【RocketMQ】DLedger模式下的选主流程分析
RocketMQ 4.5版本之前,可以采用主从架构进行集群部署,但是如果master节点挂掉,不能自动在集群中选举出新的Master节点,需要人工介入,在4.5版本之后提供了DLedger模式,使用Raft算法,如果Master节点出现故障,可以自动选举出新的Master进行切换。
Raft协议
Raft是分布式系统中的一种共识算法,用于在集群中选举Leader管理集群。Raft协议中有以下角色:
Leader(领导者):集群中的领导者,负责管理集群。
Candidate(候选者):具有竞选Leader资格的角色,如果集群需要选举Leader,节点需要先转为候选者角色才可以发起竞选。
Follower(跟随者 ):Leader的跟随者,接收和处理来自Leader的消息,与Leader之间保持通信,如果通信超时或者其他原因导致节点与Leader之间通信失败,节点会认为集群中没有Leader,就会转为候选者发起竞选,推荐自己成为Leader。
Raft协议中还有一个Term(任期/轮次)的概念,任期会随着每一轮选举发生变化,一般是单调递增,比如说集群中当前的任期为1,此时某个节点发现集群中没有Leader,开始发起竞选,此时任期编号就会增加为2,表示进行了新一轮的选举。一般会为Term较大的那个节点进行投票,当某个节点收到了过半Quorum的投票数(一般是集群中的节点数/2 + 1),将会被选举为Leader。
RocketMQ在开启Dledger时,使用DLedgerCommitLog,其他情况使用的是CommitLog来管理消息的存储。
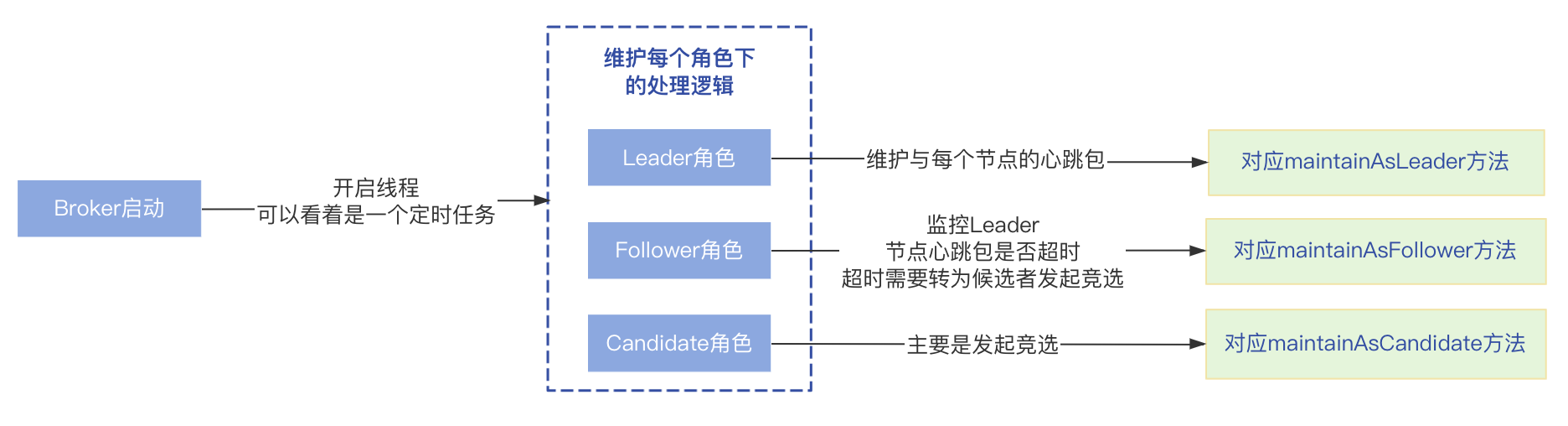
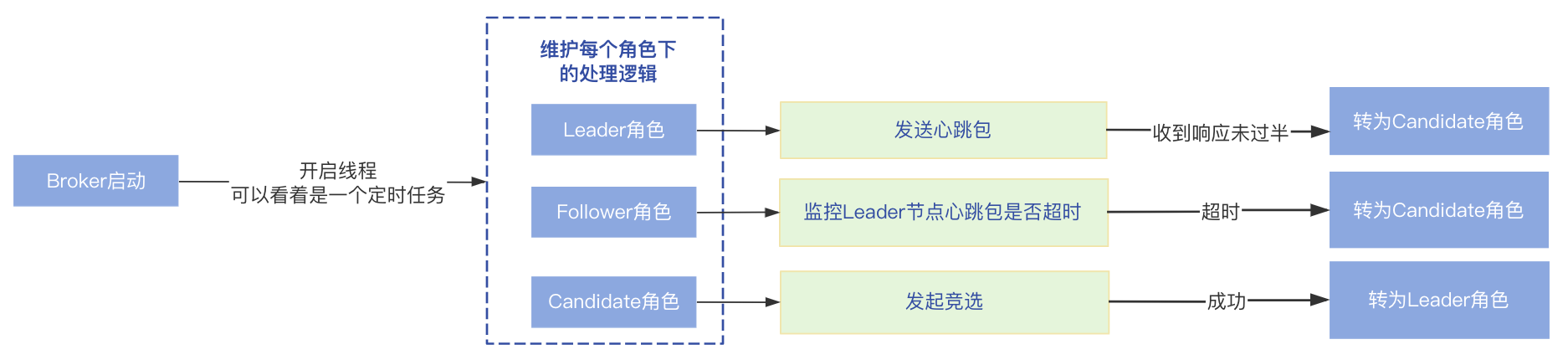
Broker启动后,会开启一个线程一直循环,所以可以看着是一个定时任务,不断的维护每个角色的处理逻辑,根据Raft协议可知节点有三种角色,所以对应三种处理逻辑:
- Leader角色:Leader角色需要定时向Follower节点发送心跳包保持通信,以便在Leader节点出现故障的时候,Follower节点可以判断,处理逻辑在maintainAsLeader方法中;
- Follower角色:监控收到Leader节点心跳包的时间,超过一定时间内未收到会认为Leader节点发生故障,需要转换为Candidate角色发起Leader选举,处理逻辑在maintainAsFollower方法中;
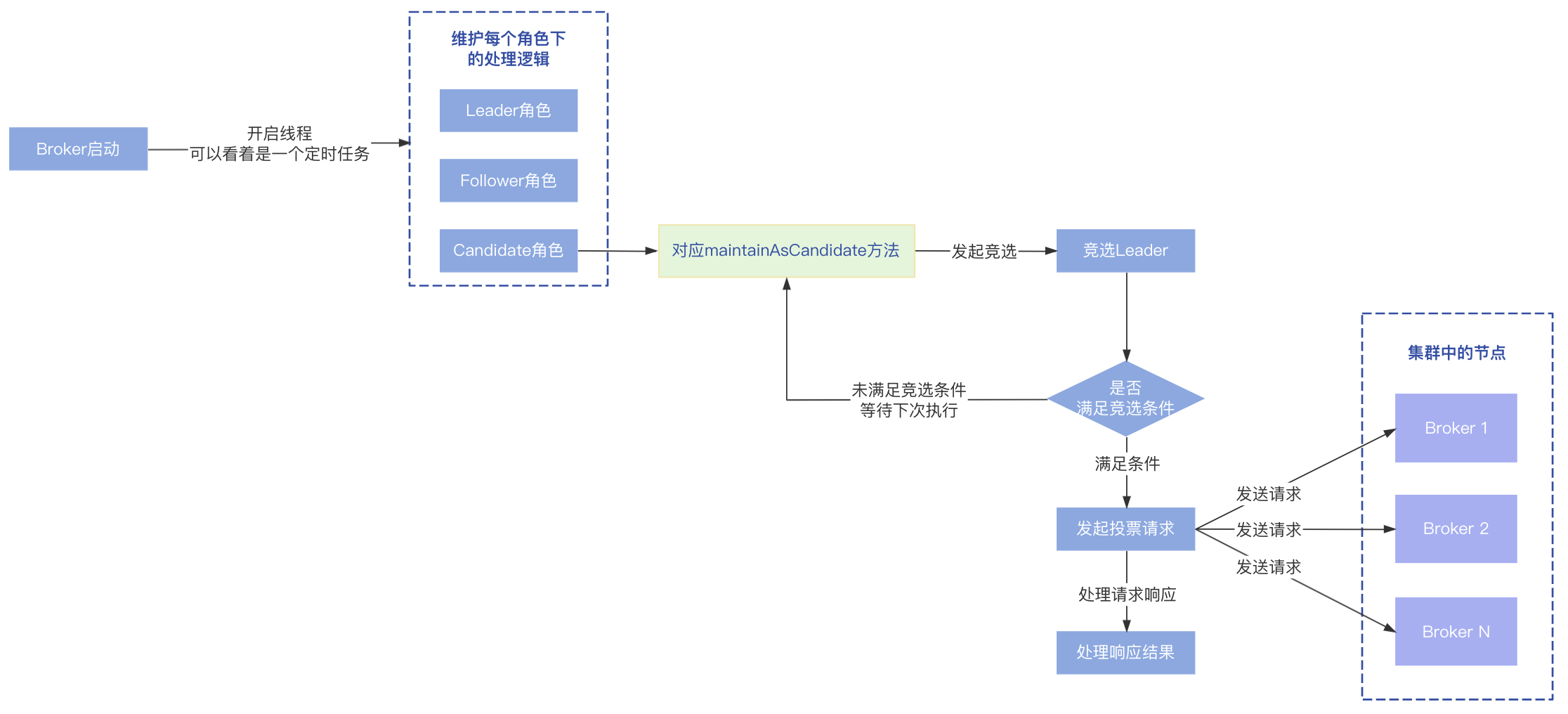
- Candidate角色:在Candidate角色会发起竞选,对应maintainAsCandidate方法;
初始状态下,每个节点的角色为Candidate,所以会进入到Candidate的处理逻辑中,在这里会触发一次选举。
Candidate发起竞选
