Python 爬虫从入门到进阶之路(九)
之前的文章我们介绍了一下 Python 中的正则表达式和与爬虫正则相关的 re 模块,本章我们就利用正则表达式和 re 模块来做一个案例,爬取《糗事百科》的糗事并存储到本地。
我们要爬取的网站链接是 https://www.qiushibaike.com/text/page/1/ 。

我们要爬取的是里面的糗事,在之前的文章中我们已经可以爬取整个 url 链接里的 html 内容,那么我们就可以根据爬取到的 html 代码,再通过 re 模块匹配我们想要的内容即可。
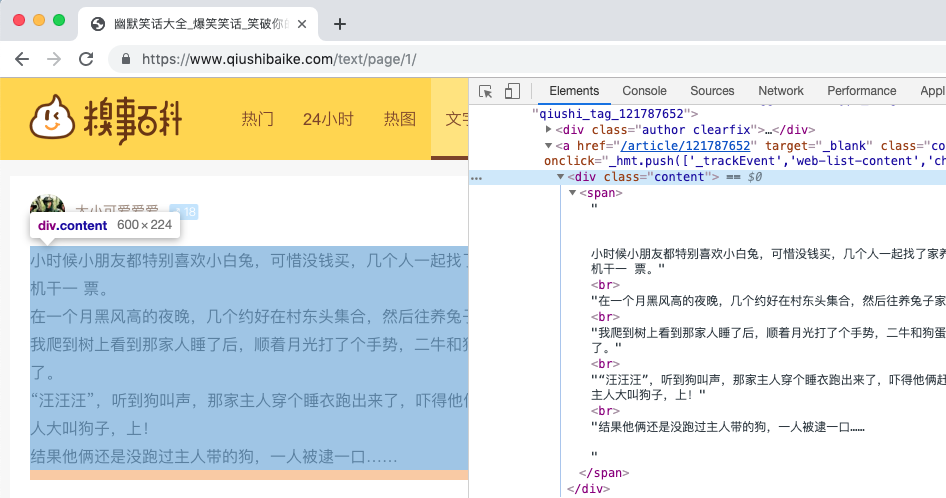
我们通过调用开发者工具检查 HTML 元素发现我们想要的内容在 <div class="content"> ...... </div> 内,根据这个我们可以写出代码如下:
import urllib.request
import re
import ssl # 取消代理验证
ssl._create_default_https_context = ssl._create_unverified_context url = "https://www.qiushibaike.com/text/page/1/"
# User-Agent头
user_agent = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.157 Safari/537.36'
headers = {'User-Agent': user_agent}
req = urllib.request.Request(url, headers=headers)
response = urllib.request.urlopen(req)
# 获取每页的HTML源码字符串
html = response.read().decode('utf-8')
# 创建正则表达式规则对象,匹配每页里的糗事内容,re.S 表示匹配全部字符串内容
# re.S 如果没有re.S 则是只匹配一行有没有符合规则的字符串,如果没有则下一行重新匹配
# 如果加上re.S 则是将所有的字符串将一个整体进行匹配
pattern = re.compile(r'<div.*?class="content">(.*?)</div>', re.S)
# 将正则匹配对象应用到html源码字符串里,返回这个页面里的所有糗事的列表
content_list = pattern.findall(html)
# 调用dealPage() 处理糗事里的杂七杂八
print(content_list)
最终我们打印结果如下:
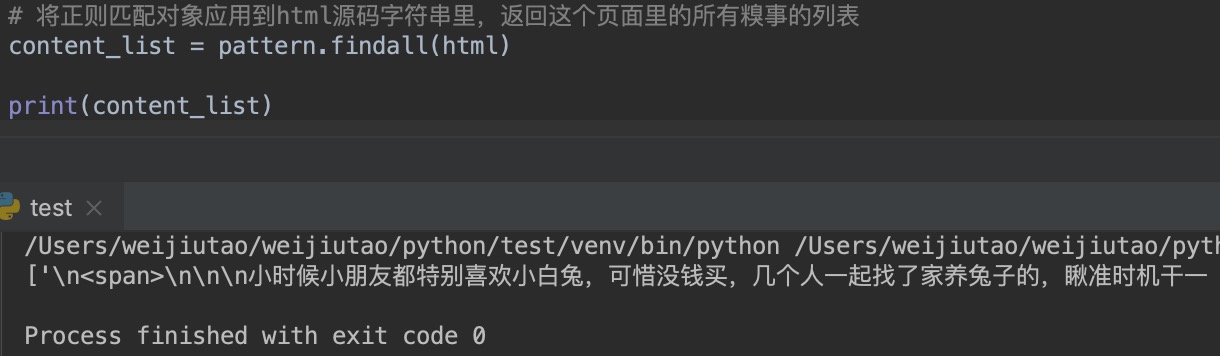
从上面的打印结果可以看出我们已经拿到了我们想要的数据,并且存储在了一个列表里,那么接下来我们只需要再处理一下列表,叫列表内杂七杂八的内容,如上图中的 \n <span>标签等去掉,就是我们想要的内容了。
for item in item_list:
item = item.replace('<span>', "").replace('<span class="contentForAll">查看全文', "").replace("</span>","").replace("<br/>", "").replace("\n", "")
print(item)
self.writePage(item)
上面的代码中 item_list 即为我们上面所获取到的 content_list 列表,通过对列表的内容分析,我们发现有 <span> ,<span class="contentForAll">查看全文,</span>,<br/>,\n 等多余内容,我们通过 replace 方法将其转为空,剩下的就是我们想要的内容了,接下来就是存储到本地即可了。
上面就可以实现一个获取 糗事百科 的糗事的简单爬虫,但是只能爬取单个页面的内容,通过分析 url 我们发现 https://www.qiushibaike.com/text/page/1/ 中最后的 1 即为页码,我们就可以根据这个页码逐一爬取更多页面的内容,最终的代码如下:
import urllib.request
import re
import ssl # 取消代理验证
