时序数据库 Apache-IoTDB 源码解析之文件索引块(五)
上一章聊到 TsFile 的文件组成,以及数据块的详细介绍。详情请见:
时序数据库 Apache-IoTDB 源码解析之文件数据块(四)
打一波广告,欢迎大家访问IoTDB 仓库,求一波 Star。
这一章主要想聊聊:
- TsFile索引块的组成
- 索引块的查询过程
- 索引块目前在做的改进项
索引块
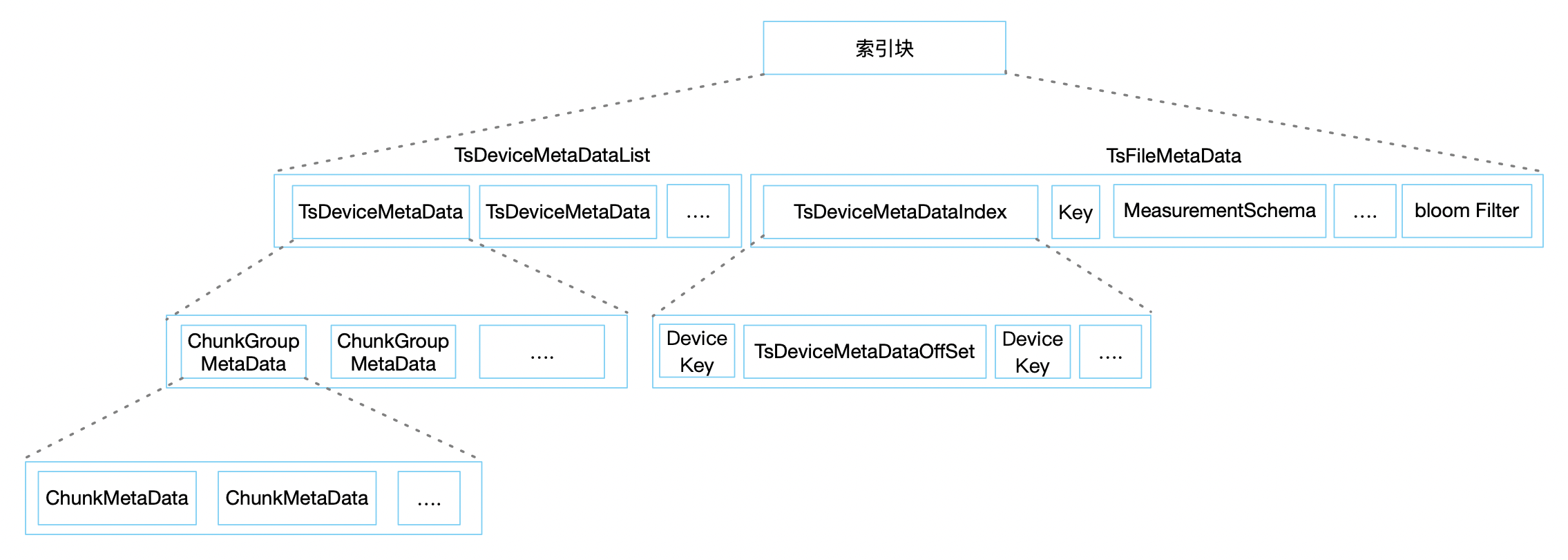
索引块由两大部分组成,其写入的方式是从左到右写入,也就是从文件头向文件尾写入。但读出的方式是先读出TsFileMetaData 再读出 TsDeviceMetaDataList 中的具体一部分。我们按照读取数据的顺序介绍:
TsFileMetaData
TsFileMetaData属于文件的 1 级索引,用来索引 Device 是否存在、在哪里等信息,其中主要保存了:
- DeviceMetaDataIndexMap:Map结构,Key 是设备名,Value 是 TsDeviceMetaDataIndex ,保存了包含哪些 Device(逻辑概念上的一个集合一段时间内的数据,例如前几章我们讲到的:张三、李四、王五)以及他们的开始时间及结束时间、在左侧 TsDeviceMetaDataList 文件块中的偏移量等。
- MeasurementSchemaMap:Map结构,Key 是测点的一个全路径,Value 是 measurementSchema ,保存了包含的测点数据(逻辑概念上的某一类数据的集合,如体温数据)的原信息,如:压缩方式,数据类型,编码方式等。
- 最后是一个布隆过滤器,快速检测某一个
时间序列是不是存在于文件内(这里等聊到 server 模块写文件的策略时候再聊)。我们知道这个过滤器的特点就是:没有的一定没有,但有的不一定有。为了保证准确性和过滤器序列化后的大小均衡,这里提供了一个 1% - 10% 错误率的可配置,当为 1% 错误率时,保存 1 万个测点信息,大概是 11.7 K。
我们再回想 SQL :SELECT 体温 FROM 王五 WHERE time = 1 。读文件的过程就应该是:
- 先用
布隆过滤器判断文件内是否有王五的体温列,如果没有,查找下一个文件。 - 从 DeviceMetaDataIndexMap 中找到
王五的 TsDeviceMetaDataIndex ,从而得到了王五的 TsDeviceMetadata 的 offset,接下来就寻道至这个 offset 把王五的 TsDeviceMetadata 读出来。 - MeasurementSchemaMap 不用关注,主要是给 Spark 使用的,ChunkHeader 中也保存了这些信息。
TsDeviceMetaDataList
TsDeviceMetaDataList 属于文件的 2 级索引,用来索引具体的测点数据是不是存在、在哪里等信息。其中主要保存了:
- ChunkGroupMetaData:ChunkGroup 的索引信息,主要包含了每个 ChunkGroup 数据块的起止位置以及包含的所有的测点元信息(ChunkMetaData)。
- ChunkMetaData :Chunk 的索引信息,主要包含了每个设备的测点在文件中的起止位置、开始结束时间、数据类型和预聚合信息。
上面的例子中,从 TsFileMetadata 已经拿到了王五的 TsDeviceMetadataIndex,这里就可以直接读出王五的 TsDeviceMetadata,并且遍历里边的 ChunkGroupMetadata 中的 ChunkMetadata,找到体温对应的所有的 ChunkMetadata。通过预聚合信息对时间过滤,判断能否使用当前的 Chunk 或者能否直接使用预聚合信息直接返回数据(等介绍到 server 的查询引擎时候细聊)。
如果不能直接返回,因为 ChunkMetaData 包含了这个 Chunk 对应的文件的偏移量,只需要使用 seek(offSet) 就会跳转到数据块,使用上一章介绍的读取方法进行遍历就完成了整个读取。
预聚合信息(Statistics)
文中多次提到了预聚合在这里详细介绍一下它的数据结构。
// 所属文件块的开始时间
private long startTime;