- nextTimeToRequestVote:下次选举的时间,用于每次发起选举前,判断是否到达了选举时间;
- needIncreaseTermImmediately:默认为false,为true时表示需要增加投票轮次Term的值,并立刻发起新一轮选举;
- currTerm:当前的选举投票任期/轮次;
- LedgerEndIndex:可以看做当前节点记录最后一条成功写入消息的index;
- LedgerEndTerm:Leader节点的投票轮次,也就是最近一次Leader选举成功时的那个Term,会记录在每个节点的LedgerEndIndex中;
发起选举的具体过程如下:
- 首先判断是否满足选举的条件,处于以下两种条件之一表示条件满足,可以继续后面的步骤,否则直接返回,等待下一次处理:
(1)当前时间到达了设定的选举时间(nextTimeToRequestVote);
(2)needIncreaseTermImmediately的值被置为了true; - 校验当前角色是否是Candidate,如果不是直接返回;
- 判断是否需要增加Term的值,处于以下两种情况之一会增加Term的值(增加1),否则使用当前记录的Term值即可:
(1)上一次选举的结果状态是WAIT_TO_VOTE_NEXT状态;
(2)needIncreaseTermImmediately为true,表示需要增加Term立刻发起选举; - 向其他节点发起投票竞选请求;
- 处理投票请求响应结果,这个稍后再讲;
发起投票请求过程
当前节点会对自己维护的集群中所有节点进行遍历,向每一个节点发送投票竞选请求:
- 构建VoteRequest投票请求;
- 设置LedgerEndIndex、LedgerEndTerm等信息;
- 设置Leader节点的ID,发起选举的节点会推荐自己成为Leader,所以这里的Leader ID就是当前发起投票请求的节点的ID;
- 设置本次选举的Term信息;
- 集群中所有节点包括了当前节点自己,所以这里会判断,如果遍历到了自己就在本地处理投票请求,否则需要发送网络请求到其他节点进行处理;
其他节点对投票请求的处理
集群中其他节点收到投票请求后,处理逻辑如下:
- 首先做一些校验,比如发起请求的节点是否在维护的集群节点集合中;
- 对比请求中的携带的LedgerEndTerm与当前节点记录的LedgerEndTerm:
- 小于:说明请求的LedgerEndTerm比较落后,拒绝投票,返回状态REJECT_EXPIRED_LEDGER_TERM;
- 相等,但是LedgerEndIndex小于当前节点维护的LedgerEndIndex:说明发起请求的节点日志比较落后,拒绝投票,返回REJECT_SMALL_LEDGER_END_INDEX;
- 对比请求中的Term与当前节点的Term大小:
- 小于:说明请求中的Term比较落后,拒绝投票返回状态为REJECT_EXPIRED_LEDGER_TERM;