ssl._create_default_https_context = ssl._create_unverified_context class Spider:
def __init__(self):
# 初始化起始页位置
self.page = 1
# 爬取开关,如果为True继续爬取
self.switch = True def loadPage(self):
"""
作用:打开页面
"""
url = "https://www.qiushibaike.com/text/page/" + str(self.page) + "/"
# User-Agent头
user_agent = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.157 Safari/537.36'
headers = {'User-Agent': user_agent}
req = urllib.request.Request(url, headers=headers)
response = urllib.request.urlopen(req)
# 获取每页的HTML源码字符串
html = response.read().decode('utf-8')
# 创建正则表达式规则对象,匹配每页里的糗事内容,re.S 表示匹配全部字符串内容
# re.S 如果没有re.S 则是只匹配一行有没有符合规则的字符串,如果没有则下一行重新匹配
# 如果加上re.S 则是将所有的字符串将一个整体进行匹配
pattern = re.compile(r'<div.*?class="content">(.*?)</div>', re.S)
# 将正则匹配对象应用到html源码字符串里,返回这个页面里的所有糗事的列表
content_list = pattern.findall(html)
# 调用dealPage() 处理糗事里的杂七杂八
self.dealPage(content_list) def dealPage(self, item_list):
"""
@brief 处理得到的糗事列表
@param item_list 得到的糗事列表
@param page 处理第几页
"""
for item in item_list:
item = item.replace('<span>', "").replace('<span class="contentForAll">查看全文', "").replace("</span>","").replace("<br/>", "").replace("\n", "")
self.writePage(item) def writePage(self, text):
"""
@brief 将数据追加写进文件中
@param text 文件内容
"""
myFile = open("./duanzi.txt", 'a') # 追加形式打开文件
myFile.write(text + "\n\n")
myFile.close() def startWork(self):
"""
控制爬虫运行
"""
# 循环执行,直到 self.switch == False
while self.switch:
# 用户确定爬取的次数
self.loadPage()
command = input("如果继续爬取,请按回车(退出输入quit)")
if command == "quit":
# 如果停止爬取,则输入 quit
self.switch = False
# 每次循环,page页码自增1
self.page += 1
print("爬取结束!") if __name__ == '__main__':
# 定义一个Spider对象
qiushiSpider = Spider()
qiushiSpider.startWork()
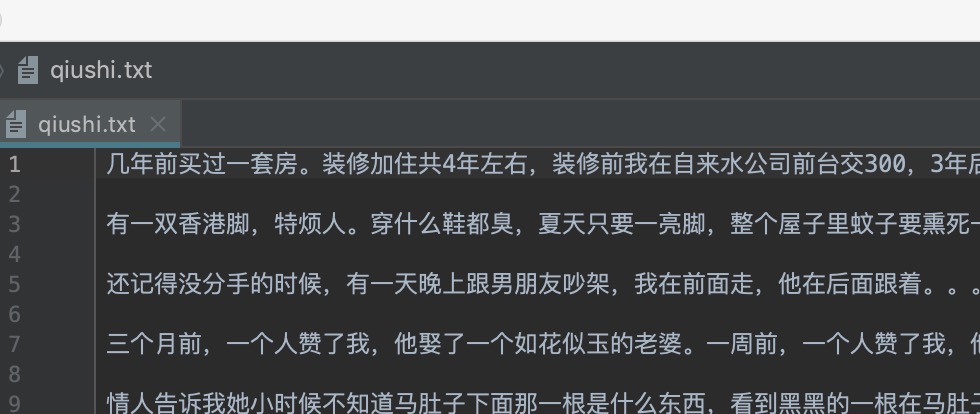
最终会在本地添加一个 qiushi.txt 的文件,结果如下:
Python 爬虫从入门到进阶之路(九)的更多相关文章
- Python 爬虫从入门到进阶之路(八)
在之前的文章中我们介绍了一下 requests 模块,今天我们再来看一下 Python 爬虫中的正则表达的使用和 re 模块. 实际上爬虫一共就四个主要步骤: 明确目标 (要知道你准备在哪个范围或者网 ...
