Pytorch 之 backward
首先看这个自动求导的参数:
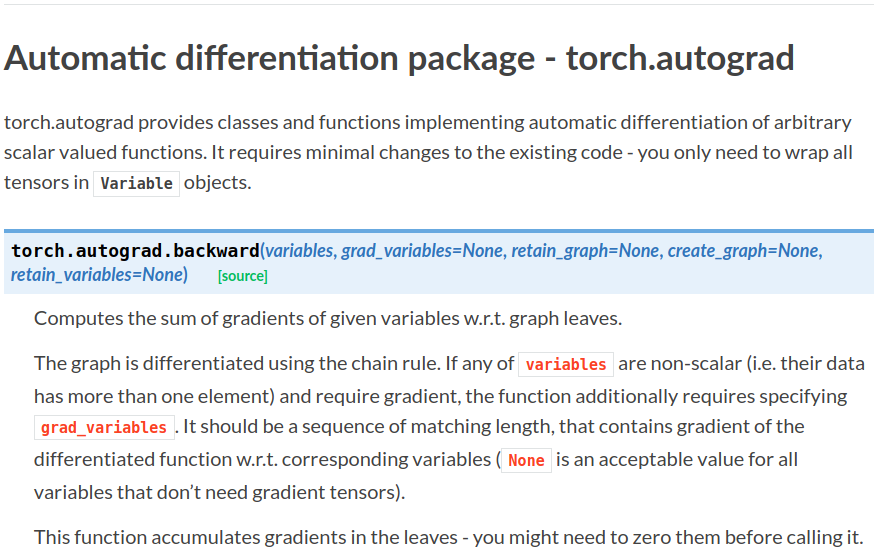
- grad_variables:形状与variable一致,对于
y.backward(),grad_variables相当于链式法则dz/dx=dz/dy × dy/dx 中的 dz/dy。grad_variables也可以是tensor或序列。 - retain_graph:反向传播需要缓存一些中间结果,反向传播之后,这些缓存就被清空,可通过指定这个参数不清空缓存,用来多次反向传播。
- create_graph:对反向传播过程再次构建计算图,可通过
backward of backward实现求高阶导数。
注意variables 和 grad_variables 都可以是 sequence。对于scalar(标量,一维向量)来说可以不用填写grad_variables参数,若填写的话就相当于系数。若variables非标量则必须填写grad_variables参数。下面结合参考示例来解释一下这个参数怎么用。
先说一下自己总结的一个通式,适用于所有形式:
 对于此式,x的梯度x.grad为
对于此式,x的梯度x.grad为 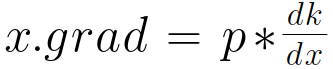
1.scalar标量
注意参数requires_grad=True让其成为一个叶子节点,具有求导功能。

手动求导结果:

代码实现:
import torch as t
from torch.autograd import Variable as v a = v(t.FloatTensor([2, 3]), requires_grad=True) # 注意这里为一维,标量
b = a + 3
c = b * b * 3
out = c.mean()
out.backward(retain_graph=True) # 这里可以不带参数,默认值为‘1’,由于下面我们还要求导,故加上retain_graph=True选项
结果:
a.grad
Out[184]:
Variable containing:
15
18
[torch.FloatTensor of size 1x2]
结果与手动计算一样
backward带参数呢?此时的参数为系数
将梯度置零:
a.grad.data.zero_()
再次求导验证输入参数仅作为系数:
n.backward(torch.Tensor([[2,3]]), retain_graph=True)
结果:(2和3应该分别作为系数相乘)
a.grad
Out[196]:
Variable containing:
30
54
[torch.FloatTensor of size 1x2]
验证了我们的想法。
2.张量
import torch
from torch.autograd import Variable as V m = V(torch.FloatTensor([[2, 3]]), requires_grad=True) # 注意这里有两层括号,非标量
n = V(torch.zeros(1, 2))
n[0, 0] = m[0, 0] ** 2
n[0, 1] = m[0, 1] ** 3
求导 :(此时的[[1, 1]]为系数,仅仅作为简单乘法的系数),注意 retain_graph=True,下面我们还要求导,故置为True。
n.backward(torch.Tensor([[1,1]]), retain_graph=True)
结果:
m.grad
Out[184]:
Variable containing:
4 27
[torch.FloatTensor of size 1x2]
将梯度置零:
m.grad.data.zero_()
再次求导验证输入参数仅作为系数:
n.backward(torch.Tensor([[2,3]]))
结果:4,27 × 2,3 =8,81 验证了系数这一说法
m.grad
Out[196]:
Variable containing:
8 81
[torch.FloatTensor of size 1x2]
注意backward参数,由于是非标量,不填写参数将会报错。
3. 另一种重要情形
之前我们求导都相当于是loss对于x的求导,没有接触中间过程。然而对于下面的链式法则我们知道如果知道中间的导数结果,也可以直接计算对于输入的导数。而grad_variables参数在某种意义上就是中间结果。即上面都是z.backward()之类,那么考虑y.backward(b) 或 y.backward(x)是什么意思呢?
