python网络爬虫之自动化测试工具selenium[二]
@
前言
hello,大家好,在上章的内容里我们已经可以爬取到了整个网页下来,当然也仅仅就是一个网页。
因为里面还有很多很多的标签啊之类我们所不需要的东西。
额,先暂且说下本章内容,如果是没有丝毫编程基础的小白来说是比较难懂的
本章内容重点是
1、分析网站的结构来获取一个json串,也就是之前我们爬的是一个网页,这次是爬取一个Ajax请求的一个响应数据(json串)。
2、使用selenuim模块自动化工具
所以如果需要获取一些评论啊,或者一些特殊的要求都可以学一下。
先说好,更上一章一样下载好selenium模块!!python网络爬虫之入门[一]

一、获取今日头条的评论信息(request请求获取json)
1、分析数据
进入头条
在fillder中分析一下这个网页的一个请求
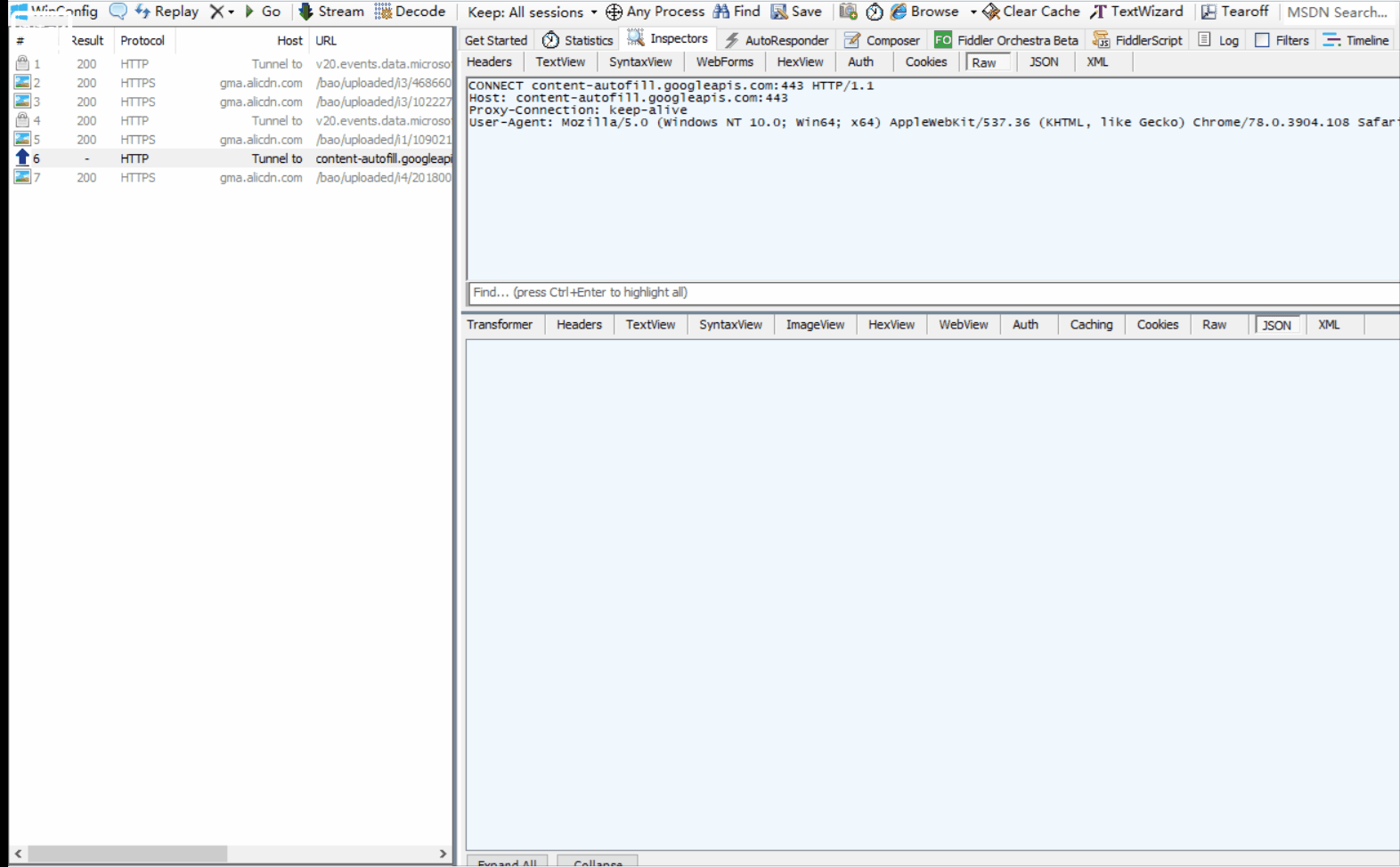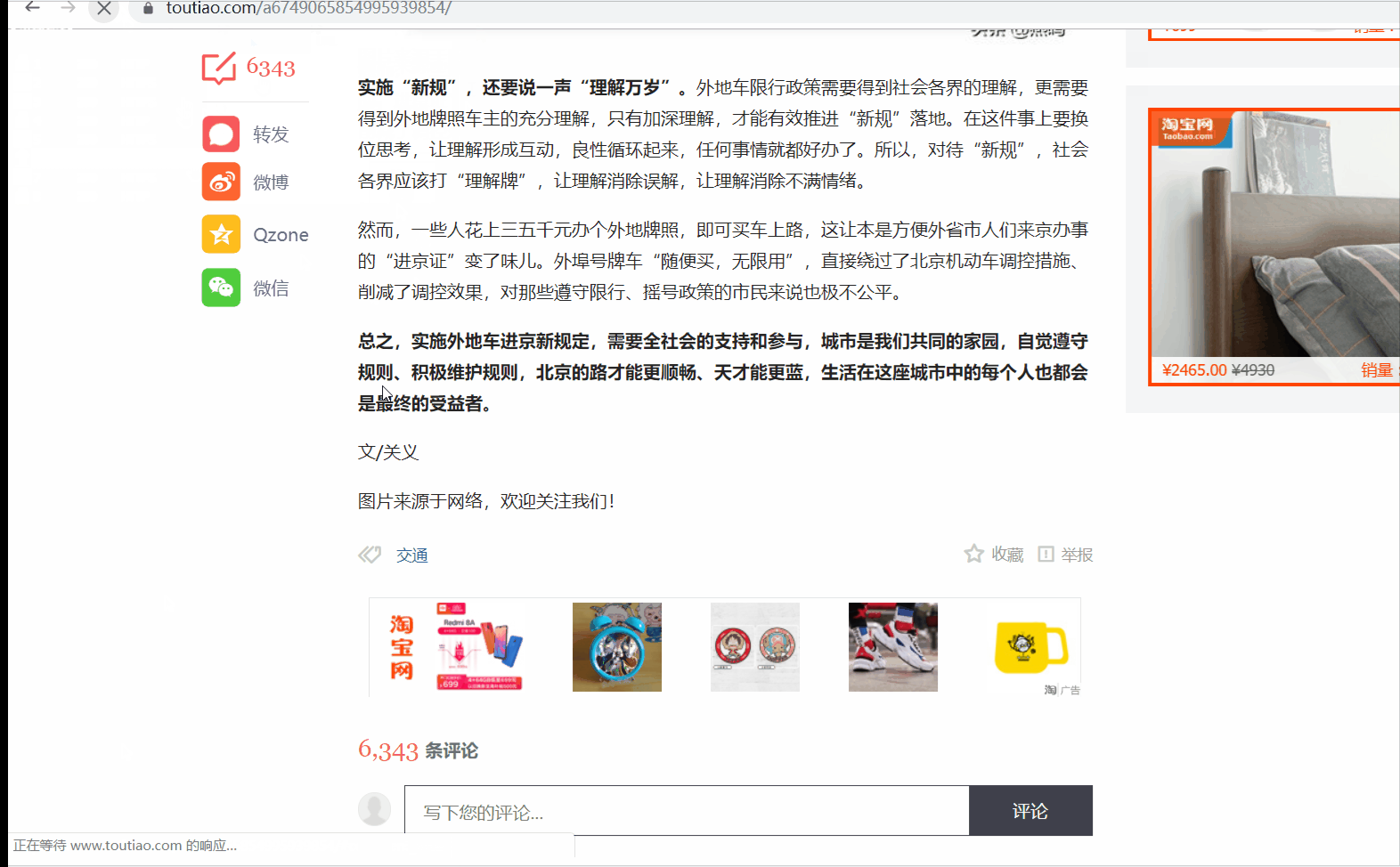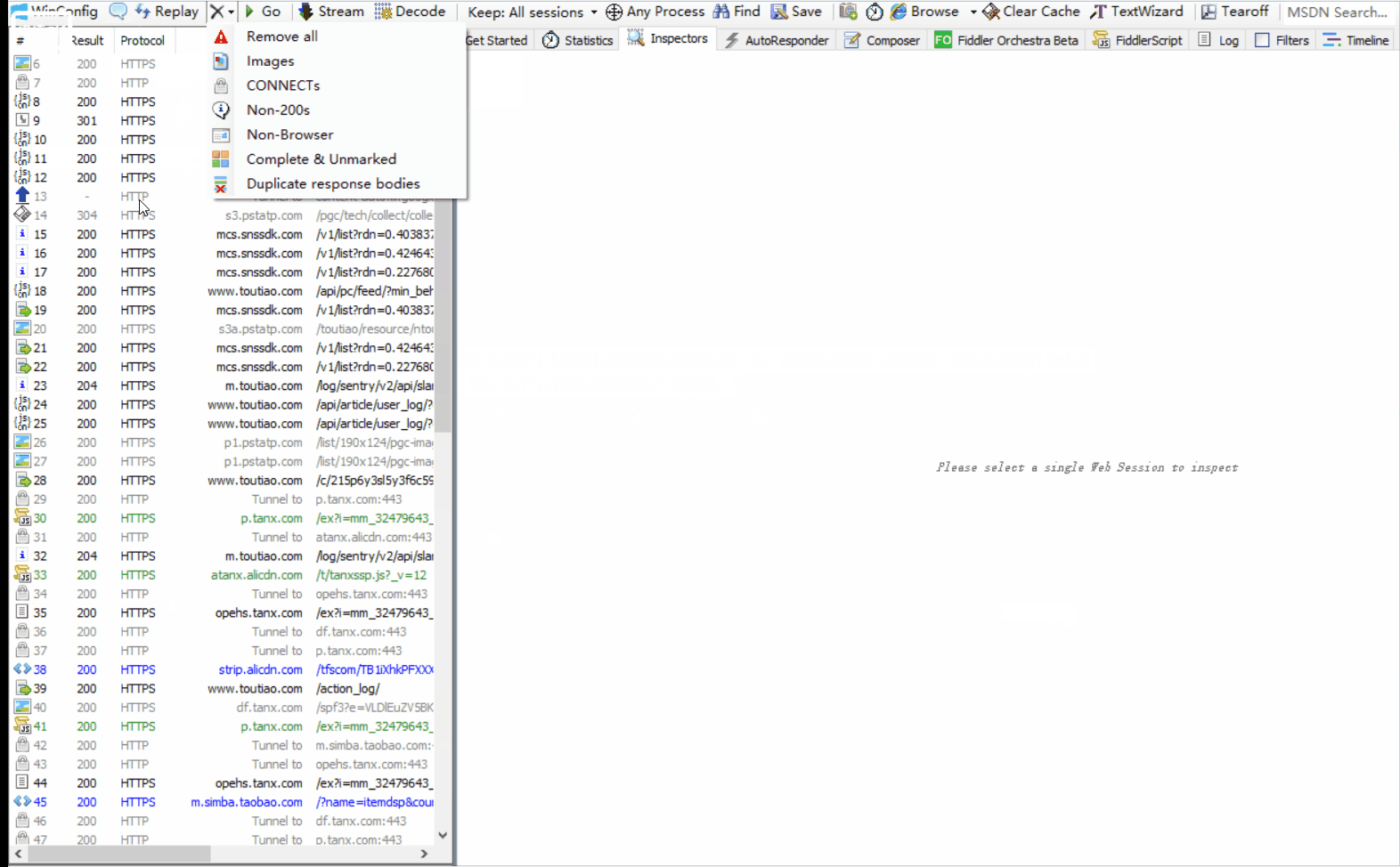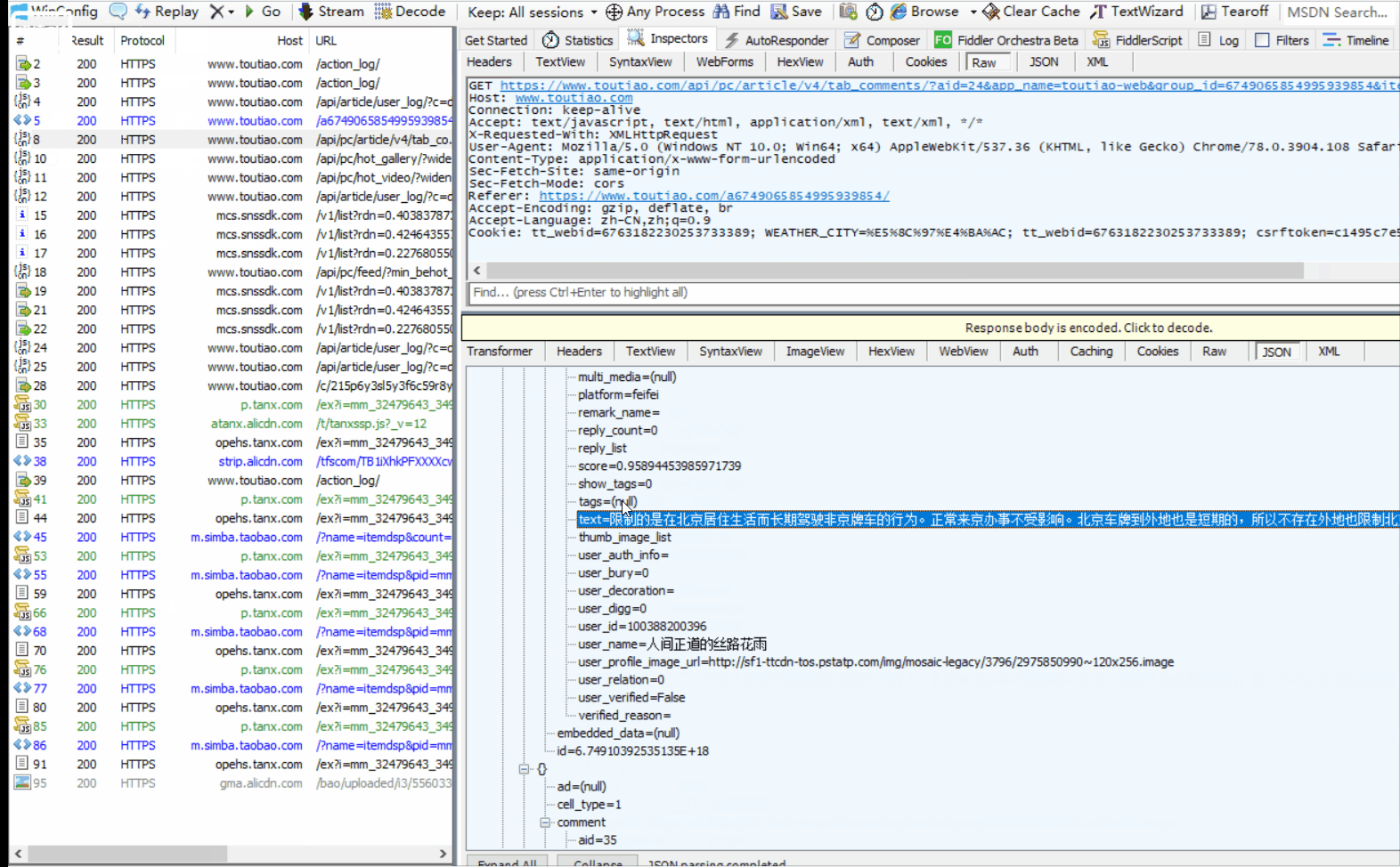
详细讲解:
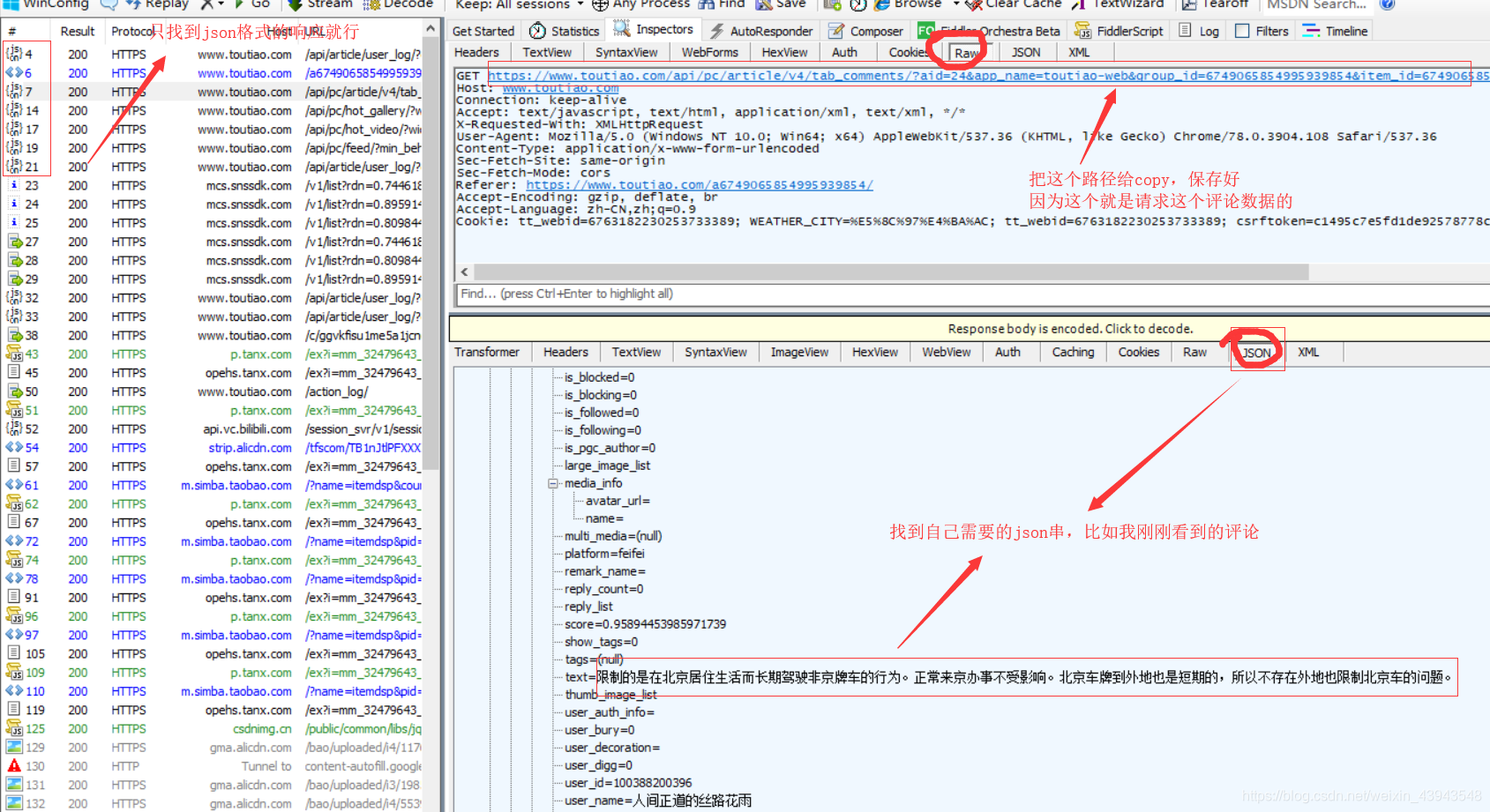
我们测试一下
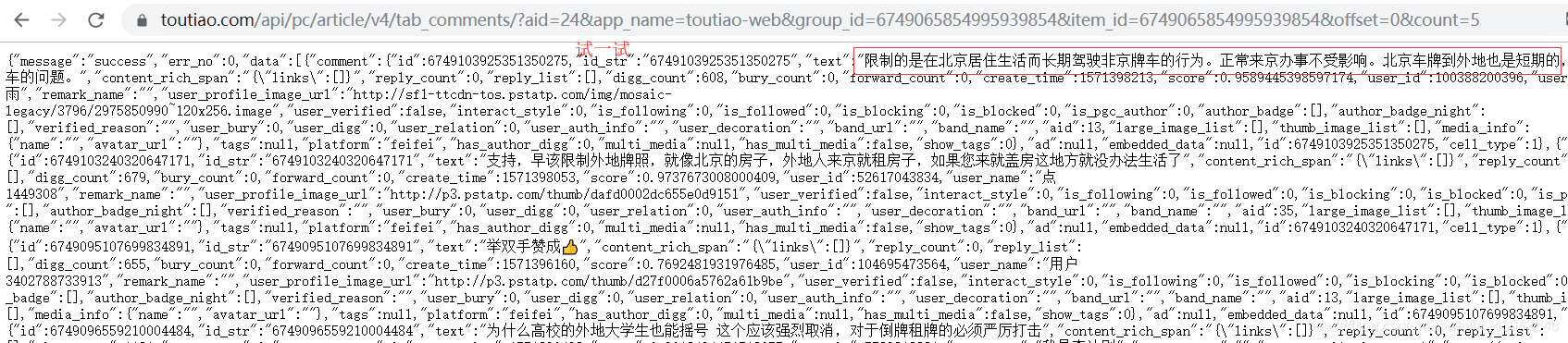
2、获取数据
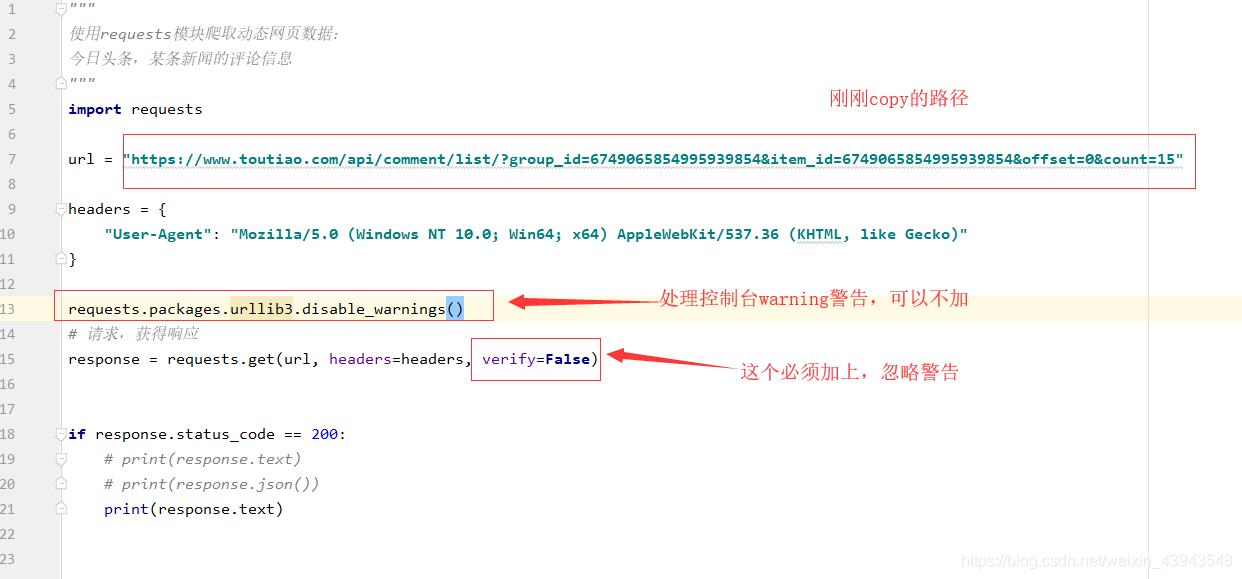
ok,那么跟据我们之前所学的内容我们可以直接使用request模块请求一次
全部代码:
"""