- 相等:如果当前节点还未投票或者刚好投票给发起请求的节点,进入下一步;如果已经投票给某个Leader,拒绝投票返回REJECT_ALREADY_HAS_LEADER;除此之外其他情况返回REJECT_ALREADY_VOTED;
- 大于:说明当前节点的Term过小已经落后于最新的Term,当前节点会转为Candidate角色,将needIncreaseTermImmediately置为true,立刻发起选举,此时返回响应REJECT_TERM_NOT_READY表示当前节点还未准备好进行投票;
- 如果请求中的TERM小于当前节点的LedgerEndTerm,拒绝投票,返回REJECT_TERM_SMALL_THAN_LEDGER;
- 投票给发起请求的节点,返回ACCEPT接受投票状态;
发起者处理投票响应结果
- validNum:收到有效请求响应节点的个数,只要响应状态不是
UNKNOWN状态,就算有效请求,个数就增一; - acceptedNum:同意当前节点成为Leader的节点个数;
- alreadyHasLeader:表示已经投票给了其他节点;
- knownMaxTermInGroup:当前节点记录集群中已知最大的那个Term;
- biggerLedgerNum:比当前节点的LedgerEndIndex大的节点数量;
- notReadyTermNum:未准备好进行投票的节点的数量;
回到发起选举的逻辑中,继续看处理投票结果的部分,向集群中每个节点发起投票请求之后,会等待每个请求返回响应,根据响应状态先做如下处理:
- 响应状态是ACCEPT:表示同意投票给当前节点,接受投票的节点数量acceptedNum加1;
- 响应状态是REJECT_ALREADY_VOTED或者REJECT_TAKING_LEADERSHIP:表示拒绝投票给当前节点;
- 响应状态是REJECT_ALREADY_HAS_LEADER:表示已经投票给了其他节点,alreadyHasLeader设置为true;
- 响应状态是REJECT_EXPIRED_VOTE_TERM:表示返回响应的节点的Term比当前节点的大,判断返回的那个Term是否大于当前节点记录的最大Term的值,如果是对knownMaxTermInGroup进行更新,记录集群中已知最大的那个Term;
- 响应状态是REJECT_SMALL_LEDGER_END_INDEX:表示返回响应节点的LedgerEndIndex比当前节点的大,biggerLedgerNum加1;
- 响应状态是REJECT_TERM_NOT_READY:表示有节点还未准备好进行投票,notReadyTermNum加1;
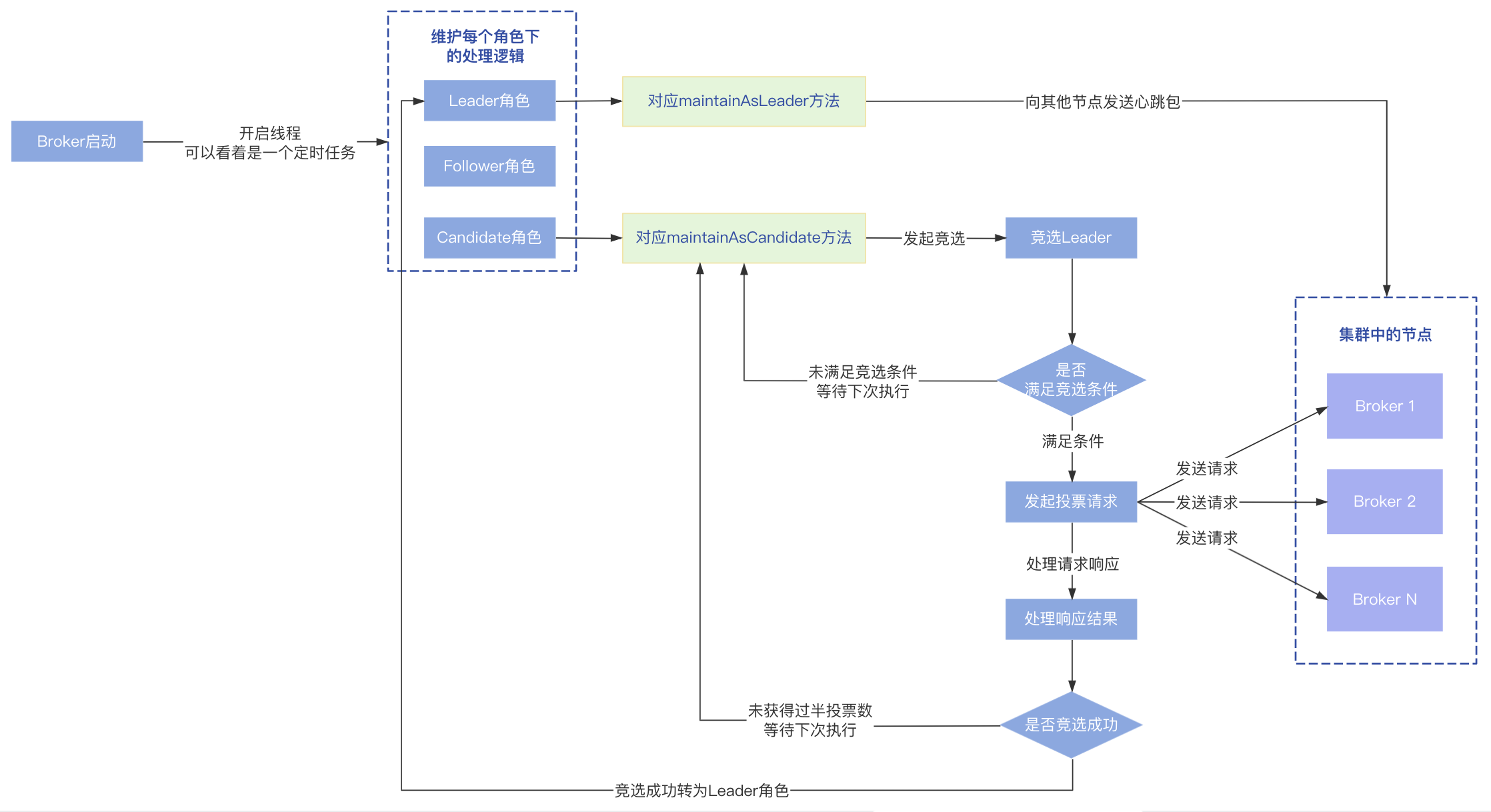
经过以上处理之后,会等待(2000 + 一个随机数)毫秒,然后再判断本次选举是否成功,总共有以下几种情况:
- 情况一:其他节点有比当前节点Term大的,说明本次选举的Term已经落后其他节点,需要使用较大的那个Term作为下次竞选的Term,此时会计算一个下次发起选举的时间,等待下一次发起选举;
判断方式是knownMaxTermInGroup与当前节点记录的Term做对比,上面处理响应状态的时候会判断,如果响应中的Term大,会更新knownMaxTermInGroup的值,所以这里可以通过knownMaxTermInGroup与当前Term的值进行判断。
在前面发起竞选的逻辑里面可以看到发起竞选前先会判断是否到达了竞选的时间,这个竞选时间就是这里计算的下次发起选举的时间。
- 情况二:有节点已经投票给了其他节点(alreadyHasLeader为true),说明有其他节点在竞争Leader,计算下次选举时间,等待下一次进行发起选举;
- 情况三:收到的有效投票数未过半(validNum的值未超过集群总节点数的一半),计算下次选举时间,等待下一次进行发起选举;
- 情况四:收到有效投票数(validNum)减去比当前节点ledgerEndIndex大的节点数(biggerLedgerNum)未过半,计算下次选举时间并加上一个maxVoteIntervalMs(1000ms),等待下一次进行发起选举;
这个条件主要是为了判断是否有较多的节点LedgerEndIndex比当前的大,因为走到这一个条件中,说明收到有效投票个数是过半的(如果未过半会先进入情况三),如果有比较多的节点LedgerEndIndex比当前的大就会导致相减后的数量未过半。
比如集群中有10个节点,收到有效请求响应的个数为7,validNum值为3,其中有3个节点的LedgerEndIndex比当前节点大,biggerLedgerNum值为3,7-3=4,未超过集群节点一半数量,如果biggerLedgerNum值为1,那么7-1=6,个数过半就不会走到这个条件中。
- 情况五:接受投票的节点个数(acceptedNum)过半也就是达到了Quorum,表示本轮选举竞选成功,接下来会将节点的角色转为Leader;
结合情况四,可以看出假如有少部分节点LedgerEndIndex比当前的大,当前节点也可以竞选成功;
- 情况六:如果接受投票的节点个数(acceptedNum)+ 未准备好的节点数(notReadyTermNum)过半,表示有部分节点Term落后,与当前选举的Term不一致,立刻进行下一次投票,对应状态为REVOTE_IMMEDIATELY;
- 情况七:非以上六中情况下进入这一个条件,计算下次选举时间,等待下一次进行发起选举;
可以看到在以上几种情况中,只有情况五收到的投票数过半,才能竞选成功,其他情况下需要等到当前节点到达下一次发起选举的时间,重新发起竞选。
成为Leader
节点收到集群中大多数投票后,会将自己转为Leader角色。