下面给出一个例子解释清楚:
import torch
from torch.autograd import Variable
x = Variable(torch.randn(3), requires_grad=True)
y = Variable(torch.randn(3), requires_grad=True)
z = Variable(torch.randn(3), requires_grad=True)
print(x)
print(y)
print(z) t = x + y
l = t.dot(z)
结果:
# x
Variable containing:
0.9168
1.3483
0.4293
[torch.FloatTensor of size 3] # y
Variable containing:
0.4982
0.7672
1.5884
[torch.FloatTensor of size 3] # z
Variable containing:
0.1352
-0.4037
-0.2425
[torch.FloatTensor of size 3]
在调用 backward 之前,可以先手动求一下导数,应该是:
当我们打印x.grad和y.grad时都是 x.grad = y.grad = z。 当我们打印z.grad 时为 z.grad = t = x + y。这里都没有问题。重要的来了:
先置零:
x.grad.data.zero_()
y.grad.data.zero_()
z.grad.data.zero_()
看看下面这个情况:
t.backward(z)
print(x.grad)
print(y.grad)
print(z.grad)
此时的结果为:
x和y的导数仍然与上面一样为z。而z的导数为0。解释:
t.backward(z): 若求x.grad: z * dt/dx 即为dl/dt × dt/dx=z
若求y.grad: z * dt/dy 即为dl/dt × dt/dy=z
若求z.grad: z * dt/dz 即为dl/dt × dt/dz = z×0 = 0
再验证一下我们的想法:
清零后看看下面这种情况:
t.backward(x)
print(x.grad)
print(y.grad)
print(z.grad)
x和y的导数仍然相等为x。而z的导数为0。解释:
t.backward(x): 若求x.grad: x * dt/dx 即为x × 1 = x
若求y.grad: x * dt/dy 即为x × 1 = x
若求z.grad: x * dt/dz 即为x × 0 = 0
验证成功。
另:k.backward(p)接受的参数p必须要和k的大小一样。这一点也可以从通式看出来。
参考:
PyTorch 的 backward 为什么有一个 grad_variables 参数?
PyTorch 中文网
PyTorch中的backward [转]
Calculus on Computational Graphs: Backpropagation
Pytorch 之 backward的更多相关文章
- ARTS-S pytorch中backward函数的gradient参数作用
导数偏导数的数学定义 参考资料1和2中对导数偏导数的定义都非常明确.导数和偏导数都是函数对自变量而言.从数学定义上讲,求导或者求偏导只有函数对自变量,其余任何情况都是错的.但是很多机器学习的资料和开源 ...
- Pytorch autograd,backward详解
平常都是无脑使用backward,每次看到别人的代码里使用诸如autograd.grad这种方法的时候就有点抵触,今天花了点时间了解了一下原理,写下笔记以供以后参考.以下笔记基于Pytorch1.0 ...
- pytorch autograd backward函数中 retain_graph参数的作用,简单例子分析,以及create_graph参数的作用
retain_graph参数的作用 官方定义: retain_graph (bool, optional) – If False, the graph used to compute the grad ...
