『计算机视觉』Mask-RCNN_推断网络其一:总览
在我们学习的这个项目中,模型主要分为两种状态,即进行推断用的inference模式和进行训练用的training模式。所谓推断模式就是已经训练好的的模型,我们传入一张图片,网络将其分析结果计算出来的模式。
本节我们从demo.ipynb入手,一窥已经训练好的Mask-RCNN模型如何根据一张输入图片进行推断,得到相关信息,即inference模式的工作原理。
一、调用推断网络
网络配置
首先进行配置设定,设定项都被集成进class config中了,自建新的设定只要基础改class并更新属性即可,在demo中我们直接使用COCO的预训练模型所以使用其设置即可,但由于我们想检测单张图片,所以需要更新几个相关数目设定:
# 父类继承了Config类,目的就是记录配置,并在其基础上添加了几个新的属性
class InferenceConfig(coco.CocoConfig):
# Set batch size to 1 since we'll be running inference on
# one image at a time. Batch size = GPU_COUNT * IMAGES_PER_GPU
GPU_COUNT = 1
IMAGES_PER_GPU = 1 config = InferenceConfig()
config.display()
打印出配置如下:
Configurations:
BACKBONE resnet101
BACKBONE_STRIDES [4, 8, 16, 32, 64]
BATCH_SIZE 1
BBOX_STD_DEV [ 0.1 0.1 0.2 0.2]
COMPUTE_BACKBONE_SHAPE None
DETECTION_MAX_INSTANCES 100
DETECTION_MIN_CONFIDENCE 0.7
DETECTION_NMS_THRESHOLD 0.3
FPN_CLASSIF_FC_LAYERS_SIZE 1024
GPU_COUNT 1
GRADIENT_CLIP_NORM 5.0
IMAGES_PER_GPU 1
IMAGE_CHANNEL_COUNT 3
IMAGE_MAX_DIM 1024
IMAGE_META_SIZE 93
IMAGE_MIN_DIM 800
IMAGE_MIN_SCALE 0
IMAGE_RESIZE_MODE square
IMAGE_SHAPE [1024 1024 3]
LEARNING_MOMENTUM 0.9
LEARNING_RATE 0.001
LOSS_WEIGHTS {'rpn_class_loss': 1.0, 'rpn_bbox_loss': 1.0, 'mrcnn_class_loss': 1.0, 'mrcnn_bbox_loss': 1.0, 'mrcnn_mask_loss': 1.0}
MASK_POOL_SIZE 14
MASK_SHAPE [28, 28]
MAX_GT_INSTANCES 100
MEAN_PIXEL [ 123.7 116.8 103.9]
MINI_MASK_SHAPE (56, 56)
NAME coco
NUM_CLASSES 81
POOL_SIZE 7
POST_NMS_ROIS_INFERENCE 1000
POST_NMS_ROIS_TRAINING 2000
PRE_NMS_LIMIT 6000
ROI_POSITIVE_RATIO 0.33
RPN_ANCHOR_RATIOS [0.5, 1, 2]
RPN_ANCHOR_SCALES (32, 64, 128, 256, 512)
RPN_ANCHOR_STRIDE 1
RPN_BBOX_STD_DEV [ 0.1 0.1 0.2 0.2]
RPN_NMS_THRESHOLD 0.7
RPN_TRAIN_ANCHORS_PER_IMAGE 256
STEPS_PER_EPOCH 1000
TOP_DOWN_PYRAMID_SIZE 256
TRAIN_BN False
TRAIN_ROIS_PER_IMAGE 200
USE_MINI_MASK True
USE_RPN_ROIS True
VALIDATION_STEPS 50
WEIGHT_DECAY 0.0001
模型初始化
首先初始化模型,然后载入预训练参数文件,在末尾我可视化了模型,不过真的太长了,所以注释掉了。在第一步初始化时就会根据mode参数的具体值建立计算图,本节介绍的推断网络就是在mode参数设定为"inference"时建立的计算网络。
