使用python实现哈希表、字典、集合
哈希表
哈希表(Hash Table, 又称为散列表),是一种线性表的存储结构。哈希表由一个直接寻址表和一个哈希函数组成。哈希函数h(k)将元素关键字k作为自变量,返回元素的存储下标。
简单哈希函数:
- 除法哈希:h(k) = k mod m
- 乘法哈希:h(k) = floor(m(kA mod 1)) 0<A<1
假设有一个长度为7的数组,哈希函数h(k) = k mod 7,元素集合{14, 22, 3, 5}的存储方式如下图:

哈希冲突
由于哈希表的大小是有限的,而要存储的值的总数量是无限的,因此对于任何哈希函数,都会出现两个不同的元素映射到同一个位置上的情况,这种情况叫做哈希冲突。
比如:h(k) = k mod 7, h(0) = h(7) = h(14) = ...
解决哈希冲突--开放寻址法
开放寻址法:如果哈希函数返回的位置已经有值,则可以向后探查新的位置来存储这个值
- 线性探查:如果位置i被占用,则探查i+1, i+2,...
- 二次探查:如果位置i被占用,则探查i+12, i-12, i+22, i-22,...
- 二度哈希:有n个哈希函数,当使用第一个哈希函数h1发生冲突时,则尝试使用h2, h3,...
解决哈希冲突--拉链法
拉链法:哈希表每一个位置都连接一个链表,当冲突发生时,冲突的元素将被加到该位置链表的最后。
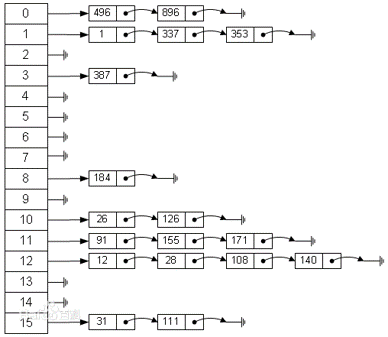
哈希表的实现
class Array(object):
def __init__(self, size=32, init=None):
self._size = size
self._items = [init] * size
def __getitem__(self, index):
return self._items[index]
def __setitem__(self, index, value):
self._items[index] = value
def __len__(self):
return self._size
def clear(self, value=None):
for i in range(len(self._items)):
self._items[i] = value
def __iter__(self):
for item in self._items:
yield item
class Slot(object):
"""
定义一个 hash 表数组的槽(slot 这里指的就是数组的一个位置)
hash table 就是一个数组,每个数组的元素(也叫slot槽)是一个对象,对象包含两个属性 key 和 value。
注意,一个槽有三种状态,看你能否想明白。相比链接法解决冲突,探查法删除一个 key 的操作稍微复杂。
1.从未使用 HashMap.UNUSED。此槽没有被使用和冲突过,查找时只要找到 UNUSED 就不用再继续探查了
2.使用过但是 remove 了,此时是 HashMap.EMPTY,该探查点后边的元素仍然可能是有key的,需要继续查找
3.槽正在使用 Slot 节点
"""
def __init__(self, key, value):
self.key, self.value = key, value
class HashTable(object):
UNUSED = None # 没被使用过
EMPTY = Slot(None, None) # 使用却被删除过
def __init__(self):
self._table = Array(8, init=HashTable.UNUSED) # 保持 2*i 次方
self.length = 0
@property
def _load_factor(self):
# load_factor 超过 0.8 重新分配
return self.length / float(len(self._table))
def __len__(self):
return self.length
# 进行哈希
def _hash(self, key):
return abs(hash(key)) % len(self._table)
# 查找key
def _find_key(self, key):
"""
解释一个 slot 为 UNUSED 和 EMPTY 的区别
因为使用的是二次探查的方式,假如有两个元素 A,B 冲突了,
首先A hash 得到是 slot 下标5,A 放到了第5个槽,之后插入 B 因为冲突了,所以继续根据二次探查方式放到了 slot下标8。
然后删除 A,槽 5 被置为 EMPTY。然后我去查找 B,
第一次 hash 得到的是 槽5,但是这个时候我还是需要第二次计算 hash 才能找到 B。
但是如果槽是 UNUSED 我就不用继续找了,我认为 B 就是不存在的元素。这个就是 UNUSED 和 EMPTY 的区别。
"""
origin_index = index = self._hash(key) # origin_index 判断是否又走到了起点,如果查找一圈了都找不到则无此元素
_len = len(self._table)
while self._table[index] is not HashTable.UNUSED:
if self._table[index] is HashTable.EMPTY: # 注意如果是 EMPTY,继续寻找下一个槽
index = (index * 5 + 1) % _len
if index == origin_index:
break
continue
if self._table[index].key == key: # 找到了key
return index
else:
index = (index * 5 + 1) % _len # 没有找到继续找下一个位置
if index == origin_index:
break
return None
# 找能插入的槽
def _find_slot_for_insert(self, key):
index = self._hash(key)
_len = len(self._table)
while not self._slot_can_insert(index): # 直到找到一个可以用的槽