上面说过,在Broker启动的时候,会开启一个线程不断维护每个角色的处理逻辑,对于Leader角色,需要向Follower点发送心跳包保持通信,所以成为Leader之后,下次执行就就会进入到Leader角色的处理逻辑,会判断上次发送心跳的时间是否大于心跳发送间隔,如果超过了就会向其他节点发送心跳包。
发送心跳包
Broker会向除自己以外的其他节点发送心跳请求:
- 构建HeartBeatRequest请求;
- 请求中设置本次选举的相关信息,包括组信息、当前节点的ID、目标节点的ID、LeaderID、当前的Term;
- 发送心跳请求;
- 处理心跳请求返回的响应数据(稍后再讲);
其他节点对心跳请求处理
- lastLeaderHeartBeatTime:最近一次收到Leader心跳请求的时间,用于在Follower角色下判断心跳时间是否超时使用,如果长时间未收到心跳包,会认为Leader节点故障,转为Candidate角色进行竞选。
集群中其他节点收到心跳请求后,对心跳请求的处理逻辑如下:
判断发送心跳请求的节点是否在当前节点维护的集群中,如果不在直接返回,返回状态为UNKNOWN_MEMBER;
判断心跳请求中携带的Leader ID是否是当前节点,如果是返回UNEXPECTED_MEMBER状态;
对比请求中携带的Term与当前节点的记录的Term:
- 小于:表示请求中的Term已过期,返回EXPIRED_TERM;
- 相等:如果请求中的LeaderID与当前节点维护的LeaderID一致,表示之前已经同意节点成为Leader,此时更新收到心跳包的时间lastLeaderHeartBeatTime为当前时间,返回成功即可;
如果没有满足以上三种情况,会加锁,再次拿请求中的Term与当前节点的Term进行对比:
- 小于:说明请求中的Term已落后,返回EXPIRED_TERM;
- 相等:
(1)如果当前节点记录的LeaderId为空:表示当前节点还未接受过其他Leader的请求,所以可以接受这个心跳包,此时当前节点会转为Follower角色,然后返回成功;
(2)如果请求中的LeaderId与当前节点记录的Leader一致:表示之前已经同意节点成为Leader,更新收到心跳包的时间lastLeaderHeartBeatTime为当前时间,返回成功;
(3)其他情况:主要是为了容错处理,会返回INCONSISTENT_LEADER; - 大于:说明当前节点Term比较落后,将当前节点转为Candidate角色,然后将needIncreaseTermImmediately置为true,返回TERM_NOT_READY,表示未准备好;
心跳响应结果处理
- lastSendHeartBeatTime:上次成功发送心跳包的时间;
- succNum:接受心跳包的节点个数;
- notReadyNum:未准备好投票的节点个数,Term值比当前节点发起的小的时候会返回TERM_NOT_READY状态;
回到Leader节点,当心跳包返回响应之后,会对返回响应状态进行判断:
