论文笔记之:Graph Attention Networks
Graph Attention Networks
2018-02-06 16:52:49
Abstract:
本文提出一种新颖的 graph attention networks (GATs), 可以处理 graph 结构的数据,利用 masked self-attentional layers 来解决基于 graph convolutions 以及他们的预测 的前人方法(prior methods)的不足。
对象:graph-structured data.
方法:masked self-attentional layers.
目标:to address the shortcomings of prior methods based on graph convolutions or their approximations.
具体方法:By stacking layers in which nodes are able to attend over their neghborhood's feature. We enables specifying different weights to different nodes in a neighborhood, without requiring any kinds of costly matrix operation or depending on knowing the graph structure upfront.
Introduction:
Background:CNN 已经被广泛的应用于各种 grid 结构的数据当中,各种 task 都取得了不错的效果,如:物体检测,语义分割,机器翻译等等。但是,有些数据结构,不是这种 grid-like structure 的,如:3D meshes, social networks, telecommunication networks, biological networks, brain connection。
已经有多个尝试将 RNN 和 graph 结构的东西结合起来,来进行表示。
目前,将 convolution 应用到 the graph domain,常见的有两种做法:
1. spectral approaches
2. non-spectral approaches (spatial based methods)
文章对这两种方法进行了简要的介绍,回顾了一些最近的相关工作。
然后就提到了 Attention Mechanisms,这种思路已经被广泛的应用于各种场景中。其中一个优势就是:they allow for dealing with variable sized inputs, focusing on the most relvant parts of the input to make decisions。当 attention 被用来计算 single sequence 的表示时,通常被称为:self-attention or intra-attention。将这种方法和 CNN/RNN 结合在一起,就可以得到非常好的结果了。
受到最新工作的启发,我们提出了 attention-based architecture 来执行 node classification of graph-structured data。This idea is to compute the hidden representations of each node in the graph, by attending over its neighbors, following a self-attention stategy。这个注意力机制有如下几个有趣的性质:
1. 操作是非常有效的。
2. 可应用到有不同度的 graph nodes,通过给其紧邻指定不同的权重;
3. 这个模型可以直接应用到 inductive learning problems, including tasks where the model has to generalize to completely unseen graphs.