// 所属文件块的结束时间
private long endTime;
// 所属文件块的数据类型
private TSDataType tsDataType;
// 所属文件块的最小值
private int minValue;
// 所属文件块的最大值
private int maxValue;
// 所属文件块的第一个值
private int firstValue;
// 所属文件块的最后一个值
private int lastValue;
// 所属文件块的所有值的和
private double sumValue;
这个结构主要保存在 ChunkMetaData 和 PageHeader 中,这样做的好处就是,你不必从硬盘中读取具体的Page 或者 Chunk 的文件内容就可以获得最终的结果,例如:SELECT SUM(体温) FROM 王五 ,当定位到 ChunkMetaData 时,判断能否直接使用这个 Statistics 信息(具体怎么判断,之后会在介绍 server 时具体介绍),如果能使用,那么直接返回 sumValue。这样返回的速度,无论存了多少数据,它的聚合结果响应时间简直就是 1 毫秒以内。
样例数据
我们继续使用上一章聊到的示例数据来展示。
| 时间戳 | 人名 | 体温 | 心率 |
|---|---|---|---|
| 1580950800 | 王五 | 36.7 | 100 |
| 1580950911 | 王五 | 36.6 | 90 |
完整的文件信息如下:
POSITION| CONTENT
-------- -------
0| [magic head] TsFile
6| [version number] 000002
// 数据块开始
||||||||||||||||||||| [Chunk Group] of wangwu begins at pos 12, ends at pos 253, version:0, num of Chunks:2
12| [Chunk] of xinlv, numOfPoints:1, time range:[1580950800,1580950800], tsDataType:INT32,
[minValue:100,maxValue:100,firstValue:100,lastValue:100,sumValue:100.0]
| [marker] 1
| [ChunkHeader]
| 1 pages
121| [Chunk] of tiwen, numOfPoints:1, time range:[1580950800,1580950800], tsDataType:FLOAT,
[minValue:36.7,maxValue:36.7,firstValue:36.7,lastValue:36.7,sumValue:36.70000076293945]
| [marker] 1
| [ChunkHeader]
| 1 pages
230| [Chunk Group Footer]
| [marker] 0
| [deviceID] wangwu
| [dataSize] 218
| [num of chunks] 2
||||||||||||||||||||| [Chunk Group] of wangwu ends
// 索引块开始
253| [marker] 2
254| [TsDeviceMetadata] of wangwu, startTime:1580950800, endTime:1580950800
| [startTime] 1580950800
| [endTime] 1580950800
| [ChunkGroupMetaData] of wangwu, startOffset12, endOffset253, version:0, numberOfChunks:2
| [ChunkMetaData] of xinlv, startTime:1580950800, endTime:1580950800, offsetOfChunkHeader:12, dataType:INT32, statistics:[minValue:100,maxValue:100,firstValue:100,lastValue:100,sumValue:100.0]