使用requests模块爬取动态网页数据:
今日头条,某条新闻的评论信息
"""
import requests
url = "https://www.toutiao.com/api/comment/list/?group_id=6749065854995939854&item_id=6749065854995939854&offset=0&count=15"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)"
}
requests.packages.urllib3.disable_warnings()
# 请求,获得响应
response = requests.get(url, headers=headers, verify=False)
if response.status_code == 200:
# print(response.text)
# print(response.json())
print(response.text)
二、获取今日头条的评论信息(selenium请求获取)
ps:selenium模块其实是一个自动化测试工具,大家还可以深入了解,因为它不仅仅只能用来做爬虫。
还可以做为测试工具使用
1、分析数据
在使用selenium模块之前先确定好自己使用的浏览器的型号,因为知道后才能去下载属于自己的一个webdriver
比如我的浏览器型号
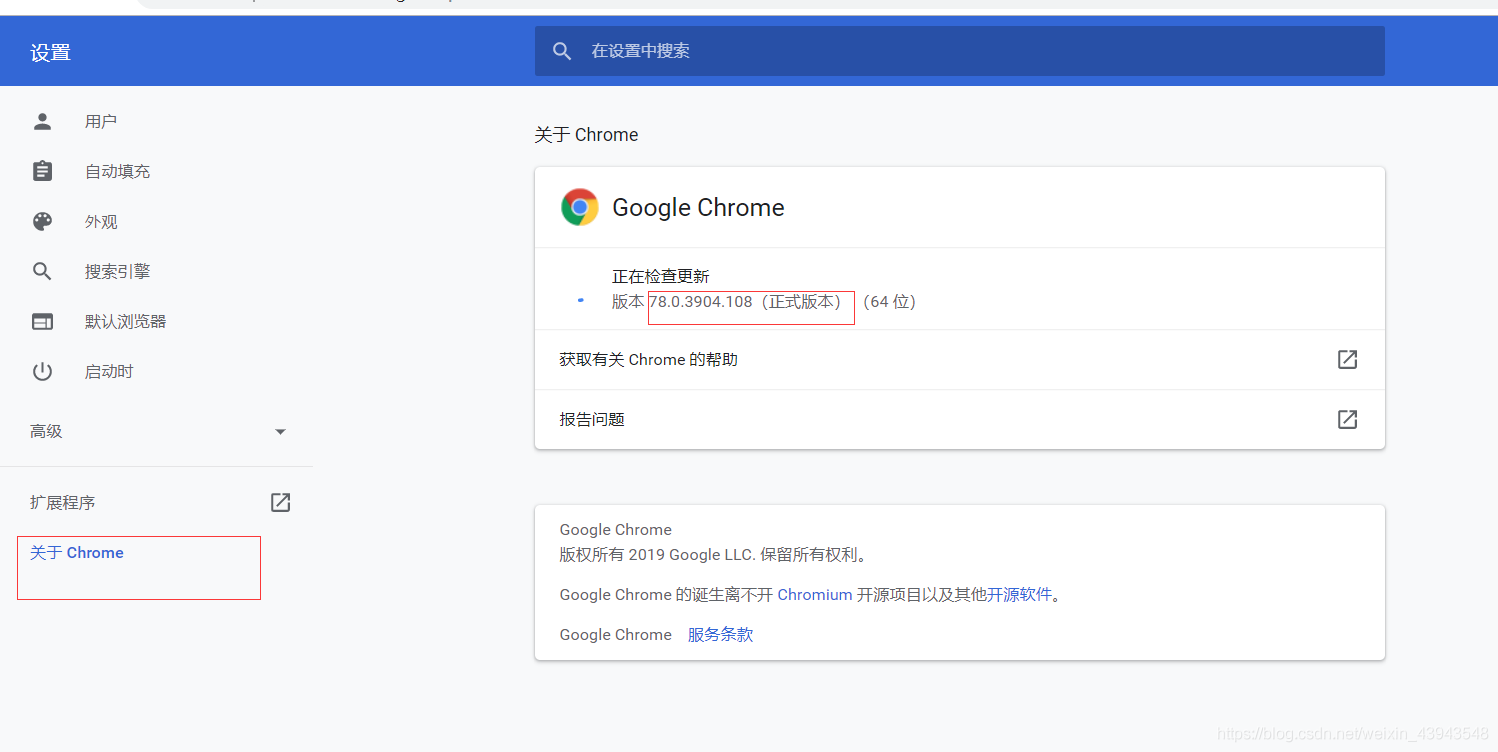
然后自行到网上找到自己浏览器的webdriver

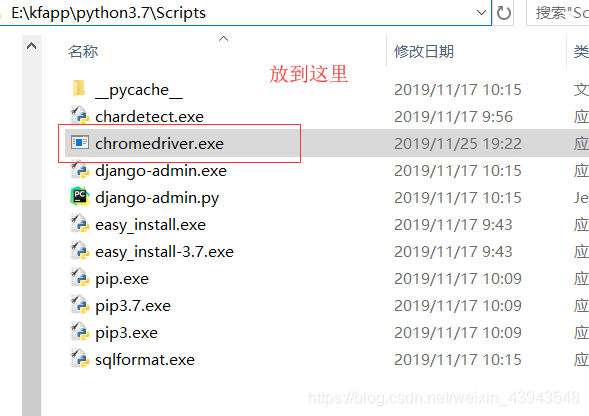