index = (index * 5 + 1) % _len
return index
# 槽是否能插入
def _slot_can_insert(self, index):
return self._table[index] is HashTable.EMPTY or self._table[index] is HashTable.UNUSED
# in operator,实现之后可以使用 in 操作符判断
def __contains__(self, key):
index = self._find_key(key)
return index is not None
# 添加元素
def add(self, key, value):
if key in self: # update
index = self._find_key(key)
self._table[index].value = value
return False
else:
index = self._find_slot_for_insert(key)
self._table[index] = Slot(key, value)
self.length += 1
if self._load_factor >= 0.8:
self._rehash()
return True
# 槽不够时,重哈希
def _rehash(self):
old_table = self._table
newsize = len(self._table) * 2
self._table = Array(newsize, HashTable.UNUSED)
self.length = 0
for slot in old_table:
if slot is not HashTable.UNUSED and slot is not HashTable.EMPTY:
index = self._find_slot_for_insert(slot.key)
self._table[index] = slot
self.length += 1
# 获取值
def get(self, key, default=None):
index = self._find_key(key)
if index is None:
return default
else:
return self._table[index].value
# 移除
def remove(self, key):
index = self._find_key(key)
if index is None:
raise KeyError()
value = self._table[index].value
self.length -= 1
self._table[index] = HashTable.EMPTY
return value
# 遍历
def __iter__(self):
for slot in self._table:
if slot not in (HashTable.EMPTY, HashTable.UNUSED):
yield slot.key
哈希表的使用
h = HashTable()
h.add('a', 0)
h.add('b', 1)
h.add('c', 2)
print(len(h)) #
print(h.get('a')) #
print(h.get('b')) #
print(h.get('hehe')) # None
h.remove('a')
print(h.get('a')) # None
print(sorted(list(h))) # ['b', 'c']
字典
字典是另一种可变容器模型,且可存储任意类型对象。
字典的每个键值 key=>value 对用冒号 : 分割,每个键值对之间用逗号 , 分割,整个字典包括在花括号 {} 中 ,格式如下所示:
d = {key1 : value1, key2 : value2 }

基于哈希表实现字典
class Array(object):
def __init__(self, size=32, init=None):
self._size = size
self._items = [init] * size
def __getitem__(self, index):
return self._items[index]
def __setitem__(self, index, value):
self._items[index] = value
def __len__(self):
return self._size
def clear(self, value=None):
for i in range(len(self._items)):
self._items[i] = value
def __iter__(self):
for item in self._items:
yield item
class Slot(object):
"""
定义一个 hash 表数组的槽(slot 这里指的就是数组的一个位置)
hash table 就是一个数组,每个数组的元素(也叫slot槽)是一个对象,对象包含两个属性 key 和 value。
注意,一个槽有三种状态,看你能否想明白。相比链接法解决冲突,探查法删除一个 key 的操作稍微复杂。
1.从未使用 HashMap.UNUSED。此槽没有被使用和冲突过,查找时只要找到 UNUSED 就不用再继续探查了
2.使用过但是 remove 了,此时是 HashMap.EMPTY,该探查点后边的元素仍然可能是有key的,需要继续查找
3.槽正在使用 Slot 节点
"""
def __init__(self, key, value):
self.key, self.value = key, value
class HashTable(object):
UNUSED = None # 没被使用过
EMPTY = Slot(None, None) # 使用却被删除过
def __init__(self):
self._table = Array(8, init=HashTable.UNUSED) # 保持 2*i 次方
self.length = 0
@property