- Python 爬虫从入门到进阶之路(二)
上一篇文章我们对爬虫有了一个初步认识,本篇文章我们开始学习 Python 爬虫实例. 在 Python 中有很多库可以用来抓取网页,其中内置了 urllib 模块,该模块就能实现我们基本的网页爬取. ...
- Python 爬虫从入门到进阶之路(六)
在之前的文章中我们介绍了一下 opener 应用中的 ProxyHandler 处理器(代理设置),本篇文章我们再来看一下 opener 中的 Cookie 的使用. Cookie 是指某些网站服务器 ...
- Python 爬虫从入门到进阶之路(十二)
之前的文章我们介绍了 re 模块和 lxml 模块来做爬虫,本章我们再来看一个 bs4 模块来做爬虫. 和 lxml 一样,Beautiful Soup 也是一个HTML/XML的解析器,主要的功能也 ...
- Python 爬虫从入门到进阶之路(十五)
之前的文章我们介绍了一下 Python 的 json 模块,本章我们就介绍一下之前根据 Xpath 模块做的爬取<糗事百科>的糗事进行丰富和完善. 在 Xpath 模块的爬取糗百的案例中我 ...
- Python 爬虫从入门到进阶之路(十六)
之前的文章我们介绍了几种可以爬取网站信息的模块,并根据这些模块爬取了<糗事百科>的糗百内容,本章我们来看一下用于专门爬取网站信息的框架 Scrapy. Scrapy是用纯Python实现一 ...
- Python 爬虫从入门到进阶之路(十七)
在之前的文章中我们介绍了 scrapy 框架并给予 scrapy 框架写了一个爬虫来爬取<糗事百科>的糗事,本章我们继续说一下 scrapy 框架并对之前的糗百爬虫做一下优化和丰富. 在上 ...
- Python 爬虫从入门到进阶之路(五)
在之前的文章中我们带入了 opener 方法,接下来我们看一下 opener 应用中的 ProxyHandler 处理器(代理设置). 使用代理IP,这是爬虫/反爬虫的第二大招,通常也是最好用的. 很 ...
- Python 爬虫从入门到进阶之路(七)
在之前的文章中我们一直用到的库是 urllib.request,该库已经包含了平常我们使用的大多数功能,但是它的 API 使用起来让人感觉不太好,而 Requests 自称 “HTTP for Hum ...
随机推荐
- UVa 12657 Boxes in a Line(应用双链表)
Boxes in a Line You have n boxes in a line on the table numbered 1 . . . n from left to right. Your ...
- C++中的模板编程
一,函数模板 1.函数模板的概念 C++中提供了函数模板,所谓函数模板,实际上是建立一个通用函数,其函数的返回值类型和函数的参数类型不具体指定,用一个虚拟的类型来表示.这个通用函数就被称为函数的模板. ...
- twemproxy架构分析——剖析twemproxy代码前编
twemproxy背景 在业务量剧增的今天,单台高速缓存服务器已经无法满足业务的需求, 而相较于大容量SSD数据存储方案,缓存具备速度和成本优势,但也存在数据安全性的挑战.为此搭建一个高速缓存服务器集 ...
- MongoDB 通过自带工具命令进行备份表,再将备份表还原出数据
创建一个bat文件 在其中输入以下3行 第1行进入工具mongodump所在的目录 第2行 将Adam数据库里面的 第3行 将上面存在C:\Data\Dump\Adam\文件夹里面的TBLQuickS ...
- 重设windows10中的sub linux系统用户密码
原文:重设windows10中的sub linux系统用户密码 版权声明:本文为博主原创文章,转载请注明出处. https://blog.csdn.net/haiyoung/article/detai ...
- WPF loading加载动画库
原文:WPF loading加载动画库 1. 下载Dll https://pan.baidu.com/s/1wKgv5_Q8phWo5CrXWlB9dA 2.在项目中添加引用 ...
- 谷歌推出备份新工具:Google Drive将同步计算机文件
Google 正在将云端硬盘 Drive 转变成更强大的文件备份工具.很快,Google Drive 将能监测并备份你电脑上的(几乎)所有文件,只要是你勾选的文档,Drive 就能同步至云端. 具体来 ...
- .NET与 java通用的3DES加密解密方法
C#代码 private void button1_Click(object sender, EventArgs e) { string jiami = textBox1.Text; textBox2 ...
- WPF:通过BitmapSource的CopyPixels和Create方法来切割图片
原文 WPF:通过BitmapSource的CopyPixels和Create方法来切割图片 BitmapSource是WPF图像的最基本类型,它同时提供两个像素相关的方法就是CopyPixels和C ...
- Android零基础入门第19节:Button使用详解
原文:Android零基础入门第19节:Button使用详解 Button(按钮)是Android开发中使用非常频繁的组件,主要是在UI界面上生成一个按钮,该按钮可以供用户单击,当用户单击按钮时,按钮 ...