每个的浏览器的driver都不一样,我的就是chromedriver.exe
然后放到自己的python解释器下的script目录下
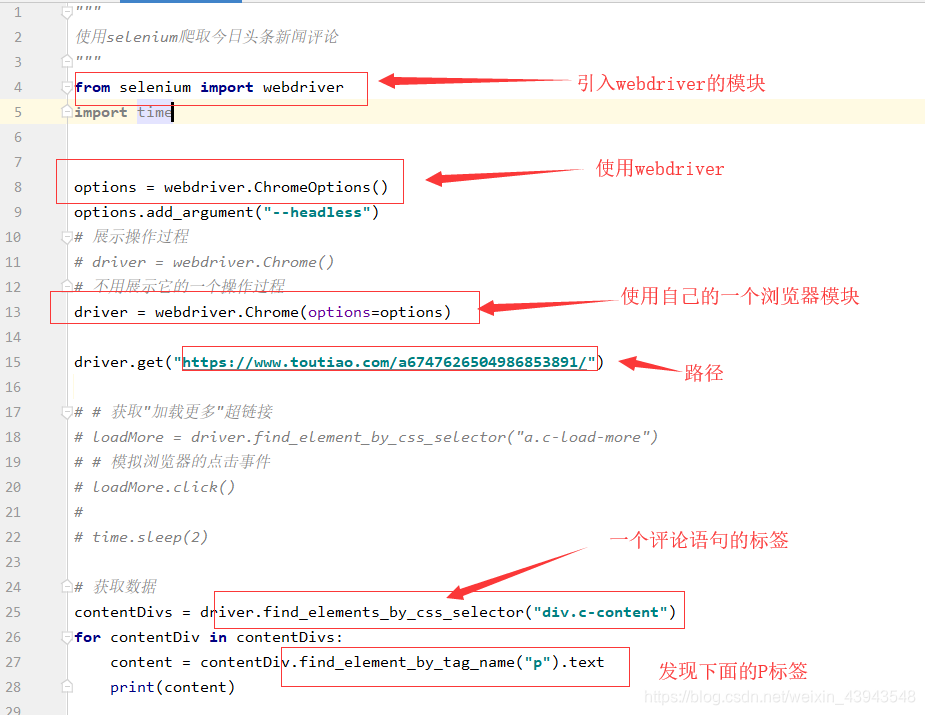
来我们来解析一下这个网站:https://www.toutiao.com/a6747626504986853891/
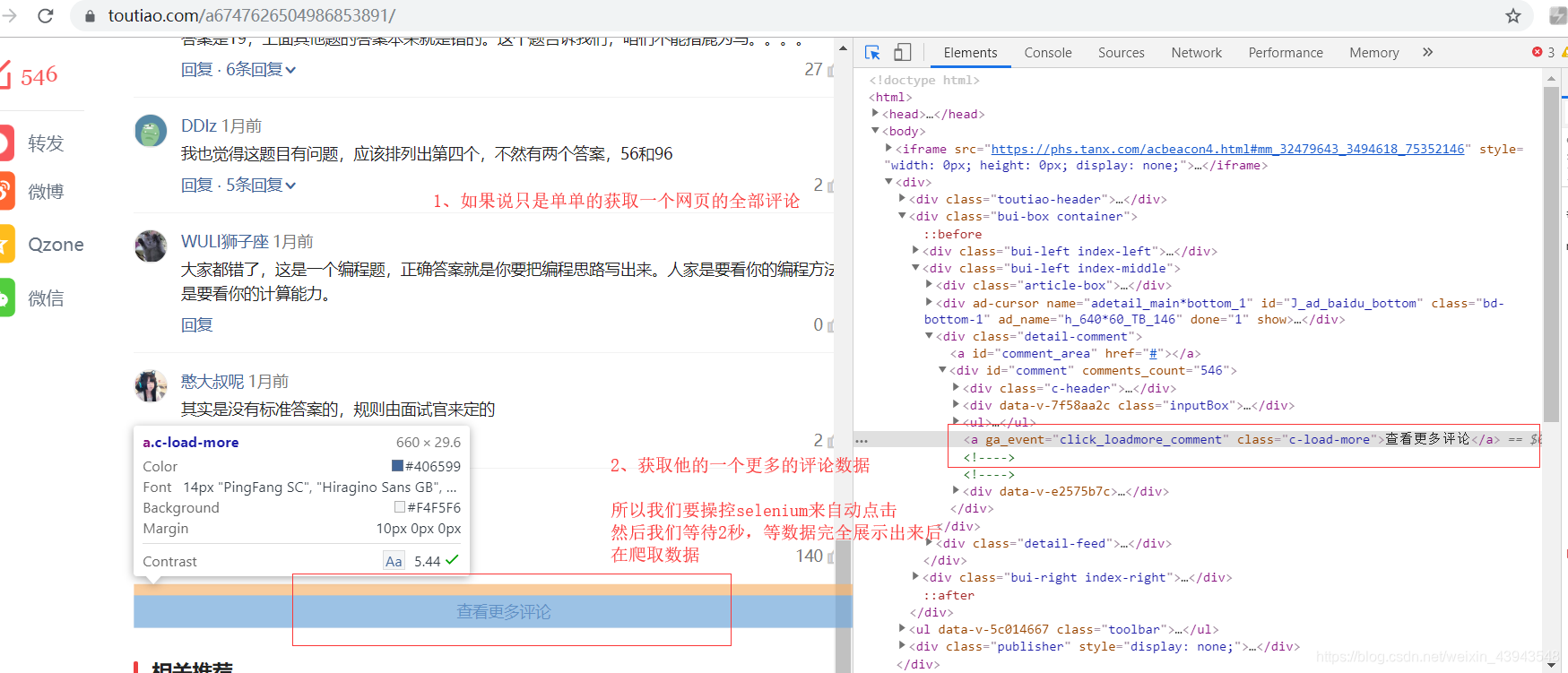
我们来看一看主体部分:
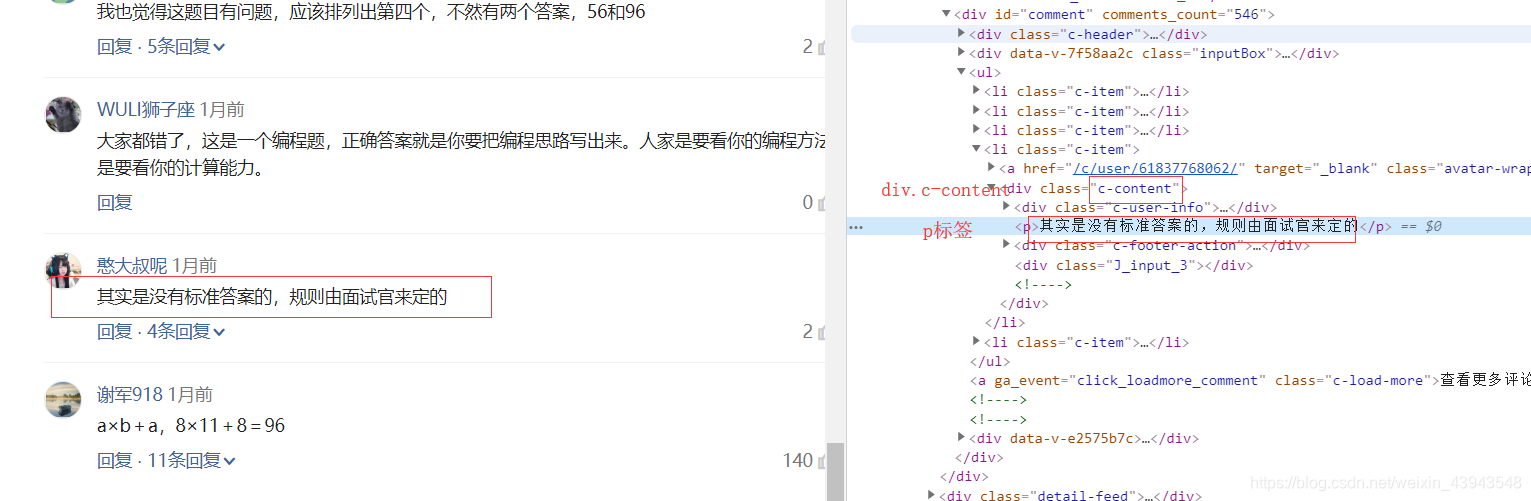
2、获取数据
引入调用,我在上面已经把我们可能所需要的东西都获取到。也讲解了一下一下;
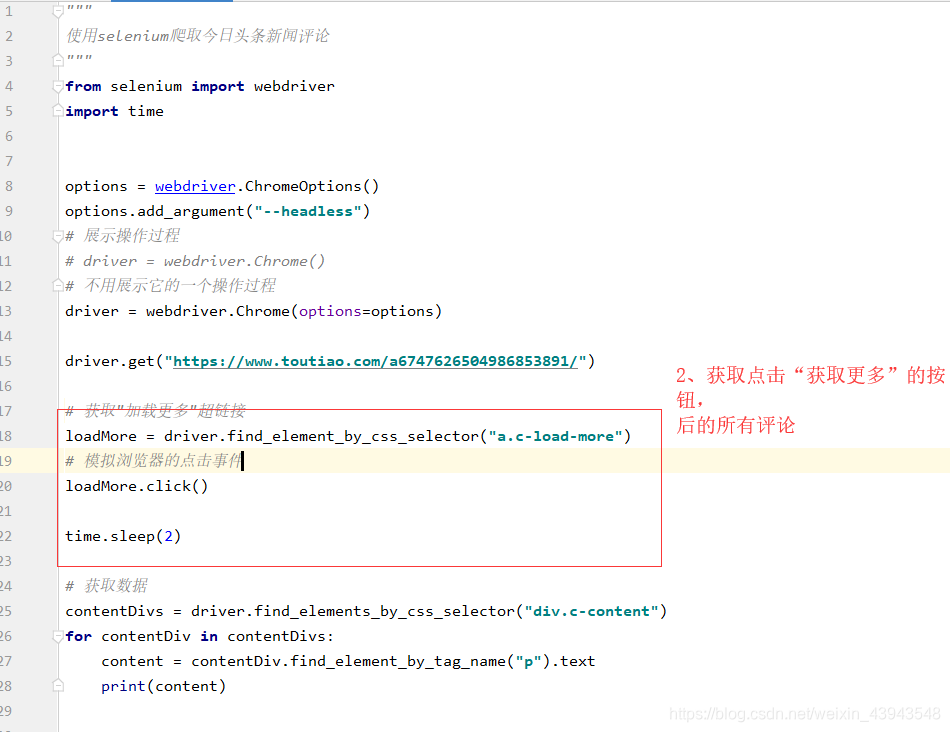
这个是加了一个python程序控制的点击事件。
lookthis....