| [ChunkMetaData] of tiwen, startTime:1580950800, endTime:1580950800, offsetOfChunkHeader:121, dataType:FLOAT, statistics:[minValue:36.7,maxValue:36.7,firstValue:36.7,lastValue:36.7,sumValue:36.70000076293945]
446| [TsFileMetaData]
| [num of devices] 1
| [TsDeviceMetadataIndex] of wangwu, startTime:1580950800, endTime:1580950800, offSet:254, len:192
| [num of measurements] 2
| 2 key&measurementSchema
| [createBy isNotNull] false
| [totalChunkNum] 2
| [invalidChunkNum] 0
//布隆过滤器
| [bloom filter bit vector byte array length] 30
| [bloom filter bit vector byte array]
| [bloom filter number of bits] 256
| [bloom filter number of hash functions] 5
599| [TsFileMetaDataSize] 153
603| [magic tail] TsFile
609| END of TsFile
当执行: SELECT 体温 FROM 王五 时:
- 从
599开始读,1 级索引长度为 153. 599 - 153 = 446就是 1 级索引读开始位置,并读出 TsDeviceMetadataIndex of 王五,其中记录了,王五设备的 2 级索引的 offset 为 254.- 跳到
254开始读 2 级索引,找到 ChunkMetaData of 体温, 其中记录了体温数据的 Chunk 的offset 为121 - 跳到
121,这里进入了数据块,从121读取到230,读出的数据就全部是体温数据。
改进项
1. 只读投影列
前面第 3 步中,读取 2 级索引时候,会将这个设备下的所有测点数据全部读出来,这依然不太符合只读投影列的设计,所以在新的 TsFile 中,修改了 1级索引和 2 级索引的部分结构,使得读出的数据更少,更高效。有兴趣的同学可以关注 PR: Refactor TsFile #736
2. 文件级 Statistics
在物联网场景中经常会涉及到查询某个设备的最后状态,比如:车联网中,查询车辆的末次位置( SELECT LAST(lat,lon) FROM VechicleID ),或者当前的点火、熄火状态等 SELECT LAST(accStatus) FROM VechicleID 。
或者当某些分页查询等情况时候,经常会使用到 COUNT(*) 等操作,这些都非常符合 Statistics 结构,这些场景涉及到的索引设计也都会体现到新的 TsFile 索引改动中。
到此已经介绍完了文件的整体结构,了解了大体的写入和读取过程,但是 TsFile 的 API 是如何设计的,怎样在代码里做一些特殊的功课,来绕过 Java 装箱、GC 等问题呢?欢迎持续关注。。。。
时序数据库 Apache-IoTDB 源码解析之文件索引块(五)的更多相关文章
- 时序数据库 Apache-IoTDB 源码解析之元数据索引块(六)
上一章聊到 TsFile 索引块的详细介绍,以及一个查询所经过的步骤.详情请见: 时序数据库 Apache-IoTDB 源码解析之文件索引块(五) 打一波广告,欢迎大家访问 IoTDB 仓库,求一波 ...
- 时序数据库 Apache-IoTDB 源码解析之文件数据块(四)
上一章聊到行式存储.列式存储的基本概念,并介绍了 TsFile 是如何存储数据以及基本概念.详情请见: 时序数据库 Apache-IoTDB 源码解析之文件格式简介(三) 打一波广告,欢迎大家访问Io ...
