堆 堆排序 优先队列 图文详解(Golang实现)

引入
在实际应用中,我们经常需要从一组对象中查找最大值或最小值。当然我们可以每次都先排序,然后再进行查找,但是这种做法效率很低。哪么有没有一种特殊的数据结构,可以高效率的实现我们的需求呢,答案就是堆(heap)
堆分为最小堆和最大堆,它们的性质相似,我们以最小堆为例子。
最小堆
举例
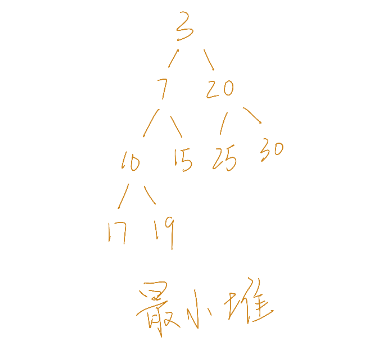
如上图所示,就为一个最小堆。
特性
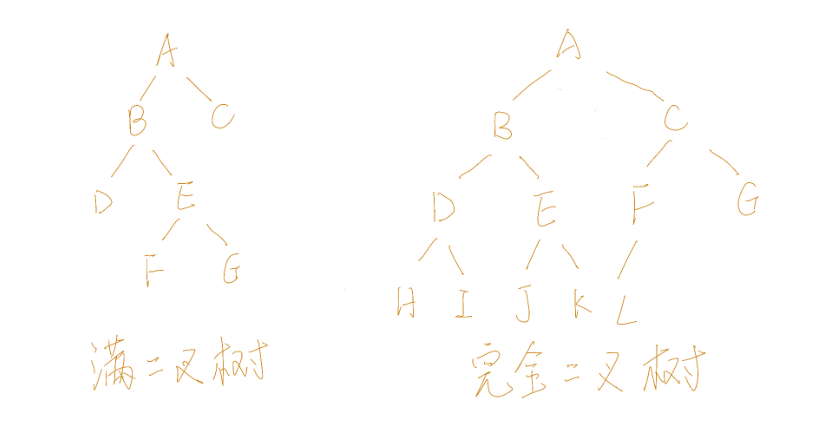
- 是一棵完全二叉树
如果一颗二叉树的任何结点,或者是树叶,或者左右子树均非空,则这棵二叉树称做满二叉树(full binary tree)
如果一颗二叉树最多只有最下面的两层结点度数可以小于2,并且最下面一层的结点都集中在该层最左边的连续位置上,则此二叉树称做完全二叉树(complete binary tree)
- 局部有序
最小堆对应的完全二叉树中所有结点的值均不大于其左右子结点的值,且一个结点与其兄弟之间没有必然的联系
二叉搜索树中,左子 < 父 < 右子
存储结构
由于堆是一棵完全二叉树,所以我们可以用顺序结构来存储它,只需要计算简单的代数表达式,就能够非常方便的查找某个结点的父结点和子节点,既避免了使用指针来保持结构,又能高效的执行相应操作。
结点i的左子结点为2xi+1,右子结点为2xi+2
结点i的父节点为(i-1)/2

数据结构
// 本例为最小堆
// 最大堆只需要修改less函数即可
type Heap []int
func (h Heap) swap(i, j int) {
h[i], h[j] = h[j], h[i]
}
func (h Heap) less(i, j int) bool {
return h[i] < h[j]
}
如上所示,我们使用slice来存储我们的数据,为了后续方便我们在此定义了 swap 和 less 函数,分别用来交换两个结点和比较大小。
插入-Push

如上图所示,首先,新添加的元素加入末尾。为了保持最小堆的性质,需要沿着其祖先的路径,自下而上依次比较和交换该结点与父结点的位置,直到重新满足堆的性质为止。
这样会出现两种情况,要么新结点升到最小堆的顶端,要么到某一位置时发现父结点比新插入的结点关键值小。
上面的流程代码如下:
func (h Heap) up(i int) {
for {
f := (i - 1) / 2 // 父亲结点
if i == f || h.less(f, i) {
break
}
h.swap(f, i)
i = f
}
}
实现了最核心的 up 操作后,我们的插入操作 push 便很简单,代码如下:
// 注意go中所有参数转递都是值传递
// 所以要让h的变化在函数外也起作用,此处得传指针
func (h *Heap) Push(x int) {
*h = append(*h, x)
h.up(len(*h) - 1)
}
删除-Remove
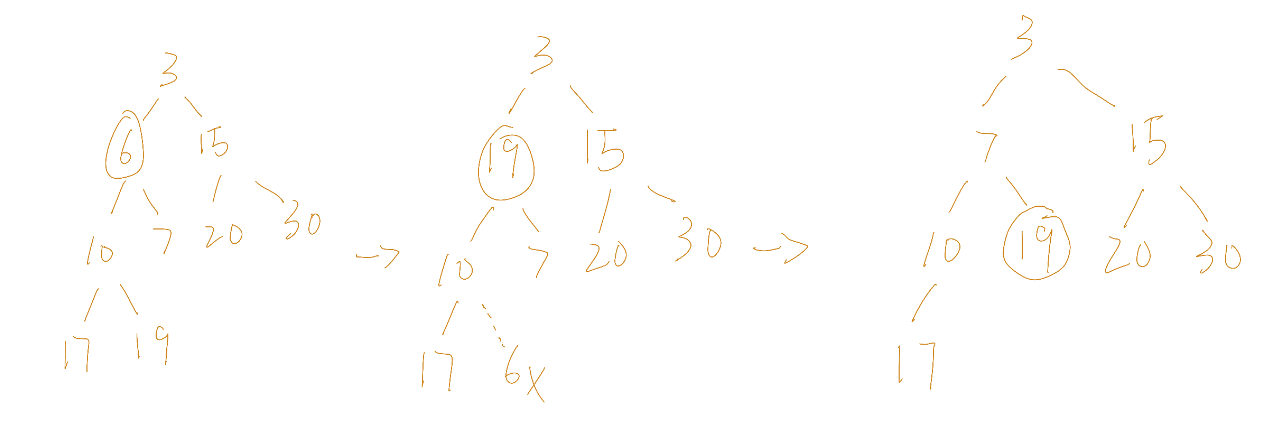
如上图所示,首先把最末端的结点填入要删除节点的位置,然后删除末端元素,同理,这样做也可能导致破坏最小堆的堆序特性。