Our approach of sharing a neural network computation across edges is reminiscent of the formulation of relational networks (Santoro et al., 2017), wherein relations between objects (regional features from an image extracted by a convolutional neural network) are aggregated across all object pairs, by employing a shared mechanism.
作者在三个数据集上进行了实验,达到顶尖的效果,表明了 attention-based models 在处理任意结构的 graph 的潜力。
GAT Architecture :
1. Graph Attentional Layer
本文所提出 attentional layer 的输入是 一组节点特征(a set of node features),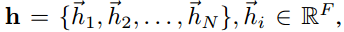 其中,N 是节点的个数,F 是每个节点的特征数。该层产生一组新的节点特征,作为其输出,即:
其中,N 是节点的个数,F 是每个节点的特征数。该层产生一组新的节点特征,作为其输出,即: 。
。
为了得到充分表达能力,将输入特征转换为高层特征,至少我们需要一个可学习的线性转换(one learnable linear transformation)。为了达到该目标,作为初始步骤,一个共享的线性转换,参数化为 weight matrix,W,应用到每一个节点上。我们然后在每一个节点上,进行 self-attention --- a shared attentional mechanism a:计算 attention coefficients

表明 node j's feature 对 node i 的重要性。最 general 的形式,该模型允许 every node to attend on every other node, dropping all structural information. 我们将这种 graph structure 通过执行 masked attention 来注射到该机制当中 --- 我们仅仅对 nodes $j$ 计算 $e_{ij}$,其中,graph 中节点 i 的一些近邻,记为:$N_{i}$。在我们的实验当中,这就是 the first-order neighbors of $i$。
为了使得系数简单的适应不同的节点,我们用 softmax function 对所有的 j 进行归一化:
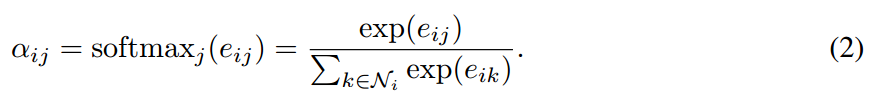
在我们的实验当中,该 attention 机制 a 是一个 single-layer feedforward neural network,参数化为 权重向量  。全部展开,用 attention 机制算出来的系数,可以表达为:
。全部展开,用 attention 机制算出来的系数,可以表达为:

其中,$*^T$ 代表 转置,|| 代表 concatenation operation。
一旦得到了,该归一化的 attention 系数可以用来计算对应特征的线性加权,可以得到最终的每个节点的输出向量:

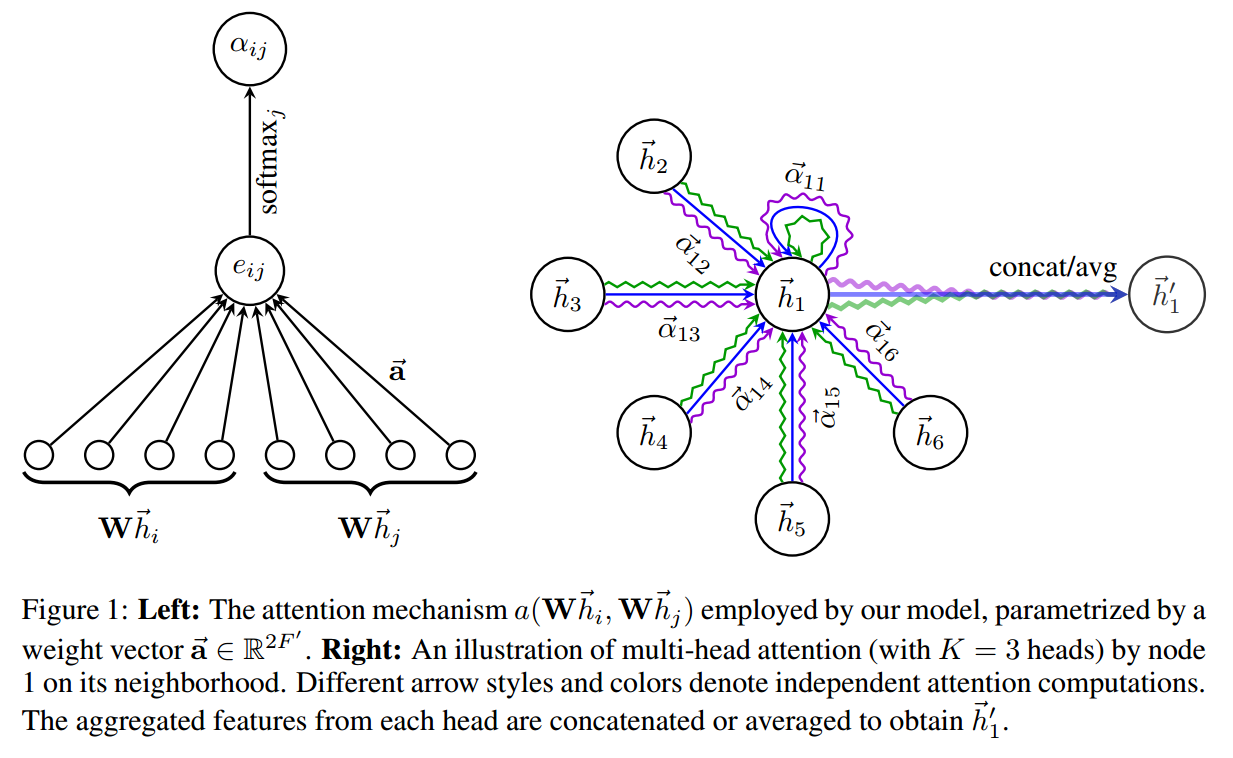
为了稳定 self-attention 的学习过程,我们发现将我们的机制拓展到 multi-head attention 是有好处的,类似于:Attention is all you need. 特别的,K 个独立的 attention 机制执行公式(4)的转换,然后将其特征进行组合,得到下面的特征输出:
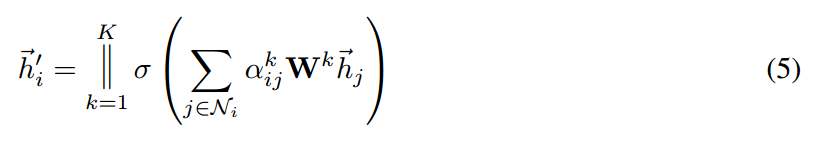
特别的,如果我们执行在 network 的最后输出层执行该 multi-head attention,concatenation 就不再是必须的了,相反的,我们采用 averaging,推迟执行最终非线性,
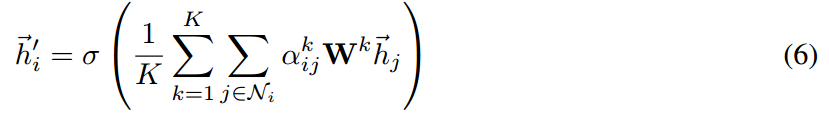
所提出 attention 加权机制的示意图,如下所示:
论文笔记之:Graph Attention Networks的更多相关文章
- 论文解读(GATv2)《How Attentive are Graph Attention Networks?》
论文信息 论文标题:How Attentive are Graph Attention Networks?论文作者:Shaked Brody, Uri Alon, Eran Yahav论文来源:202 ...
