道》:概述
第一节:写作本书的目的 关于笔者 张晓亭(Mike Cheers),1982年出生,内蒙古辽阔的大草原是我的故乡. 没有高学历,没有侃侃而谈的高谈阔论,拥有的就是那一份对技术的执著,对自我价值的追求. ...
- 关于后缀间$LCP$的一些公式的证明
目录 关于\(LCP\)有如下两个公式: \(LCP~Lemma\) 的证明: \(LCP~Theorem\) 的证明: 关于\(LCP\)有如下两个公式: \(LCP~Lemma:\) 对任意 \( ...
- Dappy如何防止DNS黑客入侵
作者:Raphaël 译者注:Dappy是RChain生态中的DNS[域名系统(服务)协议].Dappy基于RChain的技术架构保障了域名系统的安全性. Dappy是一个用于文件和Web应用程序的去 ...
- 优雅写Java之二(数组集合流)
一.数组 二.集合 三.流 学习整理中,本文待补充--