def _load_factor(self):
# load_factor 超过 0.8 重新分配
return self.length / float(len(self._table))
def __len__(self):
return self.length
# 进行哈希
def _hash(self, key):
return abs(hash(key)) % len(self._table)
# 查找key
def _find_key(self, key):
"""
解释一个 slot 为 UNUSED 和 EMPTY 的区别
因为使用的是二次探查的方式,假如有两个元素 A,B 冲突了,
首先A hash 得到是 slot 下标5,A 放到了第5个槽,之后插入 B 因为冲突了,所以继续根据二次探查方式放到了 slot下标8。
然后删除 A,槽 5 被置为 EMPTY。然后我去查找 B,
第一次 hash 得到的是 槽5,但是这个时候我还是需要第二次计算 hash 才能找到 B。
但是如果槽是 UNUSED 我就不用继续找了,我认为 B 就是不存在的元素。这个就是 UNUSED 和 EMPTY 的区别。
"""
origin_index = index = self._hash(key) # origin_index 判断是否又走到了起点,如果查找一圈了都找不到则无此元素
_len = len(self._table)
while self._table[index] is not HashTable.UNUSED:
if self._table[index] is HashTable.EMPTY: # 注意如果是 EMPTY,继续寻找下一个槽
index = (index * 5 + 1) % _len
if index == origin_index:
break
continue
if self._table[index].key == key: # 找到了key
return index
else:
index = (index * 5 + 1) % _len # 没有找到继续找下一个位置
if index == origin_index:
break
return None
# 找能插入的槽
def _find_slot_for_insert(self, key):
index = self._hash(key)
_len = len(self._table)
while not self._slot_can_insert(index): # 直到找到一个可以用的槽
index = (index * 5 + 1) % _len
return index
# 槽是否能插入
def _slot_can_insert(self, index):
return self._table[index] is HashTable.EMPTY or self._table[index] is HashTable.UNUSED
# in operator,实现之后可以使用 in 操作符判断
def __contains__(self, key):
index = self._find_key(key)
return index is not None
# 添加元素
def add(self, key, value):
if key in self: # update
index = self._find_key(key)
self._table[index].value = value
return False
else:
index = self._find_slot_for_insert(key)
self._table[index] = Slot(key, value)
self.length += 1
if self._load_factor >= 0.8:
self._rehash()
return True
# 槽不够时,重哈希
def _rehash(self):
old_table = self._table
newsize = len(self._table) * 2
self._table = Array(newsize, HashTable.UNUSED)
self.length = 0
for slot in old_table:
if slot is not HashTable.UNUSED and slot is not HashTable.EMPTY:
index = self._find_slot_for_insert(slot.key)
self._table[index] = slot
self.length += 1
# 获取值
def get(self, key, default=None):
index = self._find_key(key)
if index is None:
return default
else:
return self._table[index].value
# 移除
def remove(self, key):
index = self._find_key(key)
if index is None:
raise KeyError()
value = self._table[index].value
self.length -= 1
self._table[index] = HashTable.EMPTY
return value
# 遍历
def __iter__(self):
for slot in self._table:
if slot not in (HashTable.EMPTY, HashTable.UNUSED):
yield slot.key
class DictADT(HashTable):
# 执行dict[key]=value时执行
def __setitem__(self, key, value):
self.add(key, value)
# 执行dict[key]时执行
def __getitem__(self, key, default=None):
if key not in self:
raise KeyError()
return self.get(key, default)
# 遍历时执行
def _iter_slot(self):
