【数据结构】10.java源码关于LinkedHashMap
目录
1.LinkedHashMap的内部结构
2.LinkedHashMap构造函数
3.元素新增策略
4.元素删除
5.元素修改和查找
6.特殊操作
7.扩容
8.总结
1.LinkedHashMap的内部结构
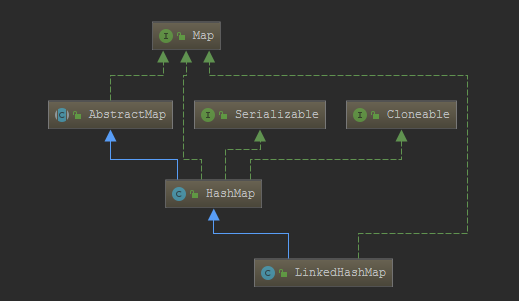
对象的内部结构其实就是hashmap的内部结构,但是比hashmap的内部结构node要多维护2个引用指针,用来做前置和后置链表
同事linkedhashmap本身还有头链表节点和尾部链表节点
static class Entry<K,V> extends MyHashMap.Node<K,V> {
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
因为linkedhashmap是继承自hashmap,所以hashmap有的它都有,比如上面2的n次幂,扩容策略等等
那么就有意思了,linkedhashmap有什么独到的地方么???
既然是继承自hashmap,那么我们看看hashmap没有的东西,或者被覆盖重写了的东西即可
2.LinkedHashMap构造函数
基本和hashmap一致,无法就是设置空间容量,负载因子等数据
这里空间容量和hashmap一样,也是取比当前容量大的最小2次幂
3.元素新增策略
就说put吧,就是完完全全调用的hashmap的 put方法。。。。晕
不过注意啊,再hashmap中有实打实大三个函数是为了linkedhashmap准备的,这个在源码中就说明了,并且put操作就用到了其中2个

这里可以吧之前hashmap中的这几个函数加上了解了
还有个地方需要注意,linkedhashmap还重写了newnode方法,这个是为了和链表串联起来
Node<K,V> newNode(int hash, K key, V value, Node<K,V> e) {
//每当创建一个新的链表节点的时候,我们调用linknodelast,吧当前添加到链表末尾
TestLinkedHashMap.Entry<K,V> p =
new TestLinkedHashMap.Entry<K,V>(hash, key, value, e);
linkNodeLast(p);
return p;
}
//不论这个节点是处于什么位置,都进行添加节点
private void linkNodeLast(TestLinkedHashMap.Entry<K,V> p) {
TestLinkedHashMap.Entry<K,V> last = tail;
tail = p;
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
}
接下来我们一一阐述hashmap专门为linkedhashmap预留的几个函数
3.1 afterNodeAccess
/**
*
* @program: y2019.collection.map.TestLinkedHashMap
* @description: 只有当put进去,这个值存放到hash桶上的时候,并且这个值是之前存在的,(或者是树状结构),才会触发这个函数
* @auther: xiaof
* @date: 2019/8/29 17:03
*/
void afterNodeAccess(Node<K,V> e) { // move node to last
TestLinkedHashMap.Entry<K,V> last;
if (accessOrder && (last = tail) != e) {
//获取这个节点的前置,和后置引用对象
TestLinkedHashMap.Entry<K,V> p = (TestLinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
//把后置设置为空
p.after = null;
//如果替换的对象没有前置节点,那么就把当前节点当做head
if (b == null)
head = a;
else
b.after = a; //否则建立双向链表数据,前置改为a //吧a的前置改成b
if (a != null)
a.before = b;
else
last = b; //然后吧tail指向p,这样就把p从原来的链表中,断裂开,然后拼接到tail后
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
tail = p;
//容器类修改次数++
++modCount;
}
}
3.2 afterNodeInsertion
这个是linkedhashmap再实现lrucache的时候会调用到的方法,平时没有作用
根据evict 和 判断是否需要删除最老插入的节点,后面我们实现lrucache的时候再详细了解
4.元素删除
Linkedhashmap的删除操作和hashmap一致,但是还有一个函数被重写了,就是这里有点不一样
其实操作就是,linkedhashmap因为是一个双向链表,所以在删除的时候就是做一个对双向链表进行删除的操作
这个方法就是
AfterNodeRemoval 把从hashmap中删除的元素,断开双向链表的连接
//把从hashmap中删除的元素,断开双向链表的连接
void afterNodeRemoval(Node<K, V> e) { // unlink
TestLinkedHashMap.Entry<K, V> p =
(TestLinkedHashMap.Entry<K, V>) e, b = p.before, a = p.after;
p.before = p.after = null;
if (b == null)
head = a;
else
b.after = a;
if (a == null)
tail = b;
else
a.before = b;
}
5.元素修改和查找
对于查找get元素,这里linkedhashmap就直接重写了,但是里面调用getnode其实还是hashmap那一套,不过就是多了个判断accessOrder参数,如果为true就会调用afterNodeAccess
这个方法前面有讲到
6.特殊操作
6.1 containsValue
因为是链表的缘故,所以这里是直接循环遍历链表一次即可
public boolean containsValue(Object value) {
for (TestLinkedHashMap.Entry<K,V> e = head; e != null; e = e.after) {
V v = e.value;
if (v == value || (value != null && value.equals(v)))
return true;
}
return false;
}
而hashmap呢?
