Python:requests库、BeautifulSoup4库的基本使用(实现简单的网络爬虫)
Python:requests库、BeautifulSoup4库的基本使用(实现简单的网络爬虫)
一、requests库的基本使用
requests是python语言编写的简单易用的HTTP库,使用起来比urllib更加简洁方便。
requests是第三方库,使用前需要通过pip安装。
pip install requests
1.基本用法:
import requests
#以百度首页为例
response = requests.get('http://www.baidu.com')
#response对象的属性
print(response.status_code) # 打印状态码
print(response.url) # 打印请求url
print(response.headers) # 打印头信息
print(response.cookies) # 打印cookie信息
print(response.text) #以文本形式打印网页源码
print(response.content) #以字节流形式打印
运行后显示:
状态码:200 url:www.baidu.com #输出headers信息、cookie信息以及网页源码信息 <RequestsCookieJar[<Cookie BDORZ=27315 for .baidu.com/>]>
2.各种请求方式(HTTP测试网站:http://httpbin.org/)
import requests
requests.get('http://httpbin.org/get')
requests.post('http://httpbin.org/post')
requests.put('http://httpbin.org/put')
requests.delete('http://httpbin.org/delete')
requests.head('http://httpbin.org/get')
requests.options('http://httpbin.org/get')
3.response对象的方法
json():能够在HTTP响应内容中解析存在的JSON数据,方便解析HTTP的操作。
raise_for_status():只要返回的请求状态status_code不是200,则产生异常。用于try-except语句。
requests会产生几种常用异常:
ConnectionError异常:网络异常,如DNS查询失败、拒绝连接等。
HTTPError异常:无效HTTP响应。
Timeout异常:请求URL超时。
TooManyRedirects异常:请求超过了设定的最大重定向次数。
获取一个网页的内容的函数建议使用如下代码:
def getHTMLText(url):
try:
r=requests.get(url,timeout=30)
r.raise_for_status()#如果状态不是200,抛出异常
r.encoding='utf-8'#无论原来用什么编码都改为utf-8
return r.text
except:
return ''
二、beautifulsoup4库的基本使用
beautifulsoup4库用于解析和处理HTML和XML。其最大优点是能根据HTML和XML语法建立解析树,提取有用信息。
beautifulsoup4也是第三方库,使用前同样需要通过pip安装。
pip install beautifulsoup4
注意:beautifulsoup4库和beautifulsoup库不能混为一谈,后者由于年久失修,已经不再维护了。
在使用beautifulsoup4库之前需要进行引用:
from bs4 import BeautifulSoup
使用BeautifulSoup()创建一个BeautifulSoup对象。
import requests
from bs4 import BeautifulSoup
r=requests.get('http://www.baidu.com')
r.encoding='utf-8'
soup=BeautifulSoup(r.text,'html.parser')
print(type(soup))
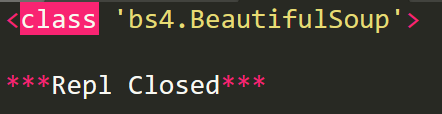
BeautifulSoup对象是一个树形结构,包含HTML页面中每一个Tag标签,这些标签构成BeautifulSoup对象的属性。BeautifulSoup对象常用属性如下:
soup.head:HTML页面的<head>内容
soup.title:HTML页面的标题内容,在<head>之中
soup.body:HTML页面的<body>内容
soup.p:HTML页面第一个<p>内容
soup.strings:HTML页面所有呈现在web上的字符串内容
soup.stripped_strings:HTML页面所有呈现在web上的非空格字符串内容
#输出百度首页title标签的内容
import requests
from bs4 import BeautifulSoup
r=requests.get('http://www.baidu.com')
r.encoding='utf-8'
soup=BeautifulSoup(r.text,'html.parser')
print(soup.title)
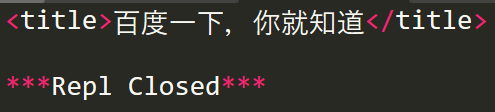
beautifulsoup4库中每一个Tag标签称为一个Tag对象,标签对象的常用属性如下:
name:标签本身的名称,是一个字符串,如a。
attrs:字典,包含了标签的全部属性。
contents:列表,包含当前标签下所有子标签的内容。
string:字符串,标签所包围的文本,网页中真实的文字。
import requests
from bs4 import BeautifulSoup
r=requests.get('http://www.baidu.com')
r.encoding='utf-8'
soup=BeautifulSoup(r.text,'html.parser')
print(soup.a)
print(soup.a.name)
print(soup.a.attrs)
print(soup.a.string)
print(soup.p.contents)

如果需要遍历整个HTML页面列出标签对应的所有内容,可以用到find_all()方法。
BeautifulSoup.find_all( name , attrs , recursive , string , limit )
根据参数找对应标签,返回类型为列表。参数如下:
name:根据标签名查找。
attrs:根据标签属性值查找,需要列出属性名和值,用JSON表示。
recursive:设置查找层次,只查找当前标签下一层时使用recursive=False。
string:根据关键字查找string属性内容,采用string=开始。
limit:返回结果个数,默认返回全部结果。
import requests
from bs4 import BeautifulSoup
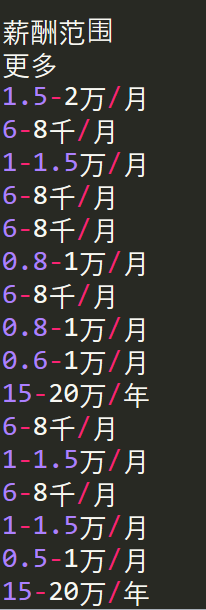
#爬取前程无忧网软件工程师薪资
r=requests.get('https://m.51job.com/search/joblist.php?jobarea=180400,180200&keyword=%E8%BD%AF%E4%BB%B6%E5%B7%A5%E7%A8%8B%E5%B8%88&partner=webmeta')
r.encoding='utf-8'
soup=BeautifulSoup(r.text,'html.parser')
allsalary=soup.find_all('em')
for i in allsalary:
if len(i.text)==0:
continue
print(i.text)
Python:requests库、BeautifulSoup4库的基本使用(实现简单的网络爬虫)的更多相关文章
- 采用requests库构建简单的网络爬虫
Date: 2019-06-09 Author: Sun 我们分析格言网 https://www.geyanw.com/, 通过requests网络库和bs4解析库进行爬取此网站内容. 项目操作步 ...