- 谣言检测(ClaHi-GAT)《Rumor Detection on Twitter with Claim-Guided Hierarchical Graph Attention Networks》
论文信息 论文标题:Rumor Detection on Twitter with Claim-Guided Hierarchical Graph Attention Networks论文作者:Erx ...
- 论文笔记之:Action-Decision Networks for Visual Tracking with Deep Reinforcement Learning
论文笔记之:Action-Decision Networks for Visual Tracking with Deep Reinforcement Learning 2017-06-06 21: ...
- GRAPH ATTENTION NETWORKS
基本就是第一层concatenate,第二层不concatenate. 相关论文: Semi-Supervised Classification with Graph Convolutional Ne ...
- 论文阅读 Streaming Graph Neural Networks
3 Streaming Graph Neural Networks link:https://dl.acm.org/doi/10.1145/3397271.3401092 Abstract 本文提出了 ...
- 论文笔记:Diffusion-Convolutional Neural Networks (传播-卷积神经网络)
Diffusion-Convolutional Neural Networks (传播-卷积神经网络)2018-04-09 21:59:02 1. Abstract: 我们提出传播-卷积神经网络(DC ...
- 论文笔记(1)-Dropout-Improving neural networks by preventing co-adaptation of feature detectors
Improving neural networks by preventing co-adaptation of feature detectors 是Hinton在2012年6月份发表的,从这篇文章 ...
- 论文笔记之:Attention For Fine-Grained Categorization
Attention For Fine-Grained Categorization Google ICLR 2015 本文说是将Ba et al. 的基于RNN 的attention model 拓展 ...
- 【论文笔记】Progressive Neural Networks 渐进式神经网络
Progressive NN Progressive NN是第一篇我看到的deepmind做这个问题的.思路就是说我不能忘记第一个任务的网络,同时又能使用第一个任务的网络来做第二个任务. 为了不忘记之 ...
随机推荐
- uvalive 4848 Tour Belt
题意: 一个KTO被定义为一个特殊的连通块,这个连通块满足一个要求,这个连通块中的最短的边大于 与这个连通相连的不属于这个连通块的边中的最大值. 给出一个图,统计KTO里面的点有多少个.(一个点可以属 ...
- jack welch:“你们知道了,但是我们做到了”
一.我们发现,只要我们敢于相信自己,敢于朝着那些看似不可能的目标不懈努力,最终会如愿以偿,个人的领袖形象也将因此而确立. 二.一个领导者必须要有魄力.对我来说,这就是一个人能否领导一项业务的分水岭. ...
- PLSA主题模型
主题模型 主题模型这样理解一篇文章的生成过程: 1. 确定文章的K个主题. 2. 重复选择K个主题之一,按主题-词语概率生成词语. 3. 所有词语 ...
- nextjs 服务端渲染请求参数
Post.getInitialProps = async function (context) { const { id } = context.query const res = await fet ...
- formdata 和 Payload 区别
FormData和Payload是浏览器传输给接口的两种格式,这两种方式浏览器是通过Content-Type来进行区分的(了解Content-Type),如果是 application/x-www-f ...
- Windows Services(NT)
本文主要记录什么是Windows Service,及其主要组成?并通过一个列子来创建一个Windows Services,同时,记录几个在查资料碰到的问题. Windows Services全文简称N ...
- 新做了块avr开发板--tft屏研究用
2010-05-04 14:03:00 测试效果不错,使用也方便.
- .NET 常用ORM之Gentle.Net
.Net常用的就是微软的EF框架和Nhibernate,这两个框架用的都比较多就不做详细介绍了,今天我们来看看Gentle.Net,Gentle.Net是一个开源的优秀O/R Mapping的对象持久 ...
- 运行tomcat报Exception in thread "ContainerBackgroundProcessor[StandardEngine[Catalina]]"
解决方法1: 手动设置MaxPermSize大小,如果是linux系统,修改TOMCAT_HOME/bin/catalina.sh,如果是windows系统,修改TOMCAT_HOME/bin/c ...
- python之字符串函数
1. endswith() startswith() # 以什么什么结尾 # 以什么什么开始 test = "alex" v = test.endswith('ex') v = ...