public boolean containsValue(Object value) {
Node<K,V>[] tab; V v;
if ((tab = table) != null && size > 0) {
//先循环hash桶
for (int i = 0; i < tab.length; ++i) {
//然后遍历链表
for (Node<K,V> e = tab[i]; e != null; e = e.next) {
if ((v = e.value) == value ||
(value != null && value.equals(v)))
return true;
}
}
}
return false;
}
6.2 实现LRUCACHE
要实现lru首先要明白这是个什么?
近期最少使用算法。 内存管理的一种页面置换算法,对于在内存中但又不用的数据块(内存块)叫做LRU,操作系统会根据哪些数据属于LRU而将其移出内存而腾出空间来加载另外的数据。
为什么用linkedhashmap呢?因为这个容器事实是一个双向链表,而且里面带上参数的构造函数的时候,前面用的get方法会调用到afterNodeAccess方法,这个方法会吧最近get的数据重新指引向链表末尾
基于这点我们只要吧accessOrder设置为true即可
package y2019.collection.map; import java.util.Iterator;
import java.util.LinkedHashMap;
import java.util.Map;
import java.util.Set; /**
* @ProjectName: cutter-point
* @Package: y2019.collection.map
* @ClassName: TestLRUCache
* @Author: xiaof
* @Description: 实现lru (最近最不常使用)缓存
* 获取数据(get)和写入数据(set)。
* 获取数据get(key):如果缓存中存在key,则获取其数据值(通常是正数),否则返回-1。
* 写入数据set(key, value):如果key还没有在缓存中,则写入其数据值。
* 当缓存达到上限,它应该在写入新数据之前删除最近最少使用的数据用来腾出空闲位置。
* @Date: 2019/9/3 16:42
* @Version: 1.0
*/
public class TestLRUCache<K, V> { LinkedHashMap<K, V> cache = null;
int cacheSize; public TestLRUCache(int cacheSize) {
//默认负载因子取0.75
this.cacheSize = (int) Math.ceil(cacheSize / 0.75f) + 1;//向上取整数
cache = new LinkedHashMap<K, V>(this.cacheSize, 0.75f, true) {
@Override
protected boolean removeEldestEntry(Map.Entry<K, V> eldest) {
//这里有个关键的负载操作,因为是lru,所以当长度超了的时候,不是扩容,而是吧链表头干掉
System.out.println("size=" + this.size());
return this.size() > cacheSize;
}
};
} public V get(K key) {
return cache.get(key);
} public V set(K key, V value) {
return cache.put(key, value);
} public void setCacheSize(int cacheSize) {
this.cacheSize = cacheSize;
} public void printCache(){
for(Iterator it = cache.entrySet().iterator(); it.hasNext();){
Map.Entry<K,V> entry = (Map.Entry<K, V>)it.next();
if(!"".equals(entry.getValue())){
System.out.println(entry.getKey() + "\t" + entry.getValue());
}
}
System.out.println("------");
} public void PrintlnCache(){
Set<Map.Entry<K,V>> set = cache.entrySet();
for(Map.Entry<K,V> entry : set){
K key = entry.getKey();
V value = entry.getValue();
System.out.println("key:"+key+"value:"+value);
} } public static void main(String[] args) {
TestLRUCache<String,Integer> lrucache = new TestLRUCache<String,Integer>(3);
lrucache.set("aaa", 1);
lrucache.printCache();
lrucache.set("bbb", 2);
lrucache.printCache();
lrucache.set("ccc", 3);
lrucache.printCache();
lrucache.set("ddd", 4);
lrucache.printCache();
lrucache.set("eee", 5);
lrucache.printCache();
System.out.println("这是访问了ddd后的结果");
lrucache.get("ddd");
lrucache.printCache();
lrucache.set("fff", 6);
lrucache.printCache();
lrucache.set("aaa", 7);
lrucache.printCache();
} }
7.扩容
参考hashmap
8.总结我们重点放在lrucache上吧
借助linkedhashmap实现lru,重点就是再大小范围超出的时候进行删除头结点,而不是扩容
参考:
https://blog.csdn.net/zxt0601/article/details/77429150
https://www.jianshu.com/p/d76a78086c3a
【数据结构】10.java源码关于LinkedHashMap的更多相关文章
- java源码之LinkedHashMap
先盗两张图感受一下(来自:https://blog.csdn.net/justloveyou_/article/details/71713781) HashMap和双向链表的密切配合和分工合作造就了L ...