for slot in self._table:
if slot not in (self.UNUSED, self.EMPTY):
yield slot
# 实现items方法
def items(self):
for slot in self._iter_slot():
yield (slot.key, slot.value)
# 实现keys方法
def keys(self):
for slot in self._iter_slot():
yield slot.key
# 实现values方法
def values(self):
for slot in self._iter_slot():
yield slot.value
字典的使用
d = DictADT()
d['a'] = 1
print(d['a']) # 1
集合
集合是一种不包含重复元素的数据结构,经常用来判断是否重复这种操作,或者集合中是否存在一个元素。
集合可能最常用的就是去重,判断是否存在一个元素等,但是 set 相比 dict 有更丰富的操作,主要是数学概念上的。
如果你学过《离散数学》中集合相关的概念,基本上是一致的。 python 的 set 提供了如下基本的集合操作, 假设有两个集合 A,B,有以下操作:
交集: A & B,表示同时在 A 和 B 中的元素。 python 中重载
__and__实现并集: A | B,表示在 A 或者 B 中的元素,两个集合相加。python 中重载
__or__实现差集: A - B,表示在 A 中但是不在 B 中的元素。 python 中重载
__sub__实现
基于哈希表实现集合
class Array(object):
def __init__(self, size=32, init=None):
self._size = size
self._items = [init] * size
def __getitem__(self, index):
return self._items[index]
def __setitem__(self, index, value):
self._items[index] = value
def __len__(self):
return self._size
def clear(self, value=None):
for i in range(len(self._items)):
self._items[i] = value
def __iter__(self):
for item in self._items:
yield item
class Slot(object):
"""
定义一个 hash 表数组的槽(slot 这里指的就是数组的一个位置)
hash table 就是一个数组,每个数组的元素(也叫slot槽)是一个对象,对象包含两个属性 key 和 value。
注意,一个槽有三种状态,看你能否想明白。相比链接法解决冲突,探查法删除一个 key 的操作稍微复杂。
1.从未使用 HashMap.UNUSED。此槽没有被使用和冲突过,查找时只要找到 UNUSED 就不用再继续探查了
2.使用过但是 remove 了,此时是 HashMap.EMPTY,该探查点后边的元素仍然可能是有key的,需要继续查找
3.槽正在使用 Slot 节点
"""
def __init__(self, key, value):
self.key, self.value = key, value
class HashTable(object):
UNUSED = None # 没被使用过
EMPTY = Slot(None, None) # 使用却被删除过
def __init__(self):
self._table = Array(8, init=HashTable.UNUSED) # 保持 2*i 次方
self.length = 0
@property
def _load_factor(self):
# load_factor 超过 0.8 重新分配
return self.length / float(len(self._table))
def __len__(self):
return self.length
# 进行哈希
def _hash(self, key):
return abs(hash(key)) % len(self._table)
# 查找key
def _find_key(self, key):
"""
解释一个 slot 为 UNUSED 和 EMPTY 的区别
因为使用的是二次探查的方式,假如有两个元素 A,B 冲突了,
首先A hash 得到是 slot 下标5,A 放到了第5个槽,之后插入 B 因为冲突了,所以继续根据二次探查方式放到了 slot下标8。
然后删除 A,槽 5 被置为 EMPTY。然后我去查找 B,
第一次 hash 得到的是 槽5,但是这个时候我还是需要第二次计算 hash 才能找到 B。
但是如果槽是 UNUSED 我就不用继续找了,我认为 B 就是不存在的元素。这个就是 UNUSED 和 EMPTY 的区别。
"""
origin_index = index = self._hash(key) # origin_index 判断是否又走到了起点,如果查找一圈了都找不到则无此元素
_len = len(self._table)
while self._table[index] is not HashTable.UNUSED:
if self._table[index] is HashTable.EMPTY: # 注意如果是 EMPTY,继续寻找下一个槽
index = (index * 5 + 1) % _len
if index == origin_index:
break
continue
if self._table[index].key == key: # 找到了key
return index
else:
index = (index * 5 + 1) % _len # 没有找到继续找下一个位置
if index == origin_index:
break
return None
# 找能插入的槽
def _find_slot_for_insert(self, key):
index = self._hash(key)