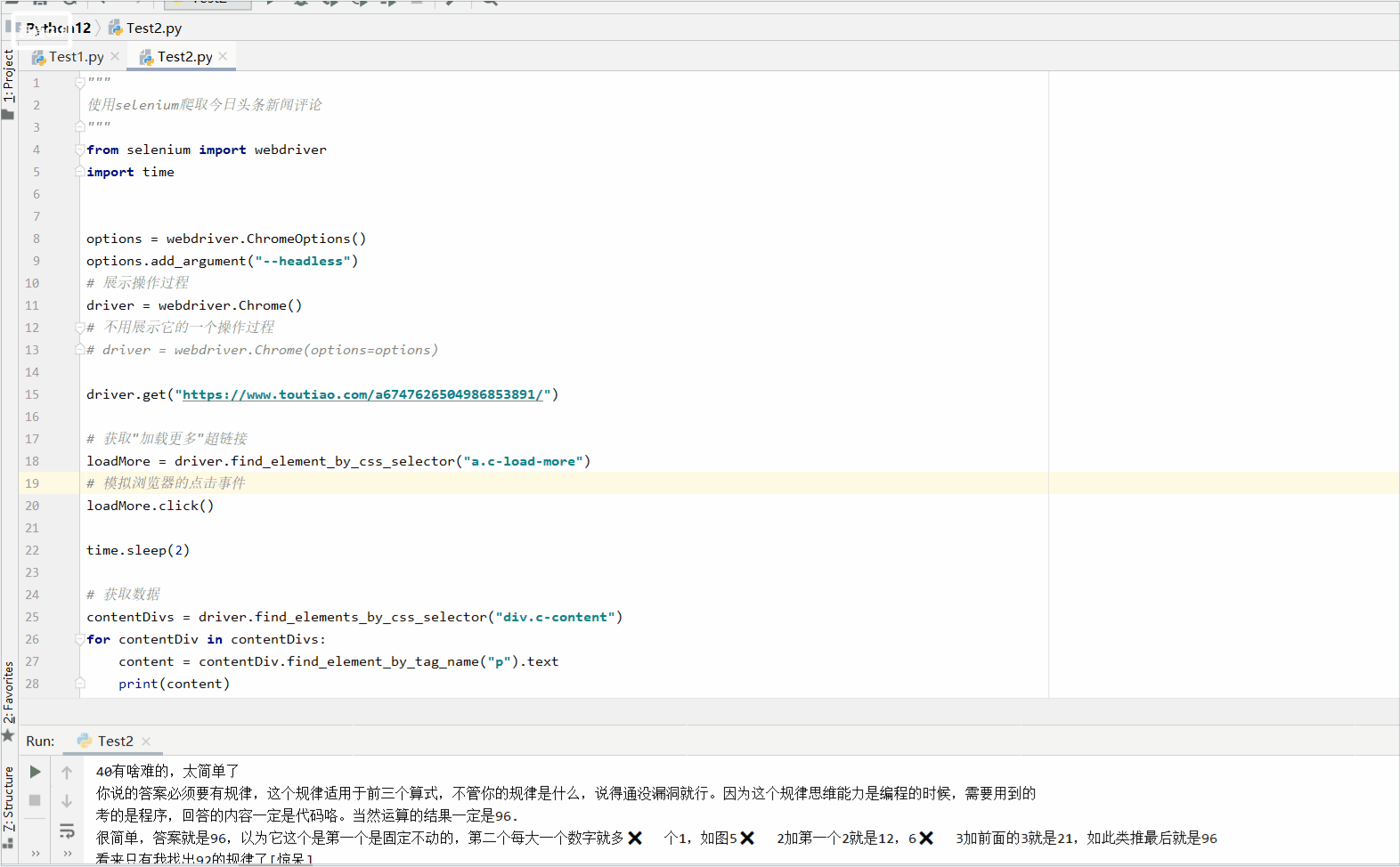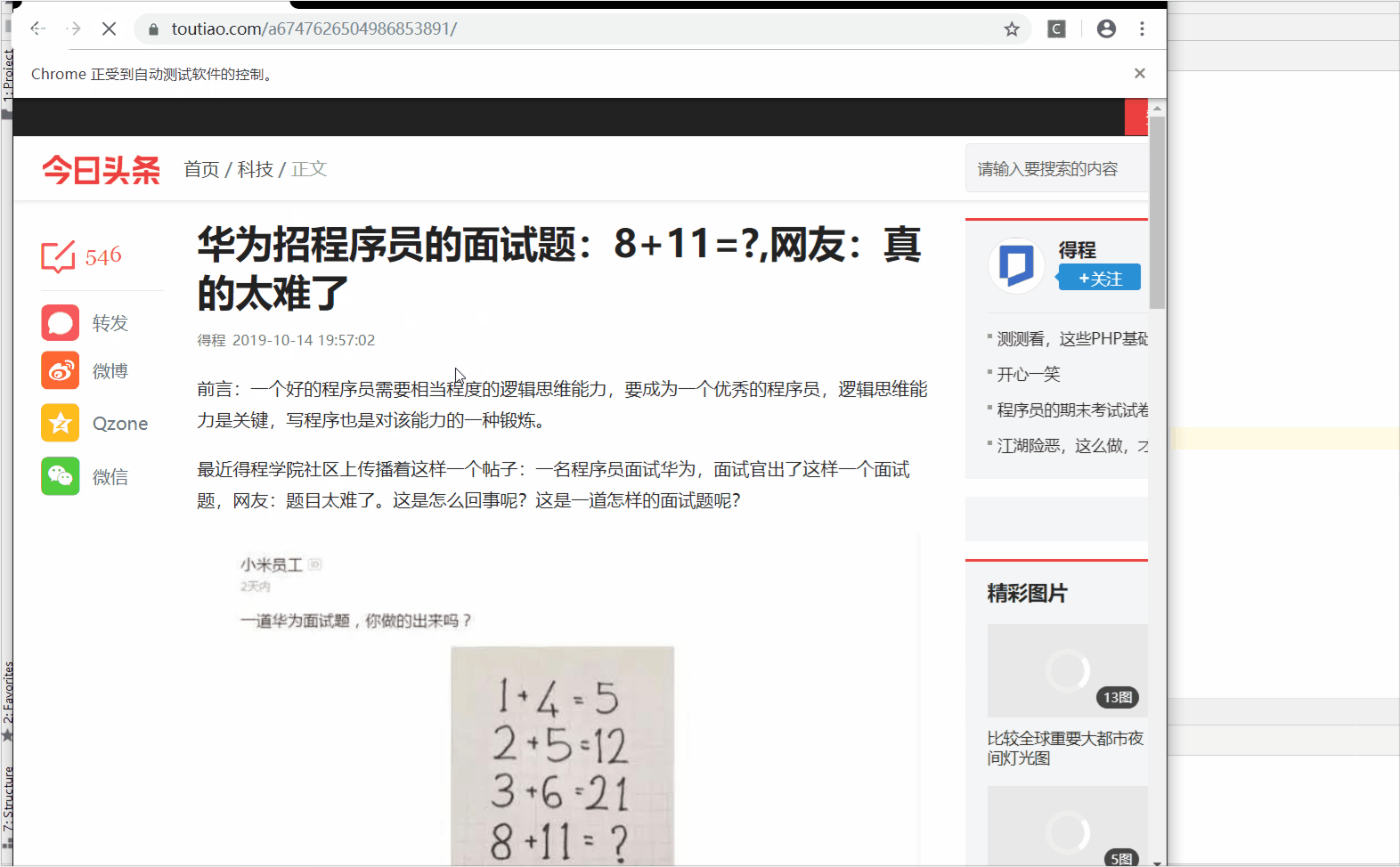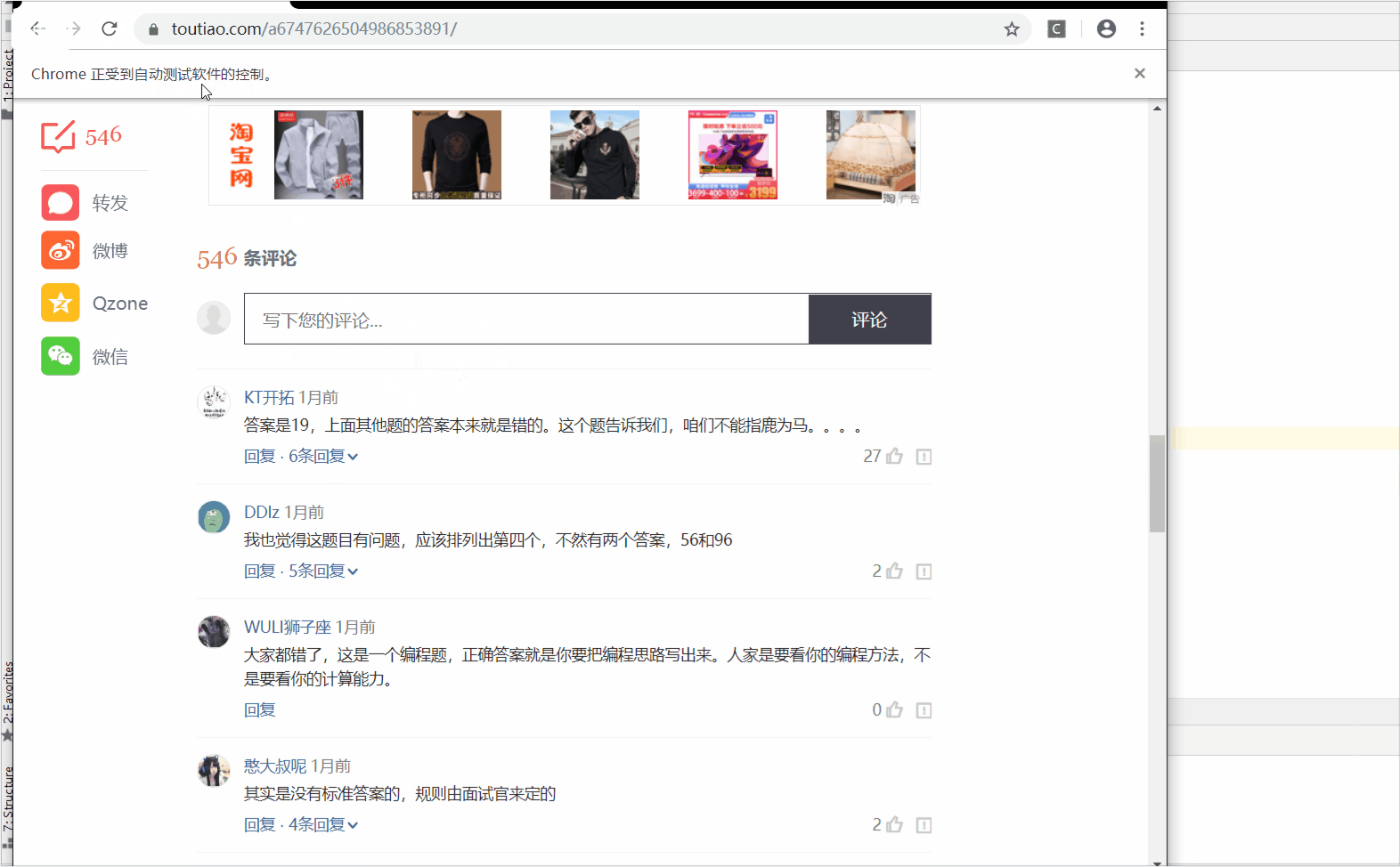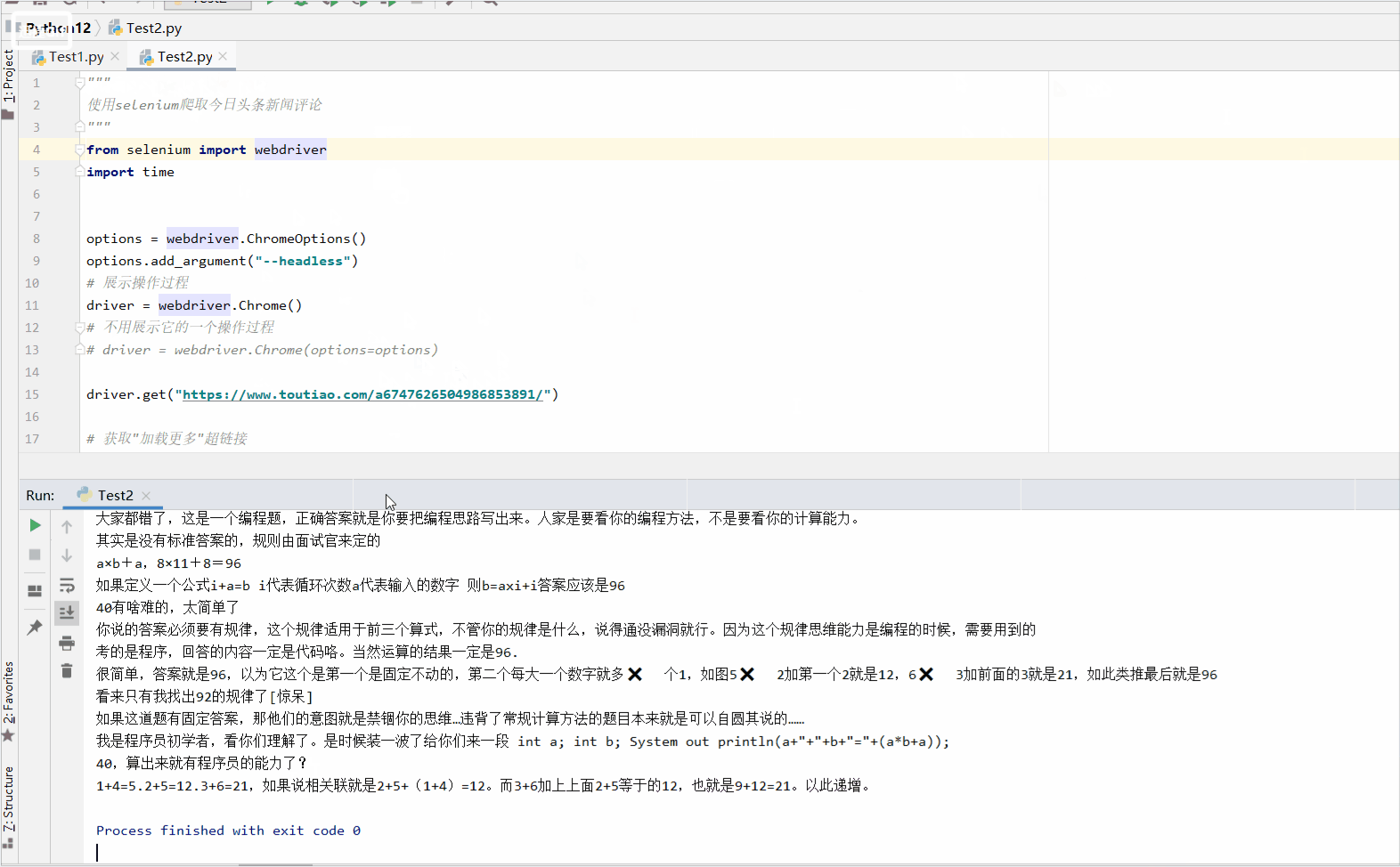
额,获取到了吧,嘿嘿
房源案例(仅供参考!!!,也许爬不了了)
"""
综合案例:
使用selenium爬取 airbnb房源信息
一个房源所有的信息:_gig1e7
名称:_qhtkbey
类型及大小:_fk7kh10里边的span
价格:_1ixtnfc里面的span
_1dir9an
"""
from selenium import webdriver
import time
options = webdriver.ChromeOptions()
options.add_argument("--headless")
driver = webdriver.Chrome(options=options)
for page in range(18):
print(f"第{page+1}页数据:")
driver.get(f"https://www.airbnb.cn/s/长沙/homes?refinement_paths%5B%5D=%2Fhomes¤t_tab_id=home_tab&selected_tab_id=home_tab&screen_size=large&hide_dates_and_guests_filters=false&place_id=ChIJxWQcnvM1JzQRgKbxoZy75bE&s_tag=vaaWeg7D§ion_offset=4&items_offset={page*18}&last_search_session_id=7d2afba3-cc47-434c-92be-65bac7643d3b")
houseAll = driver.find_elements_by_css_selector("div._gig1e7")
i = 1
for house in houseAll:
# 名称
name = house.find_element_by_css_selector("div._qhtkbey").text
# 价格
price = house.find_element_by_css_selector("div._1ixtnfc").text
newprice = price.replace("价格", "").replace("\n", "")
# 类型及大小
typeSize = house.find_element_by_css_selector("span._fk7kh10").text
type = typeSize.split(" · ")[0]
size = typeSize.split(" · ")[1]
print(f"{i} {name} {newprice} {type} {size}")
time.sleep(2)
i = i + 1