- Java源码阅读LinkedHashMap
1类签名与注释 public class LinkedHashMap<K,V> extends HashMap<K,V> implements Map<K,V> 哈 ...
- 如何阅读Java源码 阅读java的真实体会
刚才在论坛不经意间,看到有关源码阅读的帖子.回想自己前几年,阅读源码那种兴奋和成就感(1),不禁又有一种激动. 源码阅读,我觉得最核心有三点:技术基础+强烈的求知欲+耐心. 说到技术基础,我打个比 ...
- 实战录 | Kafka-0.10 Consumer源码解析
<实战录>导语 前方高能!请注意本期攻城狮幽默细胞爆表,坐地铁的拉好把手,喝水的就建议暂时先别喝了:)本期分享人为云端卫士大数据工程师韩宝君,将带来Kafka-0.10 Consumer源 ...
- 如何阅读Java源码
刚才在论坛不经意间,看到有关源码阅读的帖子.回想自己前几年,阅读源码那种兴奋和成就感(1),不禁又有一种激动.源码阅读,我觉得最核心有三点:技术基础+强烈的求知欲+耐心. 说到技术基础,我打个比方吧, ...
- Java 源码学习线路————_先JDK工具包集合_再core包,也就是String、StringBuffer等_Java IO类库
http://www.iteye.com/topic/1113732 原则网址 Java源码初接触 如果你进行过一年左右的开发,喜欢用eclipse的debug功能.好了,你现在就有阅读源码的技术基础 ...
- [收藏] Java源码阅读的真实体会
收藏自http://www.iteye.com/topic/1113732 刚才在论坛不经意间,看到有关源码阅读的帖子.回想自己前几年,阅读源码那种兴奋和成就感(1),不禁又有一种激动. 源码阅读,我 ...
- Java源码解读(一)——HashMap
HashMap作为常用的一种数据结构,阅读源码去了解其底层的实现是十分有必要的.在这里也分享自己阅读源码遇到的困难以及自己的思考. HashMap的源码介绍已经有许许多多的博客,这里只记录了一些我看源 ...
- 如何阅读Java源码?
阅读本文大概需要 3.6 分钟. 阅读Java源码的前提条件: 1.技术基础 在阅读源码之前,我们要有一定程度的技术基础的支持. 假如你从来都没有学过Java,也没有其它编程语言的基础,上来就啃< ...
随机推荐
- Java面试题-基础篇三(干货)
这些JAVA基础题确定都会了吗? 31.String s = new String("xyz");创建了几个StringObject?是否可以继承String类? 两个或一个都有可 ...
- jsp数据交互(二).2
1.application对象 application对象类似于系统的“全局变量”,用于同一个服务器内的所有用户之间的数据共享,对于整个Web服务器,application对象有且只有一个实例. (1 ...
- Java集合系列(二):ArrayList、LinkedList、Vector的使用方法及区别
本篇博客主要讲解List接口的三个实现类ArrayList.LinkedList.Vector的使用方法以及三者之间的区别. 1. ArrayList使用 ArrayList是List接口最常用的实现 ...
- Windows 使用 helm3 和 kubectl
简介: 主要原因是,我不会 vim ,在 linux 上修改 charts 的很蹩脚,所以就想着能不能再 windows 上执行 helm 命令,将 charts install linux 上搭建的 ...
- [Chat]实战:仿网易云课堂微信小程序开发核心技术剖析和经验分享
本Chat以一个我参与开发并已上线运营近2年——类似网易云课堂的微信小程序项目,来进行微信小程序高级开发的学习. 本场Chat围绕项目开发核心技术分析,帮助你快速掌握在线视频.音频类小程序开发所需要的 ...
- xpath定位的一些方法
- Centos安装git并配置ssh
1.下载git安装包 git-2.9.4.tar.gz 2.解压 tar -xzvf git-2.9.4.tar.gz 3.修改解压后的文件名 mv git-2.9.4 git 4.安装git依赖的库 ...
- LR(1)语法分析器生成器(生成Action表和Goto表)java实现(一)
序言 : 在看过<自己实现编译器链接器>源码之后,最近在看<编译器设计>,但感觉伪代码还是有点太浮空.没有掌握的感觉,也因为内网几乎没有LR(1)语法分析器生成器的内容,于是我 ...
- java学习-NIO(三)Channel
通道(Channel)是java.nio的第二个主要创新.它们既不是一个扩展也不是一项增强,而是全新.极好的Java I/O示例,提供与I/O服务的直接连接.Channel用于在字节缓冲区和位于通道另 ...
- alluxio2.0特性-预览
项目地址 https://github.com/Alluxio/alluxio/tree/branch-2.0-preview 2.0版本-构思和设计 支持超大规模数据工作负载 Alluxio作为计算 ...