# Create model object in inference mode.
model = modellib.MaskRCNN(mode="inference", model_dir=MODEL_DIR, config=config) # Load weights trained on MS-COCO
model.load_weights(COCO_MODEL_PATH, by_name=True) # model.keras_model.summary()
检测图片
# Load a random image from the images folder
file_names = next(os.walk(IMAGE_DIR))[2] # 只要是迭代器调用next方法获取值,学习了
image = skimage.io.imread(os.path.join(IMAGE_DIR, random.choice(file_names)))
print(image.shape)
# Run detection
results = model.detect([image], verbose=1) # Visualize results
r = results[0]
visualize.display_instances(image, r['rois'], r['masks'], r['class_ids'],
class_names, r['scores'])
读取一张图片,调用model的detect方法,即可输出结果,最后使用辅助方法可视化结果:

二、推断逻辑概览
inference的前向逻辑如下图所示,我们简单的看一下其计算流程是怎样的,
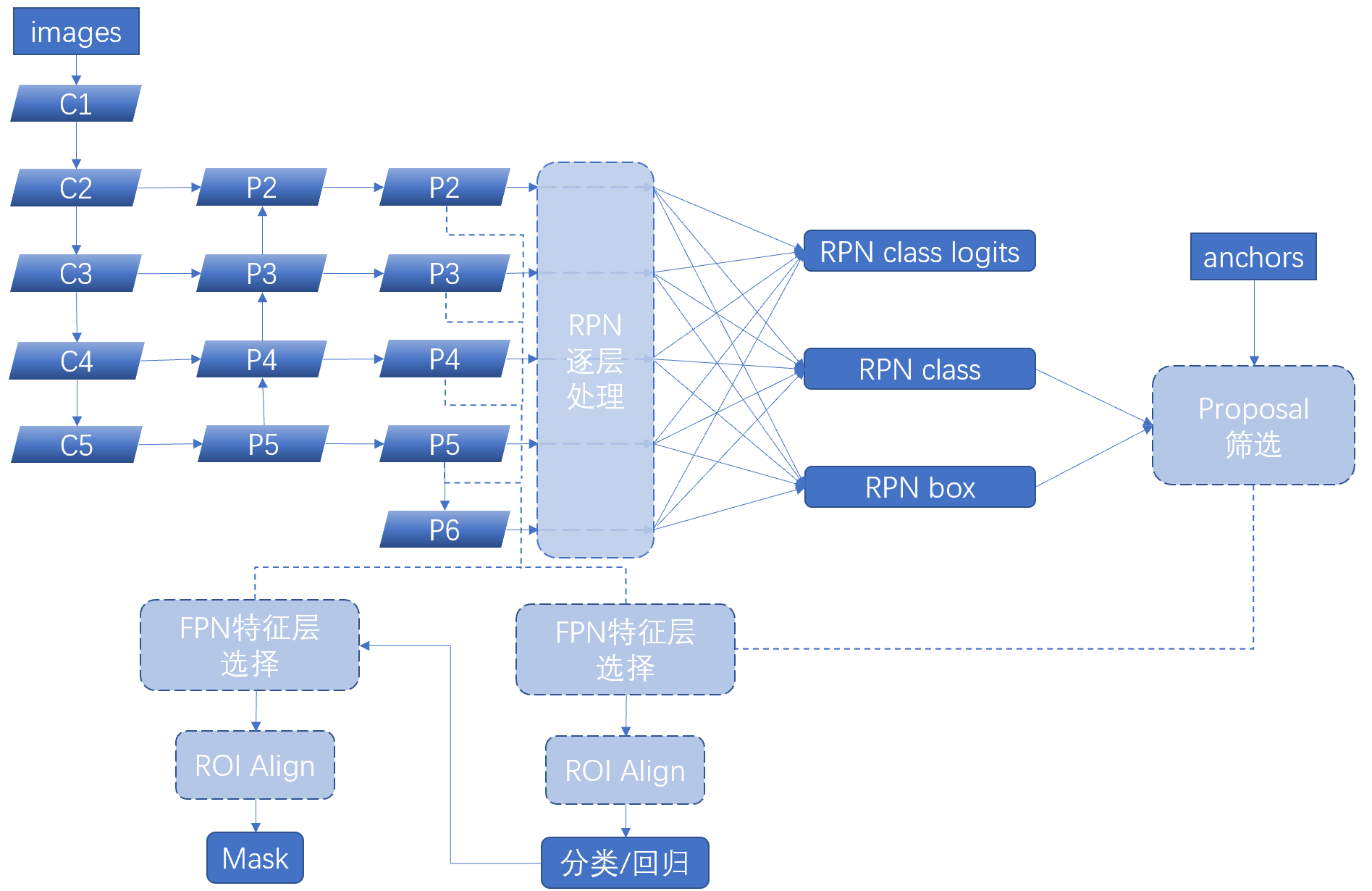
- 左上模块为以ResNet101为基础的FPN特征金字塔网络的特征提取逻辑,可以看到,作者并没有直接将up-down特征使用,而是又做了一次3*3卷积进行了进一步的特征融合。
- 出来的各层FPN特征首先(各自独立地)进入了RPN处理层:根据锚框数目信息确定候选区域的分类(前景背景2分类)和回归结果。
rpn_class:[batch, num_rois, 2]
rpn_bbox:[batch, num_rois, (dy, dx, log(dh), log(dw))] - 有了众多的候选区域,我们将之送入Proposal筛选部分,首先根据前景得分排序进行初筛(配置会指定这一步保留多少候选框),然后为非极大值抑制做准备:用RPN的回归结果修正anchors,值得注意的是anchors都是归一化的这意味着修值之后还需要做检查以防越界,最后非极大值一致,删减的太多了的话就补上[0, 0, 0, 0]达到配置文件要求的数目(非极大值部分会造成同一个batch中不同图片的候选框数目不一致,但是tensor的维数不能参差不齐,所以要补零使得各张图片候选区域数目一致)
rpn_rois:[IMAGES_PER_GPU, num_rois, (y1, x1, y2, x2)]
