spark自定义分区器实现
在spark中,框架默认使用的事hashPartitioner分区器进行对rdd分区,但是实际生产中,往往使用spark自带的分区器会产生数据倾斜等原因,这个时候就需要我们自定义分区,按照我们指定的字段进行分区。具体的流程步骤如下:
1、创建一个自定义的分区类,并继承Partitioner,注意这个partitioner是spark的partitioner
2、重写partitioner中的方法
override def numPartitions: Int = ???
override def getPartition(key: Any): Int = ??? 代码实现:
测试数据集:
cookieid,createtime,pv
cookie1,2015-04-10,1
cookie1,2015-04-11,5
cookie1,2015-04-12,7
cookie1,2015-04-13,3
cookie1,2015-04-14,2
cookie1,2015-04-15,4
cookie1,2015-04-16,4
cookie2,2015-04-10,2
cookie2,2015-04-11,3
cookie2,2015-04-12,5
cookie2,2015-04-13,6
cookie2,2015-04-14,3
cookie2,2015-04-15,9
cookie2,2015-04-16,7
指定按照第一个字段进行分区
步骤1:
package _core.sourceCodeLearning.partitioner import org.apache.spark.Partitioner
import scala.collection.mutable.HashMap /**
* Author Mr. Guo
* Create 2019/6/23 - 12:19
*/
class UDFPartitioner(args: Array[String]) extends Partitioner { private val partitionMap: HashMap[String, Int] = new HashMap[String, Int]()
var parId = 0
for (arg <- args) {
if (!partitionMap.contains(arg)) {
partitionMap(arg) = parId
parId += 1
}
} override def numPartitions: Int = partitionMap.valuesIterator.length override def getPartition(key: Any): Int = {
val keys: String = key.asInstanceOf[String]
val sub = keys
partitionMap(sub)
}
}
步骤2:
主类测试:
package _core.sourceCodeLearning.partitioner
import org.apache.spark.{SparkConf, TaskContext}
import org.apache.spark.sql.SparkSession
/**
* Author Mr. Guo
* Create 2019/6/23 - 12:21
*/
object UDFPartitionerMain {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[2]").setAppName(this.getClass.getSimpleName)
val ssc = SparkSession
.builder()
.config(conf)
.getOrCreate()
val sc = ssc.sparkContext
sc.setLogLevel("WARN")
val rdd = ssc.sparkContext.textFile("file:///E:\\TestFile\\analyfuncdata.txt")
val transform = rdd.filter(_.split(",").length == 3).map(x => {
val arr = x.split(",")
(arr(0), (arr(1), arr(2)))
})
val keys: Array[String] = transform.map(_._1).collect()
val partiion = transform.partitionBy(new UDFPartitioner(keys))
partiion.foreachPartition(iter => {
println(s"**********分区号:${TaskContext.getPartitionId()}***************")
iter.foreach(r => {
println(s"分区:${TaskContext.getPartitionId()}###" + r._1 + "\t" + r._2 + "::" + r._2._1)
})
})
ssc.stop()
}
}
运行结果:
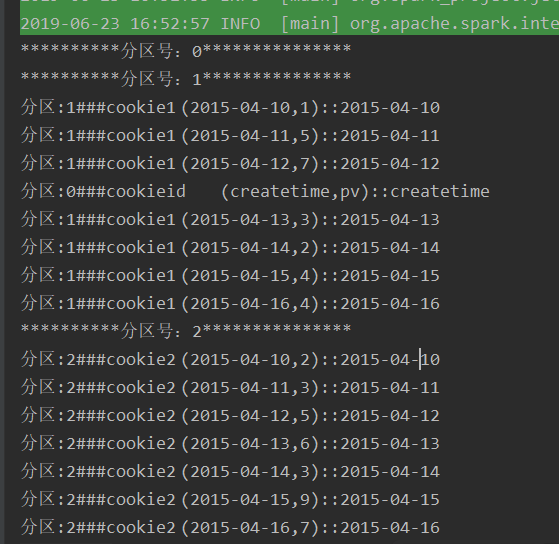
这样就是按照第一个字段进行了分区,当然在分区器的中,对于key是可以根据自己的需求随意的处理,比如添加随机数等等
spark自定义分区器实现的更多相关文章
- Spark自定义分区(Partitioner)
我们都知道Spark内部提供了HashPartitioner和RangePartitioner两种分区策略,这两种分区策略在很多情况下都适合我们的场景.但是有些情况下,Spark内部不能符合咱们的需求 ...