- python3.6 urllib.request库实现简单的网络爬虫、下载图片
#更新日志:#0418 爬取页面商品URL#0421 更新 添加爬取下载页面图片功能#0423 更新 添加发送邮件功能# 优化 爬虫异常处理.错误页面及空页面处理# 优化 爬虫关键字黑名单.白名单,提 ...
- 【网络爬虫入门01】应用Requests和BeautifulSoup联手打造的第一条网络爬虫
[网络爬虫入门01]应用Requests和BeautifulSoup联手打造的第一条网络爬虫 广东职业技术学院 欧浩源 2017-10-14 1.引言 在数据量爆发式增长的大数据时代,网络与用户的沟 ...
- Python 基础教程 —— 网络爬虫入门篇
前言 Python 是一种解释型.面向对象.动态数据类型的高级程序设计语言,它由 Guido van Rossum 于 1989 年底发明,第一个公开发行版发行于 1991 年.自面世以后,Pytho ...
- python 3.x 爬虫基础---常用第三方库(requests,BeautifulSoup4,selenium,lxml )
python 3.x 爬虫基础 python 3.x 爬虫基础---http headers详解 python 3.x 爬虫基础---Urllib详解 python 3.x 爬虫基础---常用第三方库 ...
- python怎么安装requests、beautifulsoup4等第三方库
零基础学习python最大的难题之一就是安装所有需要的软件,下面来简单介绍一下如何安装用pip安装requests.beautifulsoup4等第三方库: 方法/步骤 点击开始,在运行里 ...
- $python爬虫系列(2)—— requests和BeautifulSoup库的基本用法
本文主要介绍python爬虫的两大利器:requests和BeautifulSoup库的基本用法. 1. 安装requests和BeautifulSoup库 可以通过3种方式安装: easy_inst ...
- Python网络爬虫——BeautifulSoup4库的使用
使用requests库获取html页面并将其转换成字符串之后,需要进一步解析html页面格式,提取有用信息. BeautifulSoup4库,也被成为bs4库(后皆采用简写)用于解析和处理html和x ...
- 大概看了一天python request源码。写下python requests库发送 get,post请求大概过程。
python requests库发送请求时,比如get请求,大概过程. 一.发起get请求过程:调用requests.get(url,**kwargs)-->request('get', url ...
随机推荐
- JavaScript数组去重的7种方式
1.利用额外数组 function unique(array) { if (!Array.isArray(array)) return; let newArray = []; fo ...
- moment.js 默认使用服务器时间
在前端使用Date对象获取当前时间的时候,该时间是客户端的时间.但是该时间可以被用户修改,所以我们一般情况下并不想要这个时间.如果每一次获取时间的时候都请求一下服务器,那么将会对服务器造成不必要的压力 ...
- VMware“该虚拟机似乎正在使用中”
问题现象: 在用VMware虚拟机的时候,有时会发现打开虚拟机时提示"该虚拟机似乎正在使用中.如果该虚拟机未在使用,请按"获取所有权(T)"按钮获取它的所有权.否则,请按 ...
- vue 页面间使用路由传参数,刷新页面后获取不到参数的问题
情况 情况再简单说明一下: 有三个页面(a-列表页面,b-内页1,c-内页2),页面a->页面b->页面c有参数传递.从a进入b后,刷新b页面拿不到a页面传进来的参数.或者b页面再进入c页 ...
- 大数据学习笔记——Java篇之基础知识
Java / 计算机基础知识整理 在进行知识梳理同时也是个人的第一篇技术博客之前,首先祝贺一下,经历了一年左右的学习,从完完全全的计算机小白,现在终于可以做一些产出了!可以说也是颇为感慨,个人认为,学 ...
- 《Dotnet9》系列-开源C# WPF控件库2《Panuon.UI.Silver》强力推荐
时间如流水,只能流去不流回! 点赞再看,养成习惯,这是您给我创作的动力! 本文 Dotnet9 https://dotnet9.com 已收录,站长乐于分享dotnet相关技术,比如Winform.W ...
- C++程序设计实验考试准备资料(2019级秋学期)
程序设计实验考试准备资料 ——傲珂 #include<bits/stdc++.h> C++常用函数: <math.h>头文件 floor() 函数原型:double floor ...
- C语言程序设计-现代方法(笔记1)
第一章 C语言概述 1.C语言的历史(1.1) 起源:贝尔实验室开发的UNIX操作系统的副产品.标准化:C89和C99.基于C的语言:C++,Java,C#,Perl. 2.C语言的优缺点(1.2) ...
- 升级sharepoint2013遇到的坑
现在要将sharepoint2010,ProjectServer2010升级到2016的版本,需要先升级到2013的版本. 按照官方文档,瞎搞将sharepoint2010升级到2013的版本,中间出 ...
- iOS-关于一些取整方式
1. 直接转化 float k = 1.6; int a = (int)k; NSLog(@"a = %d",a); 输出结果是1,(int) 是强制类型转化,直接丢弃浮点数的小数 ...