time.sleep(5)
上面内容只能慢慢思考问题了
但是这还有一个selenium的使用方法:
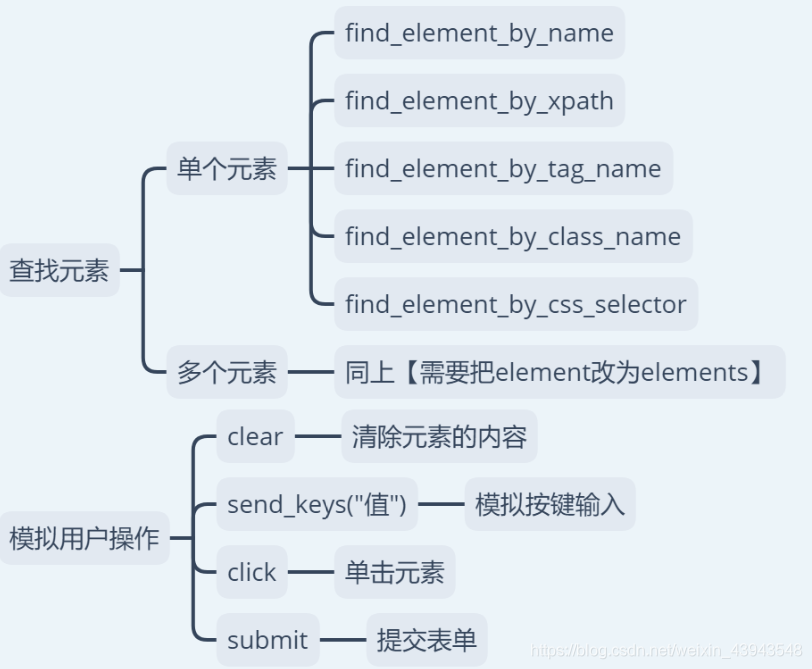

后记
还是那句话,好好的分析网页结构
如果感觉本章写的还不错的话,不如。。。。。(~ ̄▽ ̄)~ ,(´▽`ʃ♡ƪ)
python网络爬虫之自动化测试工具selenium[二]的更多相关文章
- Python 网络爬虫与信息获取(二)—— 页面内容提取
1. 获取超链接 python获取指定网页上所有超链接的方法 links = re.findall(b'"((http|ftp)s?://.*?)"', html) links = ...
- python网络爬虫之解析网页的正则表达式(爬取4k动漫图片)[三]
前言 hello,大家好 本章可是一个重中之重,因为我们今天是要爬取一个图片而不是一个网页或是一个json 所以我们也就不用用到selenium模块了,当然有兴趣的同学也一样可以使用selenium去 ...
- python 网络爬虫(二) BFS不断抓URL并放到文件中
上一篇的python 网络爬虫(一) 简单demo 还不能叫爬虫,只能说基础吧,因为它没有自动化抓链接的功能. 本篇追加如下功能: [1]广度优先搜索不断抓URL,直到队列为空 [2]把所有的URL写 ...
- python 网络爬虫(二)
一.编写第一个网络爬虫 为了抓取网站,我们需要下载含有感兴趣的网页,该过程一般被称为爬取(crawling).爬取一个网站有多种方法,而选择哪种方法更加合适,则取决于目标网站的结构. 首先探讨如何安全 ...
- 《精通python网络爬虫》笔记
<精通python网络爬虫>韦玮 著 目录结构 第一章 什么是网络爬虫 第二章 爬虫技能概览 第三章 爬虫实现原理与实现技术 第四章 Urllib库与URLError异常处理 第五章 正则 ...
- Python 网络爬虫干货总结
Python 网络爬虫干货总结 爬取 对于爬取来说,我们需要学会使用不同的方法来应对不同情景下的数据抓取任务. 爬取的目标绝大多数情况下要么是网页,要么是 App,所以这里就分为这两个大类别来进行了介 ...
- Python网络爬虫
http://blog.csdn.net/pi9nc/article/details/9734437 一.网络爬虫的定义 网络爬虫,即Web Spider,是一个很形象的名字. 把互联网比喻成一个蜘蛛 ...
- 如何利用Python网络爬虫抓取微信朋友圈的动态(上)
今天小编给大家分享一下如何利用Python网络爬虫抓取微信朋友圈的动态信息,实际上如果单独的去爬取朋友圈的话,难度会非常大,因为微信没有提供向网易云音乐这样的API接口,所以很容易找不到门.不过不要慌 ...
- Python网络爬虫学习总结
1.检查robots.txt 让爬虫了解爬取该网站时存在哪些限制. 最小化爬虫被封禁的可能,而且还能发现和网站结构相关的线索. 2.检查网站地图(robots.txt文件中发现的Sitemap文件) ...