- MapReduce之自定义分区器Partitioner
@ 目录 问题引出 默认Partitioner分区 自定义Partitioner步骤 Partition分区案例实操 分区总结 问题引出 要求将统计结果按照条件输出到不同文件中(分区). 比如:将统计 ...
- kafka 自定义分区器
package cn.xiaojf.kafka.producer; import org.apache.kafka.clients.producer.Partitioner; import org.a ...
- Spark源码分析之分区器的作用
最近因为手抖,在Spark中给自己挖了一个数据倾斜的坑.为了解决这个问题,顺便研究了下Spark分区器的原理,趁着周末加班总结一下~ 先说说数据倾斜 数据倾斜是指Spark中的RDD在计算的时候,每个 ...
- RDD(六)——分区器
RDD的分区器 Spark目前支持Hash分区和Range分区,用户也可以自定义分区,Hash分区为当前的默认分区,Spark中分区器直接决定了RDD中分区的个数.RDD中每条数据经过Shuffle过 ...
- 聊聊Spark的分区、并行度 —— 前奏篇
通过之前的文章[Spark RDD详解],大家应该了解到Spark会通过DAG将一个Spark job中用到的所有RDD划分为不同的stage,每个stage内部都会有很多子任务处理数据,而每个sta ...
- 玩转Kafka的生产者——分区器与多线程
上篇文章学习kafka的基本安装和基础概念,本文主要是学习kafka的常用API.其中包括生产者和消费者, 多线程生产者,多线程消费者,自定义分区等,当然还包括一些避坑指南. 首发于个人网站:链接地址 ...
- kafka producer partitions分区器(七)
消息在经过拦截器.序列化后,就需要确定它发往哪个分区,如果在ProducerRecord中指定了partition字段,那么就不再需要partitioner分区器进行分区了,如果没有指定,那么会根据k ...
- Kafka的接口回调 +自定义分区、拦截器
一.接口回调+自定义分区 1.接口回调:在使用消费者的send方法时添加Callback回调 producer.send(new ProducerRecord<String, String> ...
随机推荐
- JS综合面试题1
function foo(){ getName = function () { alert(1); }; return this; } Foo.getName = function(){ alert( ...
- JavaScript常用技巧之字符串操作
1.首字母大写 str.replace(/\b\w+/g, function (word) { return word.substring(0, 1).toLowerCase() + word.sub ...
- 【Luogu】【关卡2-6】贪心(2017年10月)
任务说明:贪心就是只考虑眼前的利益.对于我们人生来说太贪是不好的,不过oi中,有时是对的. P1090 合并果子 有N堆果子,只能两两合并,每合并一次消耗的体力是两堆果子的权重和,问最小消耗多少体力. ...
- 项目实战 - 混合式App开发
为何要使用混合式开发? 要说为什么使用Hybrid App [混合式开发],就要先了解什么是Native App[原生程序], Web App[网站程序]. Native App 是专门针对某一类移动 ...
- python 操作redis数据
python 操作redis 各种类型的数据 # encoding:utf-8 import redis import time def main(): """ redi ...
- vue 学习六 在组件上使用v-model
其实这个部分应该是属于component,为什么把这玩意单独拿出来呢,原因是它这个东西比较涉及到了vue的事件,以及v-model指令的使用,还是比较综合的.所以就拿出来啦 父组件 <templ ...
- 配置 Linux 静态网卡 & 远程连接 MySQL 问题
1.设置 Linux 为静态网络配置 使用 VMWare 安装好 CentOS 后,将网络适配器设置为 NAT 模式.为了防止 IP 关机重启时候经常变动,需要将网卡信息设置为静态. 修改 /etc/ ...
- php操作redis--集合(set)篇
常用函数:sAdd,sMembers,sPop,sUnion等 应用场景:与list类型类似,是一个列表的功能,不同的是set可以自动排重,提供了一个判断某一个成员是否存在一个set集合内的重要接口. ...
- 状态压缩dp增量统计贡献——cf1238E(好题)
这题的状态设计非常巧妙,因为dp[S]表示的并非当前正确的值,而是维护一个中间量,这个中间量在到达末状态时才正确 当然官方的题解其实更加直观,只不过理解起来其实有点困难 /* 给定一个串s,字符集为2 ...
- Luogu P1738 洛谷的文件夹
P1738 Luogu 发一个链表题解! 仅有24ms,排名第一哦~ 圆圈代表点,每个店有两个指针,一个指向自己兄弟(同级文件夹),另一个指向自己孩子(子文件夹),还有一个保存当前名字. 有点像二叉树 ...