- pytorch的backward
在学习的过程中遇见了一个问题,就是当使用backward()反向传播时传入参数的问题: net.zero_grad() #所有参数的梯度清零 output.backward(Variable(t.on ...
- Pytorch中torch.autograd ---backward函数的使用方法详细解析,具体例子分析
backward函数 官方定义: torch.autograd.backward(tensors, grad_tensors=None, retain_graph=None, create_graph ...
- 关于Pytorch中autograd和backward的一些笔记
参考自<Pytorch autograd,backward详解>: 1 Tensor Pytorch中所有的计算其实都可以回归到Tensor上,所以有必要重新认识一下Tensor. 如果我 ...
- 深度学习框架PyTorch一书的学习-第三章-Tensor和autograd-2-autograd
参考https://github.com/chenyuntc/pytorch-book/tree/v1.0 希望大家直接到上面的网址去查看代码,下面是本人的笔记 torch.autograd就是为了方 ...
- 深度学习框架PyTorch一书的学习-第一/二章
参考https://github.com/chenyuntc/pytorch-book/tree/v1.0 希望大家直接到上面的网址去查看代码,下面是本人的笔记 pytorch的设计遵循tensor- ...
- TensorFlow2.0初体验
TF2.0默认为动态图,即eager模式.意味着TF能像Pytorch一样不用在session中才能输出中间参数值了,那么动态图和静态图毕竟是有区别的,tf2.0也会有写法上的变化.不过值得吐槽的是, ...
随机推荐
- LOJ #2721. 「NOI2018」屠龙勇士(set + exgcd)
题意 LOJ #2721. 「NOI2018」屠龙勇士 题解 首先假设每条龙都可以打死,每次拿到的剑攻击力为 \(ATK\) . 这个需要支持每次插入一个数,查找比一个 \(\le\) 数最大的数(或 ...
- 【Luogu4921】情侣?给我烧了!(组合计数)
[Luogu4921]情侣?给我烧了!(组合计数) 题面 洛谷 题解 很有意思的一道题目. 直接容斥?怎么样都要一个平方复杂度了. 既然是恰好\(k\)对,那么我们直接来做: 首先枚举\(k\)对人出 ...
- 【转】#pragma pack(push,1)与#pragma pack(1)的区别
这是给编译器用的参数设置,有关结构体字节对齐方式设置, #pragma pack是指定数据在内存中的对齐方式. #pragma pack (n) 作用:C编译器将按照n个字节对 ...
- 逆向---02.je & jmp & jnz 、OD调试
上一篇:逆向---01.Nop.中文字符串搜索.保存修改后程序 OD调试基础:(01.02篇练手工具:https://pan.baidu.com/s/1kW2qlCz) nop是删除跳转,你别问我,我 ...
- JavaScript -- throw、try 和 catch
try 语句测试代码块的错误. catch 语句处理错误. throw 语句创建自定义错误. 很想java哦. <!DOCTYPE html> <html> <head& ...
- 循环viewpager
如果viewpager listadapter小于三个.用这个移除异常. for (View view : viewList) { ViewGroup p = (ViewGro ...
- c 的内存分配与释放原则: 通常应遵循“谁malloc,谁free”的原则。
通常应遵循“谁malloc,谁free”的原则. ------------------------ 一位大神的话. 2013-02-09
- gcc/g++
$gcc -g -Wall -ansi -pedantic main.cpp -lstdc++ -std=c++11 -lpthread -o xmain
- (java保留n位小数)precise math function 北京信息科技大学第十届ACM程序设计竞赛 第2题
precise math function Time Limit : 3000/1000ms (Java/Other) Memory Limit : 65535/32768K (Java/Othe ...
- redis 一主二从三哨兵
总体部署 一主二从三哨兵 ip地址分配分别为 主 127.0.0.1:6379 从 127.0.0.1:6389 从 127.0.0.1:6399 哨兵 127.0.0.1:26379 哨兵 127. ...