- Ocelot简易教程(七)之配置文件数据库存储插件源码解析
作者:依乐祝 原文地址:https://www.cnblogs.com/yilezhu/p/9852711.html 上篇文章给大家分享了如何集成我写的一个Ocelot扩展插件把Ocelot的配置存储 ...
- React源码解析之React.Children.map()(五)
一,React.Children是什么? 是为了处理this.props.children(this.props.children表示所有组件的子节点)这个属性提供的工具,是顶层的api之一 二,Re ...
- tp3.2源码解析——入口文件
如果有人读这篇文章并跟着做的话,希望你能使用支持函数跳转的编辑器,还要善用var_dump和exit,对着源码去调试着看.跟着入口文件读,执行到哪里你看到哪里,对于那些不能一眼看出来的配置,则要记录下 ...
- tensorflow源码解析系列文章索引
文章索引 framework解析 resource allocator tensor op node kernel graph device function shape_inference 拾遗 c ...
- Mybatis源码解析(四) —— SqlSession是如何实现数据库操作的?
Mybatis源码解析(四) -- SqlSession是如何实现数据库操作的? 如果拿一次数据库请求操作做比喻,那么前面3篇文章就是在做请求准备,真正执行操作的是本篇文章要讲述的内容.正如标题一 ...
- Parquet 源码解析
date: 2020-07-20 16:15:00 updated: 2020-07-27 13:40:00 Parquet 源码解析 Parquet文件是以二进制方式存储的,所以是不可以直接读取的, ...
- laravel 读写分离源码解析
前言:上一篇我们说了<laravel 配置MySQL读写分离>,这次我们说下,laravel的底层代码是怎样实现读写分离的. 一.实现原理 说明: 1.根据 database.php ...
随机推荐
- 2020年我国到底有多少程序员?现在学习java还来得及吗?
中国有多少程序员?现在还值得学java吗? 跪求关注,祝关注我的人都:身体健康,财源广进,福如东海,寿比南山,早上贵子,从不掉发! JAVA起于1995年,经过20多年的发展,JAVA如今已经发展成为 ...
- CSRF 详解:攻击,防御,Spring Security应用等
本文原创,更多内容可以参考: Java 全栈知识体系.如需转载请说明原处. CSRF(Cross-site request forgery跨站请求伪造,也被称成为"one click att ...
- Redis系列之----Redis的数据类型及使用场景
Redis是一个开源的.高性能的.基于键值对的缓存与存储系统,能够提供多种不同的键值数据类型来适应不同场景下的缓存和存储需求. Redis中所有的数据都存储在内存中,因此读写速度非常快,相 ...
- Redis系列之----Redis的两种持久化机制(RDB和AOF)
Redis的两种持久化机制(RDB和AOF) 什么是持久化 Redis的数据是存储在内存中的,内存中的数据随着服务器的重启或者宕机便会不复存在,在生产环境,服务器宕机更是屡见不鲜,所以,我们希望 ...
- Lua表(table)的个人总结
1.表的简介和构造 table是个很强大且神奇的东西,又可以作为数组和字典,又可以当作对象,设置module.它是由数组和哈希表结合的实现的.他的key可以是除nil以外任意类型的值,key为整数时, ...
- 小程序和wepy做循环渲染如何点击拿到相对应的值
数据和其他的就忽略,简单上手,wepy的for渲染方式改成对应的就行,传参触发不用改 <view wx:for="{{list}}"> {{item.title}} & ...
- js的alert()
效果图: 图一: 图二: 图三: 代码: <script type="text/javascript"> // alert() ; 只允许一个参数,如果有多个参数只显示 ...
- GitHub高级搜索指南
还在为自学时找不到适合练手的项目而苦恼? 还在好奇别人是如何在GitHub众多项目中找到高质量代码的? 真的是因为他们独具慧眼吗? 不,其实他们只是掌握了正确的搜索方法. 下面介绍几种常用的GitHu ...
- matplotlib 条形图
一.特点 离散数据,数据之间没有直接的关系 二.分类 1.垂直条形图 bar(x, height, width=0.8) # x 为x轴 # height 为y轴 # width 为 条形图的宽度 例 ...
- 支撑京东小程序的开发框架 「Taro」
Taro 简介 现在支持小程序的平台太多了,例如: 微信小程序 QQ小程序 支付宝小程序 百度小程序 字节跳动小程序 针对他们都各自开发一套的话开发成本就太高了. 如果写一套代码,就能开发出适配这么多 ...