为了保持堆的特性,末端元素需要与被删除位置的父结点做比较,如果小于父结点,就要up(详细代码看插入)如果大于父结点,就要再和被删除位置的子结点做比较,即down,直到该结点下降到小于最小子结点为止。
上面down的流程代码如下:
func (h Heap) down(i int) {
for {
l := 2*i + 1 // 左孩子
if l >= len(h) {
break // i已经是叶子结点了
}
j := l
if r := l + 1; r < len(h) && h.less(r, l) {
j = r // 右孩子
}
if h.less(i, j) {
break // 如果父结点比孩子结点小,则不交换
}
h.swap(i, j) // 交换父结点和子结点
i = j //继续向下比较
}
}
实现了核心的 down 操作后,我们的 Remove 便很简单,代码如下:
// 删除堆中位置为i的元素
// 返回被删元素的值
func (h *Heap) Remove(i int) (int, bool) {
if i < 0 || i > len(*h)-1 {
return 0, false
}
n := len(*h) - 1
h.swap(i, n) // 用最后的元素值替换被删除元素
// 删除最后的元素
x := (*h)[n]
*h = (*h)[0:n]
// 如果当前元素大于父结点,向下筛选
if (*h)[i] > (*h)[(i-1)/2] {
h.down(i)
} else { // 当前元素小于父结点,向上筛选
h.up(i)
}
return x, true
}
弹出-Pop
当i=0时,Remove 就是 Pop
// 弹出堆顶的元素,并返回其值
func (h *Heap) Pop() int {
n := len(*h) - 1
h.swap(0, n)
x := (*h)[n]
*h = (*h)[0:n]
h.down(0)
return x
}
初始化-Init
在我们讲完了堆的核心操作 up 和 down 后,我们来讲如何根据一个数组构造一个最小堆。
其实我们可以写个循环,然后将各个元素依次 push 进去,但是这次我们利用数学规律,直接由一个数组构造最小堆。
首先,将所有关键码放到一维数组中,此时形成的完全二叉树并不具备最小堆的特征,但是仅包含叶子结点的子树已经是堆。
即在有n个结点的完全二叉树中,当 i>n/2-1 时,以i结点为根的子树已经是堆。
func (h Heap) Init() {
n := len(h)
// i > n/2-1 的结点为叶子结点本身已经是堆了
for i := n/2 - 1; i >= 0; i-- {
h.down(i)
}
}
测试
func main() {
var h = heap.Heap{20, 7, 3, 10, 15, 25, 30, 17, 19}
h.Init()
fmt.Println(h) // [3 7 20 10 15 25 30 17 19]
h.Push(6)
fmt.Println(h) // [3 6 20 10 7 25 30 17 19 15]
x, ok := h.Remove(5)
