Python高级应用程序设计任务期末作业
Python高级应用程序设计任务要求
用Python实现一个面向主题的网络爬虫程序,并完成以下内容:
(注:每人一题,主题内容自选,所有设计内容与源代码需提交到博客园平台)
一、主题式网络爬虫设计方案(15分)
1.主题式网络爬虫名称
爬取网易云音乐歌单
2.主题式网络爬虫爬取的内容与数据特征分析
爬取网易云音乐歌单前十页歌单,说唱类型的歌单名称、歌单播放量、歌单链接、用户名称。
分析歌单播放量和歌单标题关键词
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)
实现思路:使用单线程爬取,初始化信息,设置请求头部信息,获取网页资源,使用etree进行网页解析,爬取多页时刷新offset,将爬取数据保存到csv文件中。
难点:使用的翻页形式为URL的limit和offset参数,发送的get请求时froms和url的参数要一至。
二、主题页面的结构特征分析(15分)
1.主题页面的结构特

2.Htmls页面解析


3.节点(标签)查找方法与遍历方法
(必要时画出节点树结构)
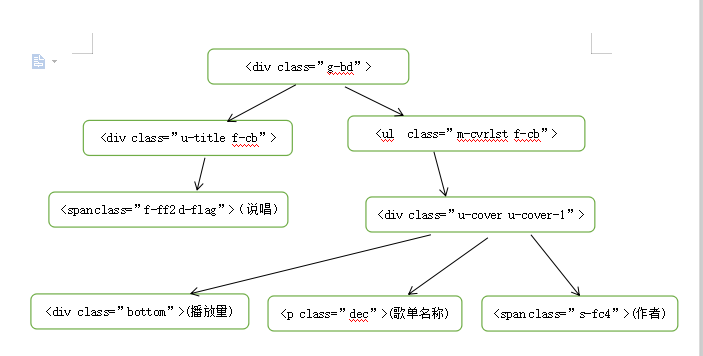
三、网络爬虫程序设计(60分)
爬虫程序主体要包括以下各部分,要附源代码及较详细注释,并在每部分程序后面提供输出结果的截图。
1.数据爬取与采集
from urllib import parse
from lxml import etree
from urllib3 import disable_warnings
import requests
import csv
class Wangyiyun(object): def __init__(self, **kwargs):
# 歌单的歌曲风格
self.types = kwargs['types']
# 歌单的发布类型
self.years = kwargs['years']
# 这是当前爬取的页数
self.pages = pages
# 这是请求的url参数(页数)
self.limit = 35
self.offset = 35 * self.pages - self.limit
# 这是请求的url
self.url = "https://music.163.com/discover/playlist/?" # 设置请求头部信息(可扩展:不同的User - Agent)
def set_header(self):
self.header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36",
"Referer": "https://music.163.com/",
"Upgrade-Insecure-Requests": '1',
}
return self.header # 设置请求表格信息
def set_froms(self):
self.key = parse.quote(self.types)
self.froms = {
"cat": self.key,
"order": self.years,
"limit": self.limit,
"offset": self.offset,
}
return self.froms # 解析代码,获取有用的数据
def parsing_codes(self):
page = etree.HTML(self.code)