_len = len(self._table)
while not self._slot_can_insert(index): # 直到找到一个可以用的槽
index = (index * 5 + 1) % _len
return index
# 槽是否能插入
def _slot_can_insert(self, index):
return self._table[index] is HashTable.EMPTY or self._table[index] is HashTable.UNUSED
# in operator,实现之后可以使用 in 操作符判断
def __contains__(self, key):
index = self._find_key(key)
return index is not None
# 添加元素
def add(self, key, value):
if key in self: # update
index = self._find_key(key)
self._table[index].value = value
return False
else:
index = self._find_slot_for_insert(key)
self._table[index] = Slot(key, value)
self.length += 1
if self._load_factor >= 0.8:
self._rehash()
return True
# 槽不够时,重哈希
def _rehash(self):
old_table = self._table
newsize = len(self._table) * 2
self._table = Array(newsize, HashTable.UNUSED)
self.length = 0
for slot in old_table:
if slot is not HashTable.UNUSED and slot is not HashTable.EMPTY:
index = self._find_slot_for_insert(slot.key)
self._table[index] = slot
self.length += 1
# 获取值
def get(self, key, default=None):
index = self._find_key(key)
if index is None:
return default
else:
return self._table[index].value
# 移除
def remove(self, key):
index = self._find_key(key)
if index is None:
raise KeyError()
value = self._table[index].value
self.length -= 1
self._table[index] = HashTable.EMPTY
return value
# 遍历
def __iter__(self):
for slot in self._table:
if slot not in (HashTable.EMPTY, HashTable.UNUSED):
yield slot.key
class SetADT(HashTable):
# 添加元素
def add(self, key):
super().add(key, True)
def __and__(self, other_set):
"""交集 A&B"""
new_set = SetADT()
for element_a in self:
if element_a in other_set:
new_set.add(element_a)
return new_set
def __sub__(self, other_set):
"""差集 A-B"""
new_set = SetADT()
for element_a in self:
if element_a not in other_set:
new_set.add(element_a)
return new_set
def __or__(self, other_set):
"""并集 A|B"""
new_set = SetADT()
for element_a in self:
new_set.add(element_a)
for element_b in other_set:
new_set.add(element_b)
return new_set
集合的使用
sa = SetADT()
sa.add(1)
sa.add(2)
sa.add(3) sb = SetADT()
sb.add(3)
sb.add(4)
sb.add(5) print(sorted(list(sa & sb))) # [3]
print(sorted(list(sa - sb))) # [1, 2]
print(sorted(list(sa | sb))) # [1, 2, 3, 4, 5]
~>.<~
使用python实现哈希表、字典、集合的更多相关文章
- Python实现哈希表(分离链接法)
一.python实现哈希表 只使用list,构建简单的哈希表(字典对象) # 不使用字典构造的分离连接法版哈希表 class HashList(): """ Simple ...
- 用python实现哈希表
哈哈,这是我第一篇博客园的博客.尝试了一下用python实现的哈希表,首先处理冲突的方法是开放地址法,冲突表达式为Hi=(H(key)+1)mod m,m为表长. #! /usr/bin/env py ...
- 2017年11月4日 vs类和结构的区别&哈希表&队列集合&栈集合&函数
类和结构的区别 类: 类是引用类型在堆上分配,类的实例进行赋值只是复制了引用,都指向同一段实际对象分配的内存 类有构造和析构函数 类可以继承和被继承 结构: 结构是值类型在栈上分配(虽然栈的访问速度比 ...
- Python列表,元组,字典,集合
列表 Python中列表是可变的,这是它区别于字符串和元组的最重要的特点,一句话概括即:列表可以修改,而字符串和元组不能. 列表追加数据的方法:append(),extend(数组),insert(位 ...