fmt.Println(x, ok, h) // 25 true [3 6 15 10 7 20 30 17 19]
y, ok := h.Remove(1)
fmt.Println(y, ok, h) // 6 true [3 7 15 10 19 20 30 17]
z := h.Pop()
fmt.Println(z, h) // 3 [7 10 15 17 19 20 30]
}
完整代码
堆排序
在讲完堆的基础知识后,我们再来看堆排序就变得非常简单。利用最小堆的特性,我们每次都从堆顶弹出一个元素(这个元素就是当前堆中的最小值),即可实现升序排序。代码如下:
// 堆排序
var res []int
for len(h) != 0 {
res = append(res, h.Pop())
}
fmt.Println(res)
优先队列
优先队列是0个或者多个元素的集合,每个元素都有一个关键码,执行的操作有查找,插入和删除等。
优先队列的主要特点是支持从一个集合中快速地查找并移出具有最大值或最小值的元素。
堆是一种很好的优先队列的实现方法。
参考资料
- 《数据结构与算法》张铭 王腾蛟 赵海燕 编著
- GO SDK 1.13.1 /src/container/heap
最后
本文是自己的学习笔记,在刷了几道LeetCode中关于堆的题目后,感觉应该系统的学习和总结一下这一重要的数据结构了。
强烈建议看Go的源码中关于heap的实现,仔细感受面向接口编程的思想,和他们的代码风格以及质量。
堆 堆排序 优先队列 图文详解(Golang实现)的更多相关文章
- ElasticSearch实战系列八: Filebeat快速入门和使用---图文详解
前言 本文主要介绍的是ELK日志系统中的Filebeat快速入门教程. ELK介绍 ELK是三个开源软件的缩写,分别表示:Elasticsearch , Logstash, Kibana , 它们都是 ...
- CentOS 6.3下Samba服务器的安装与配置方法(图文详解)
这篇文章主要介绍了CentOS 6.3下Samba服务器的安装与配置方法(图文详解),需要的朋友可以参考下 一.简介 Samba是一个能让Linux系统应用Microsoft网络通讯协议的软件, ...
- Cocos2d-x win7 + vs2010 配置图文详解
Cocos2d-x win7 + vs2010 配置图文详解 下载最新版的cocos2d-x.打开浏览器,输入cocos2d-x.org,然后选择Download,本教程写作时最新版本为cocos2d ...
- zookeeper的安装(图文详解。。。来点击哦!)
zookeeper的安装(图文详解...来点击哦!) 一.服务器的配置 三台服务器: 192.168.83.133 sunshine 192.168.83.134 sunshineMin 19 ...
- Hadoop集群搭建安装过程(三)(图文详解---尽情点击!!!)
Hadoop集群搭建安装过程(三)(图文详解---尽情点击!!!) 一.JDK的安装 安装位置都在同一位置(/usr/tools/jdk1.8.0_73) jdk的安装在克隆三台机器的时候可以提前安装 ...