- SUCCESS:表示成功,记录心跳发送成功的节点个数,succNum加1;
- EXPIRED_TERM:表示当前节点的Term已过期落后于其他节点,将较大的那个Term记录在maxTerm中;
- INCONSISTENT_LEADER:将inconsistLeader置为true;
- TERM_NOT_READY:表示有节点还未准备好,也就是Term较小,此时记录未准备节点的数量,notReadyNum加1;
接下来根据上面的处理结果进行判断:
- 如果集群中过半节点对心跳包返回了成功的状态,更新心跳包发送成功的时间(lastSendHeartBeatTime);
- 如果未过半进行以下判断:
(1)如果成功的个数(succNum)+ 未准备好的个数(notReadyNum)过半,lastSendHeartBeatTime值置为-1,下次进入maintainAsLeader方法会认为已经超过心跳发送时间间隔,所以会立刻发送心跳包;
(2)如果maxTerm值大于当前节点的Term,表示当前节点Term已过期,将当前节点转为Candidate,并使用maxTerm做为下次选举的Term,等待下次重新发起选举;
(3)inconsistLeader为true,将当前节点转为Candidate,等待下次选举;
(4)如果上次成功发送心跳的时间大于maxHeartBeatLeak(最大心跳时间) * heartBeatTimeIntervalMs(心跳发送间隔),将当前节点转为Candidate,等待下次选举;
所以Leader在向其他节点发送了心跳包之后,如果收到过半的响应,只需更新跳包发送成功的时间,否则只有处于条件(1)的时候会再次发送心跳包进行确认,其他情况当前Leader都会转为Candidate,重新发起选举。
Follower角色
当节点收到心跳包并同意发起选举的节点成为Leader时,会转为Follower角色,在下次维护角色的处理逻辑时会进入到 Follower角色的处理方法中。
它首先会判断上次收到Leader心跳包的时间是否超过了两倍的发送心跳间隔,如果超过,判断当前节点是否是Follower并且上次收到心跳包的时间大于最大心跳时间 * 每次发送心跳的时间间隔,如果成立,就会转为Candidate等待发起竞选,也就是说如果Follower节点长时间未收到Leader节点的心跳请求,会认为Leader出现了故障,会转为Candidate角色,在Candidate角色下会重新发竞选进行Leader选举。
DLedger选主源码可参考:【RocketMQ】【源码】DLedger选主源码分析
【RocketMQ】DLedger模式下的选主流程分析的更多相关文章
- DexHunter在ART虚拟机模式下的脱壳原理分析
本文博客地址: http://blog.csdn.net/qq1084283172/article/details/78494620 DexHunter脱壳工具在Dalvik虚拟机模式下的脱壳原理分析 ...