- 根据候选区的实际大小(归一化候选区需要映射回原图大小)为候选区选择合适的RPN特征层,ROI Align处理(实际上就是抠出来进行双线性插值到指定大小),得到我们需要的众多等大子图
- 对这些子图各自独立的进行分类/回归
mrcnn_class_logits: [batch, num_rois, NUM_CLASSES] classifier logits (before softmax)
mrcnn_class: [batch, num_rois, NUM_CLASSES] classifier probabilities
mrcnn_bbox(deltas): [batch, num_rois, NUM_CLASSES, (dy, dx, log(dh), log(dw))] - 在分类回归之后使用回归结果对候选框进行修正,然后重新进行FPN特征层选择和ROI Align特征提取,最后送入Mask网络,进行Mask生成。
最后,我们希望网络输出下面的张量:
# num_anchors, 每张图片上生成的锚框数量
# num_rois, 每张图片上由锚框筛选出的推荐区数量,
# # 由 POST_NMS_ROIS_TRAINING 或 POST_NMS_ROIS_INFERENCE 规定
# num_detections, 每张图片上最终检测输出框,
# # 由 DETECTION_MAX_INSTANCES 规定 # detections, [batch, num_detections, (y1, x1, y2, x2, class_id, score)]
# mrcnn_class, [batch, num_rois, NUM_CLASSES] classifier probabilities
# mrcnn_bbox, [batch, num_rois, NUM_CLASSES, (dy, dx, log(dh), log(dw))]
# mrcnn_mask, [batch, num_detections, MASK_POOL_SIZE, MASK_POOL_SIZE, NUM_CLASSES]
# rpn_rois, [batch, num_rois, (y1, x1, y2, x2, class_id, score)]
# rpn_class, [batch, num_anchors, 2]
# rpn_bbox [batch, num_anchors, 4]
具体每种张量的意义我们会在源码分析中一一介绍。
『计算机视觉』Mask-RCNN_推断网络其一:总览的更多相关文章
- 『计算机视觉』经典RCNN_其二:Faster-RCNN
项目源码 一.Faster-RCNN简介 『cs231n』Faster_RCNN 『计算机视觉』Faster-RCNN学习_其一:目标检测及RCNN谱系 一篇讲的非常明白的文章:一文读懂Faster ...
- 『计算机视觉』经典RCNN_其一:从RCNN到Faster-RCNN
RCNN介绍 目标检测-RCNN系列 一文读懂Faster RCNN 一.目标检测 1.两个任务 目标检测可以拆分成两个任务:识别和定位 图像识别(classification)输入:图片输出:物体的 ...