随机推荐
- js 的隐式转换与显式转换
隐式转换 1.undefined与null相等,但不恒等(===) 2.一个是number一个是string时,会尝试将string转换为number 3.隐式转换将boolean转换为numbe ...
- iOS 原生库对 https 的处理
转载自:swift cafe 使用 NSURLSession NSURLSession 是 iOS 原生提供的网络处理库.它提供了丰富的接口以及配置选项,满足我们平时网络处理的大部分需求,同时它也支持 ...
- Prometheus 介绍详解
Prometheus 介绍 Prometheus(普罗米修斯)是一个最初在SoundCloud上构建的监控系统.自2012年成为社区开源项目,拥有非常活跃的开发人员和用户社区.为强调开源及独立维护,P ...
- Caused by: org.springframework.context.annotation.ConflictingBeanDefinitionException 异常
Caused by: org.springframework.context.annotation.ConflictingBeanDefinitionException 报此异常是应为有相同的bean ...
- C# 计时周期数(Ticks)在不同数据库上的实现
要在数据库中实现 DateTime.Ticks,先来看看 Ticks 在微软官方文档上的定义: 注解 一个计时周期表示一百纳秒,即一千万分之一秒. 毫秒内有 , 个计时周期,即 秒内有 , 万个计时周 ...
- SpringMVC----执行流程+底层解析
SpringMVC流程图如上面所示,根据上图,串联一下底层源码: 1.在DispatcherServlet中找到doDisPatch 2.观察方法体,然后找到getHandler方法 3.点进方法,发 ...
- 单(single):换根dp,表达式分析,高斯消元
虽说这题看大家都改得好快啊,但是为什么我感觉这题挺难.(我好菜啊) 所以不管怎么说那群切掉这题的大佬是不会看这篇博客的所以我要开始自嗨了. 这题,明显是树dp啊.只不过出题人想看你发疯,询问二合一了而 ...
- NOIP模拟测试2-5
该补一下以前挖的坑了 先总结一下 第二次 T1 搜索+剪枝 #include<cstdio> #include<iostream> #define ll long long u ...
- [转载]2.3 UiPath循环活动For Each的介绍和使用
一.For Each的介绍 For Each:循环迭代一个列表.数组.或其他类型的集合, 可以遍历并分别处理每条信息 二.For Each在UiPath中的使用 1.打开设计器,在设计库中新建一个Fl ...
- Android常见内存泄露
前言 对于内存泄漏,我想大家在开发中肯定都遇到过,只不过内存泄漏对我们来说并不是可见的,因为它是在堆中活动,而要想检测程序中是否有内存泄漏的产生,通常我们可以借助LeakCanary.MAT等工具来检 ...