# 标题
self.title = page.xpath('//div[@class="u-cover u-cover-1"]/a[@title]/@title')
# 作者
self.author = page.xpath('//p/a[@class="nm nm-icn f-thide s-fc3"]/text()')
# 阅读量
self.listen = page.xpath('//span[@class="nb"]/text()')
# 歌单链接
self.link = page.xpath('//div[@class="u-cover u-cover-1"]/a[@href]/@href')
# 将数据保存为csv文件
data=list(zip(self.title,self.author,self.listen,self.link))
with open('yinyue.csv','a',encoding='utf-8',newline='') as f:
writer=csv.writer(f)
#writer.writerow(header)
writer.writerows(data)
# 获取网页源代码
def get_code(self):
disable_warnings()
self.froms['cat']=self.types
disable_warnings()
self.new_url = self.url+parse.urlencode(self.froms)
self.code = requests.get(
url = self.new_url,
headers = self.header,
data = self.froms,
verify = False,
).text # 爬取多页时刷新offset
def multi(self ,page):
self.offset = self.limit * page - self.limit if __name__ == '__main__':
# 歌单的歌曲风格
types = "说唱"
# 歌单的发布类型:最热=hot,最新=new
years = "hot"
# 指定爬取的页数
pages = 10
# 通过pages变量爬取指定页面
music = Wangyiyun(
types = types,
years = years,
)
for i in range(pages):
page = i+1 # 因为没有第0页
music.multi(page) # 爬取多页时指定,传入当前页数,刷新offset
music.set_header() # 调用头部方法,构造请求头信息
music.set_froms() # 调用froms方法,构造froms信息
music.get_code() # 获取当前页面的源码
music.parsing_codes() # 处理源码,获取指定数据
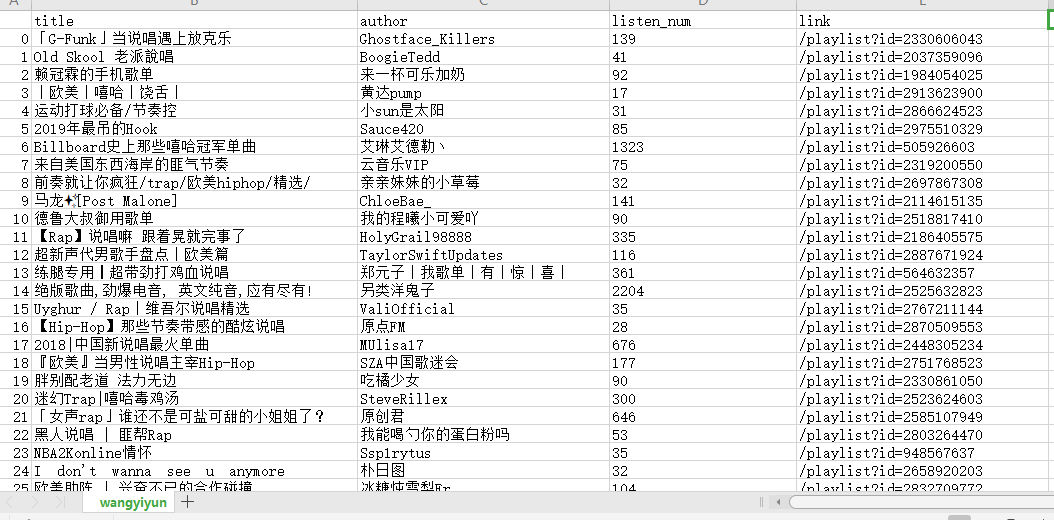
2.对数据进行清洗和处理
import pandas as pd
#读取文件
data=pd.read_csv(r"yinyue.csv",encoding = "utf-8")
data.columns=('title','author','listen_num','link')
data
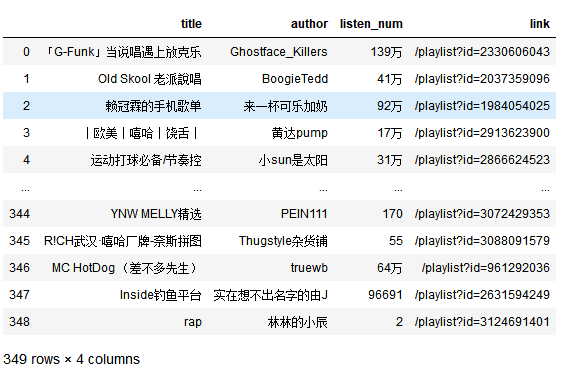
#删除没有万单位的行
data = data[data["listen_num"].str[-1] == "万"]
data