- python-列表 字典 集合 元祖 字符串的相关总结练习
1.执行python脚本的两种方式指定解释器执行在交互器中执行 2.简述位.字节的关系:ASCII1个二进制位是计算机里的最小表示单元1个字节是计算机里最小的储存单元二进制位=8bits(位)8bit ...
- list,arraylist,哈希表,字典,datatable的selct等等用法
例子一.获取到list中的最大值,极其索引 List<int> ls = new List<int>(); ls.Add(1); l ...
- HashSet集合存储数据的结构(哈希表)和Set集合存储㢝不重复的原理
HashSet集合存储数据的结构(哈希表) Set集合存储㢝不重复的原理 前提:存储的元素必须重写hashCode方法和equals方法
- Python 字典和集合基于哈希表实现
哈希表作为基础数据结构我不多说,有兴趣的可以百度,或者等我出一篇博客来细谈哈希表.我这里就简单讲讲:哈希表不过就是一个定长数组,元素找位置,遇到哈希冲突则利用 hash 算法解决找另一个位置,如果数组 ...
- 自己动手实现 HashMap(Python字典),彻底系统的学习哈希表(上篇)——不看血亏!!!
HashMap(Python字典)设计原理与实现(上篇)--哈希表的原理 在此前的四篇长文当中我们已经实现了我们自己的ArrayList和LinkedList,并且分析了ArrayList和Linke ...
随机推荐
- 迁移桌面程序到MS Store(12)——WPF使用UWP InkToolbar和InkCanvas
我们在<迁移桌面程序到MS Store(4)——桌面程序调用Win10 API>提到了对Win10 API的调用,但仍存在无法在WPF中使用UWP控件的问题,虽然都是XAML控件,但却是两 ...
- Springboot操作Elasticsearch
常见的日志系统是基于logstach+elasticsearch+kibna框架搭建的,但是有时候kibana的查询无法满足我们的要求,因此有时需要代码去操作es,本文后续都以es代替elastics ...
- Excel 如何做不定长区间汇总统计
第一步:创建数据-区间 辅助表(注意:首列值必须以升序排列,为后面vlookup模糊匹配做准备) 第二步:用vlookup模糊匹配生成一个新的“金额区间”字段 第三步:以“金额区间”字段为行透视汇总
- fastjson自定义序列化竟然有这么多姿势?
本文介绍下fastjson自定义序列化的各种操作. 一.什么是fastjson? fastjson是阿里巴巴的开源JSON解析库,它可以解析JSON格式的字符串,支持将Java Bean序列化为JSO ...
- 利用scrapy爬取腾讯的招聘信息
利用scrapy框架抓取腾讯的招聘信息,爬取地址为:https://hr.tencent.com/position.php 抓取字段包括:招聘岗位,人数,工作地点,发布时间,及具体的工作要求和工作任务 ...
- java.lang.IllegalArgumentException: A null value cannot be assigned to a primitive type
今天做项目测试接口,查询数据时出现以下错误,记录一下. 查询语句和错误信息: 实体类属性 原因是 由于字段 total和receive 在实体类中使用的是 int类型,但是数据库中查询出来的数据为nu ...
- 复习sed实例操作
第6周复习课(5月2日) 课程内容: 复习 扩展1.打印某行到某行之间的内容http://ask.apelearn.com/question/5592.sed转换大小写 http://ask.apel ...
- MariaDB和Apache安装
5月24日任务 课程内容: 11.6 MariaDB安装11.7/11.8/11.9 Apache安装扩展apache dso https://yq.aliyun.com/articles/6298a ...
- Netty学习——基于netty实现简单的客户端聊天小程序
Netty学习——基于netty实现简单的客户端聊天小程序 效果图,聊天程序展示 (TCP编程实现) 后端代码: package com.dawa.netty.chatexample; import ...
- 基于netty4.x开发时间服务器
在写代码之前 先了解下Reactor模型: Reactor单线程模型就是指所有的IO操作都在同一个NIO线程上面完成的,也就是IO处理线程是单线程的.NIO线程的职责是: (1)作为NIO服务端,接收 ...