- Hadoop集群搭建安装过程(二)(图文详解---尽情点击!!!)
Hadoop集群搭建安装过程(二)(配置SSH免密登录)(图文详解---尽情点击!!!) 一.配置ssh无密码访问 ®生成公钥密钥对 1.在每个节点上分别执行: ssh-keygen -t rsa(一 ...
- Linux虚拟机安装(CentOS 6.5,图文详解,需要自查)
Linux虚拟机的安装(图文详解) 下篇会接续Hadoop集群安装(以此为基础) 一.安装准备 VMWorkstation.linux系统镜像(以下以CentOS6.5为例) 二.安装过程详解 关闭防 ...
- 分享我开发的网络电话Android手机APP正式版,图文详解及下载
分享我开发的网络电话Android手机APP正式版,图文详解及下载 分享我开发的网络电话Android手机APP正式版 实时语音通讯,可广域网实时通讯,音质清晰流畅! 安装之后的运行效果: 第一次安装 ...
- 图文详解Unity3D中Material的Tiling和Offset是怎么回事
图文详解Unity3D中Material的Tiling和Offset是怎么回事 Tiling和Offset概述 Tiling表示UV坐标的缩放倍数,Offset表示UV坐标的起始位置. 这样说当然是隔 ...
随机推荐
- python学习-while True语句
while True是不会跳出循环的. 在while中括号里为一个条件值,只有当条件为真的时候,会执行这条语句,直到条件为false的时候,则会跳出该循环语句.而在这里括号里的值为true,也就意味着 ...
- GC 知识点补充——CMS
之前已经讲过了不少有关 GC 的内容,今天准备将之前没有细讲的部分进行补充,首先要提到的就是垃圾收集器. 基础的回收方式有三种:清除.压缩.复制,衍生出来的垃圾收集器有: Serial 收集器 新生代 ...
- Flask解析(二):Flask-Sqlalchemy与多线程、多进程
Sqlalchemy flask-sqlalchemy的session是线程安全的,但在多进程环境下,要确保派生子进程时,父进程不存在任何的数据库连接,可以通过调用db.get_engine(app= ...
- SpringCloud之异常报警通知(八)
在之前整合降级的基础上,整合redis,达到报警的效果(redis的启动还是之前boot里面整合的redis) order-service pom.xml <dependency> < ...
- 运营的Python指南 - Python 操作Excel
这是一份写给运营人员的Python指南.本文主要讲述如何使用Python操作Excel.完成Excel的创建,查询和修改操作. 相关代码请参考 https://github.com/RustFishe ...
- 适用于Windows桌面应用程序的.NET Core 3
介绍 9月,微软发布了新版.NET Core,用于构建Windows桌面应用程序,包括WPF和Windows Forms.从那时起开发人员可以将传统的nfx桌面应用程序(和控件库)迁移到.NET Co ...
- C函数库ctype.h概况
1 字符测试函数 1> 函数原型均为int isxxxx(int) 2> 参数为int, 任何实参均被提升成整型 3> 只能正确处理处于[0, 127]之间的值 2 字符映射函数 1 ...
- [考试反思]0919csp-s模拟测试47:苦难
ISOLATION 也不粘上面的了,先管好自己. 附了个近期总分,可以看出什么. 反思一下考试心态: 开场看题目,T1傻逼题不用脑子,T2傻逼板子,T3... 这T3是啥啊?没看懂题目啊?再看一遍.啥 ...
- 随(rand):原根,循环矩阵,dp
20分特判,一个puts("1")一个快速幂,不讲. 50%算法: 上次就讲了,可是应该还是有像 xuefen某 或 Dybal某 一样没听的. 用a×inv(b)%mod来表示分 ...
- 零基础小白入门IT开发指南
先自我介绍以下,本人是一枚刚毕业不到两年的某一线城市的程序员,本科阶段专业是计算机科学与技术.从大四开始出去实习到现在的编码经验也有快2年半了,两年半的时间包括实习在内任职过有4家公司,包括一家互联网 ...