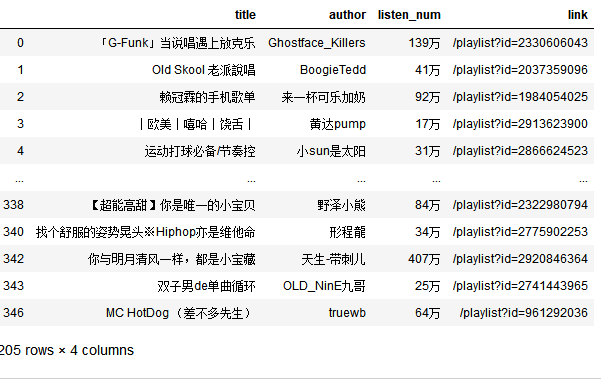
#删除万单位
data['listen_num'] = data['listen_num'].str.strip("万").apply(int)
data
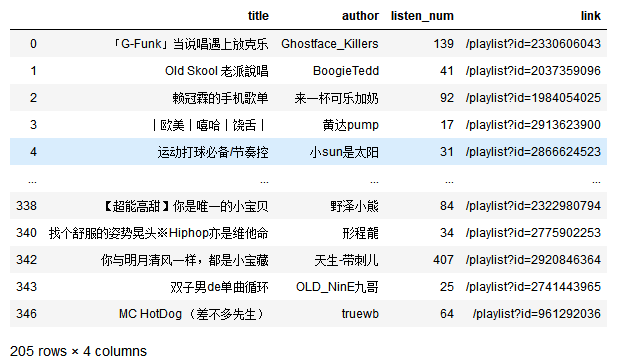
#删除重复值
data=data.drop_duplicates()
data.head()

data.describe()

#按播放数量进行降序排序
data = data.sort_values('listen_num',ascending = False).head(10)
data

3.文本分析(可选):jieba分词、wordcloud可视化
4.数据分析与可视化
(例如:数据柱形图、直方图、散点图、盒图、分布图、数据回归分析等)
import seaborn as sns
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib
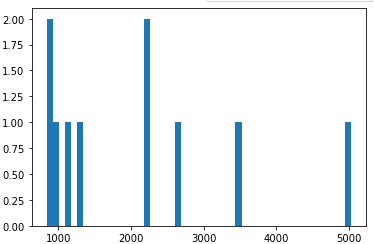
#绘制柱状图查看top50歌单的播放量分布
plt.hist(data['listen_num'],bins=50)
plt.show()
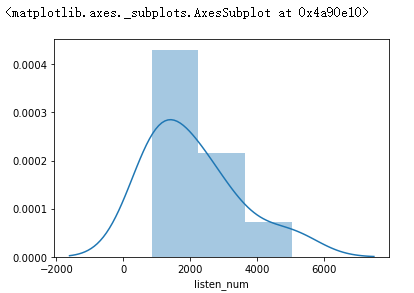
#绘制直方图查看播放数量的分布
sns.distplot(data['listen_num'])
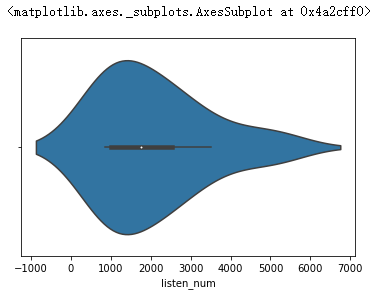
sns.violinplot(data['listen_num'])
#绘制饼状图
plt.rcParams['font.sans-serif'] = ['SimHei']#解决乱码问题
df_score = data['listen_num'].value_counts() #统计评分情况
plt.title("播放数量占比图") #设置饼图标题
plt.pie(df_score.values,labels = df_score.index,autopct='%1.1f%%') #绘图
#autopct表示圆里面的文本格式,在python里%操作符可用于格式化字符串操作
plt.show()

5.数据持久化
data.to_csv("./wangyiyun.csv")
四、结论(10分)
1.经过对主题数据的分析与可视化,可以得到哪些结论?
①数据分析时爬取的数据比较乱,要经过一个连套的数据清洗。
②数据清洗对数据可视化提供了很大的方便。
③top50歌单播放量大部分集中在1000万左右。
④歌单前十页的说唱类型播放量在1000万到2000万居多。
2.对本次程序设计任务完成的情况做一个简单的小结。
在爬取数据过程中,在解析网页代码时,返回的是空列表,经过检查网页源代码,发现原来我们所提取的元素包含在<iframe>标签内部,这样我们是无法直接定位的,所以必须先切换到iframe中,在爬去过程中小问题很多,到最后爬取到的数据也很“脏”,但是经过数据清洗后,还是可得到一些结论的,经过本次作业中,学习到了必须有耐心和细心,这在往后的码农生涯将会很受用。
Python高级应用程序设计任务期末作业的更多相关文章
- Python高级应用程序设计任务
Python高级应用程序设计任务要求 用Python实现一个面向主题的网络爬虫程序,并完成以下内容:(注:每人一题,主题内容自选,所有设计内容与源代码需提交到博客园平台) 一.主题式网络爬虫设计方案( ...