- 『计算机视觉』Mask-RCNN_推断网络其二:基于ReNet101的FPN共享网络暨TensorFlow和Keras交互简介
零.参考资料 有关FPN的介绍见『计算机视觉』FPN特征金字塔网络. 网络构架部分代码见Mask_RCNN/mrcnn/model.py中class MaskRCNN的build方法的"in ...
- 『计算机视觉』Mask-RCNN_推断网络其四:FPN和ROIAlign的耦合
一.模块概述 上节的最后,我们进行了如下操作获取了有限的proposal, # [IMAGES_PER_GPU, num_rois, (y1, x1, y2, x2)] # IMAGES_PER_GP ...
- 『计算机视觉』Mask-RCNN
一.Mask-RCNN流程 Mask R-CNN是一个实例分割(Instance segmentation)算法,通过增加不同的分支,可以完成目标分类.目标检测.语义分割.实例分割.人体姿势识别等多种 ...
- 『计算机视觉』Mask-RCNN_推断网络其六:Mask生成
一.Mask生成概览 上一节的末尾,我们已经获取了待检测图片的分类回归信息,我们将回归信息(即待检测目标的边框信息)单独提取出来,结合金字塔特征mrcnn_feature_maps,进行Mask生成工 ...
- 『计算机视觉』Mask-RCNN_推断网络终篇:使用detect方法进行推断
一.detect和build 前面多节中我们花了大量笔墨介绍build方法的inference分支,这节我们看看它是如何被调用的. 在dimo.ipynb中,涉及model的操作我们简单进行一下汇总, ...
- 『计算机视觉』Mask-RCNN_推断网络其三:RPN锚框处理和Proposal生成
一.RPN锚框信息生成 上文的最后,我们生成了用于计算锚框信息的特征(源代码在inference模式中不进行锚框生成,而是外部生成好feed进网络,training模式下在向前传播时直接生成锚框,不过 ...
- 『计算机视觉』Mask-RCNN_训练网络其三:训练Model
Github地址:Mask_RCNN 『计算机视觉』Mask-RCNN_论文学习 『计算机视觉』Mask-RCNN_项目文档翻译 『计算机视觉』Mask-RCNN_推断网络其一:总览 『计算机视觉』M ...
- 『计算机视觉』Mask-RCNN_训练网络其二:train网络结构&损失函数
Github地址:Mask_RCNN 『计算机视觉』Mask-RCNN_论文学习 『计算机视觉』Mask-RCNN_项目文档翻译 『计算机视觉』Mask-RCNN_推断网络其一:总览 『计算机视觉』M ...
随机推荐
- webpack插件配置(一) webpack-dev-server 路径配置
本文的路径配置主要涉及到webpack.config.js文件中devServer与output两个选项的配置 webpack-dev-server定义 webpack-dev-server主要是启动 ...
- linux golang
wget -c http://www.golangtc.com/static/go/go1.3.linux-386.tar.gz #下载32位Linux的够源码包 tar -zxvf go1.1.li ...
- SPA中,Node路由优先级高于React路由
一.问题描述 在一场面试中,面试官问到了React和Node路由之间的关系. 现在SPA(单页面应用)的使用越来越广. Node(后台)和React(前端)都有自己的路由,当我页面访问一个URL的时候 ...
- coercing to Unicode: need string or buffer, int found报错
转为string类型 str(a)
- Python使用win32com实现的模拟浏览器功能
# -*- coding:UTF- -*- #!/user/bin/env python ''' Created on -- @author: chenzehe ''' import win32com ...
- 有了art-template,如有神助
<div class="form-group col-lg-12"> <label class="control-label col-lg-3 text ...
- Android集成人脸识别demo分享
本应用来源于虹软人工智能开放平台,人脸识别技术工程如何使用? 1.下载代码 git clone https://github.com/andyxm/ArcFaceDemo.git 2.下载虹软人脸识别 ...
- pip切换国内源(解决pipenv lock特别慢)
切换方法参考https://blog.csdn.net/chenghuikai/article/details/55258957 实测,确实解决了pipenv这个问题,否则只能--skip-lock. ...
- git 放弃本地修改
本文以转移至本人的个人博客,请多多关注! 如果在修改时发现修改错误,而要放弃本地修改时, 一, 未使用 git add 缓存代码时. 可以使用 git checkout -- filepathnam ...
- Mybatis中resultType理解