- Python高级应用程序设计任务要求
Python高级应用程序设计任务要求 用Python实现一个面向主题的网络爬虫程序,并完成以下内容:(注:每人一题,主题内容自选,所有设计内容与源代码需提交到博客园平台) 一.主题式网络爬虫设计方案( ...
- 2016-2017-2 《Java程序设计》预备作业2总结
2016-2017-2 <Java程序设计>预备作业2总结 古希腊学者普罗塔戈说过:「头脑不是一个要被填满的容器,而是一束需要被点燃的火把.」 在对计算机系的学生情况的调查中,我说: 最近 ...
- SDN期末作业验收
作业链接:https://edu.cnblogs.com/campus/fzu/SoftwareDefinedNetworking2017/homework/1585 负载均衡程序 1.github链 ...
- SDN期末作业——负载均衡
作业链接 期末作业 1.负载均衡程序 代码 2.演示视频 地址 3.小组分工 小组:incredible five 构建拓扑:俞鋆 编写程序:陈绍纬.周龙荣 程序调试和视频录制:陈辉.林德望 4.个人 ...
- 老男孩Python高级全栈开发工程师三期完整无加密带课件(共104天)
点击了解更多Python课程>>> 老男孩Python高级全栈开发工程师三期完整无加密带课件(共104天) 课程大纲 1.这一期比之前的Python培新课程增加了很多干货:Linux ...
- 老男孩Python高级全栈开发工程师【真正的全套完整无加密】
点击了解更多Python课程>>> 老男孩Python高级全栈开发工程师[真正的全套完整无加密] 课程大纲 老男孩python全栈,Python 全栈,Python教程,Django ...
- python 高级之面向对象初级
python 高级之面向对象初级 本节内容 类的创建 类的构造方法 面向对象之封装 面向对象之继承 面向对象之多态 面向对象之成员 property 1.类的创建 面向对象:对函数进行分类和封装,让开 ...
- python高级之函数
python高级之函数 本节内容 函数的介绍 函数的创建 函数参数及返回值 LEGB作用域 特殊函数 函数式编程 1.函数的介绍 为什么要有函数?因为在平时写代码时,如果没有函数的话,那么将会出现很多 ...
随机推荐
- Gson的序列化和反序列化-待更新
反序列化为List List<Person> persons =gson.fromJson(json, new TypeToken<List<Person>>() ...
- P4287 [SHOI2011]双倍回文
题意 考虑对每个节点\(x\)维护\(lastpos_x\)表示\(x\)的所有后缀回文串中第一个\(len\leqslant len_x/2\)并且能和\(x\)最后一个字符匹配的,之后枚举节点,判 ...
- zabbix--完整安装攻略
zabbix:是一个基于WEB界面的提供分布式系统监视以及网络监视功能的企业级的开源解决方案. zabbix能监视各种网络参数,保证服务器系统的安全运营:并提供灵活的通知机制以让系统管理员快速定位/解 ...
- Fira Code:适合程序员的编程字体
#Fira Code Fira 是 Mozilla 公司 主推的字体系列.Fira Code 是其中的一员,专为写程序而生.出来具有等宽等基本属性外,还加入了编程连字特性(ligatures). Fi ...
- Spring案例--打印机
目录: 1.applicationContext.xml配置文件 <?xml version="1.0" encoding="UTF-8"?> &l ...
- Spring Boot 2.2.0新特性
Spring Boot 2.2.0 正式发布了,可从 repo.spring.io 或是 Maven Central 获取. 性能提升 Spring Boot 2.2.0 的性能获得了很大的提升. ...
- Flink on Yarn的两种模式及HA
转自:https://blog.csdn.net/a_drjiaoda/article/details/88203323 Flink on Yarn模式部署始末:Flink的Standalone和on ...
- MySQL应用之CROSS JOIN用法简介教程
目录 2. cross join用法 @ 本博客翻译自两篇博客的: http://www.mysqltutorial.org/mysql-cross-join/ https://www.w3resou ...
- WEB引入Google思源黑体
通过Link标签在网页头部引用Google Web Font: 1 <link rel="stylesheet" href="https://fonts.googl ...
- 来认识一下venus-init——一个让你仅需一个命令开始Java开发的命令行工具
源代码地址: Github仓库地址 个人网站:个人网站地址 前言 不知道你是否有过这样的经历.不管你是什么岗位,前端也好,后端也罢,想去了解一下Java开发到底是什么样的,它是不是真的跟传说中的一样. ...