- 【Elasticsearch】ES选主流程分析
Raft协议 Raft是分布式系统中的一种共识算法,用于在集群中选举Leader管理集群.Raft协议中有以下角色: Leader(领导者):集群中的领导者,负责管理集群. Candidate(候选者 ...
- DexHunter在Dalvik虚拟机模式下的脱壳原理分析
本文博客地址:http://blog.csdn.net/qq1084283172/article/details/78494671 在前面的博客<DexHunter的原理分析和使用说明(一)&g ...
- PHP CLI模式下的多进程应用分析
PHP在非常多时候不适合做常驻的SHELL进程, 他没有专门的gc例程, 也没有有效的内存管理途径. 所以假设用PHP做常驻SHELL, 你会常常被内存耗尽导致abort而unhappy 并且, 假设 ...
- 【odoo】【知识杂谈】单一实例多库模式下定时任务的问题分析
欢迎转载,但需标注出处,谢谢! 背景: 有客户反应有个别模块下的定时任务没有正常执行,是否是新装的模块哪些有问题?排查后发现,客户是在一台服务器上跑着一个odoo容器,对应多个数据库.个别库的定时任务 ...
- Android平台dalvik模式下java Hook框架ddi的分析(1)
本文博客地址:http://blog.csdn.net/qq1084283172/article/details/75710411 一.前 言 在前面的博客中已经学习了作者crmulliner编写的, ...
- 源码分析 RocketMQ DLedger(多副本) 之日志复制(传播)
目录 1.DLedgerEntryPusher 1.1 核心类图 1.2 构造方法 1.3 startup 2.EntryDispatcher 详解 2.1 核心类图 2.2 Push 请求类型 2. ...
- Docker 部署 RocketMQ Dledger 集群模式( 版本v4.7.0)
文章转载自:http://www.mydlq.club/article/97/ 系统环境: 系统版本:CentOS 7.8 RocketMQ 版本:4.7.0 Docker 版本:19.03.13 一 ...
- 源码分析 RocketMQ DLedger 多副本存储实现
目录 1.DLedger 存储相关类图 1.1 DLedgerStore 1.2 DLedgerMemoryStore 1.3 DLedgerMmapFileStore 2.DLedger 存储 对标 ...
- 在 linux x86-64 模式下分析内存映射流程
前言 在上一篇中我们分析了 linux 在 x86-32 模式下的虚拟内存映射流程,本章主要继续分析 linux 在 x86-64 模式下的虚拟内存映射流程. 讨论的平台是 x86-64, 也可以称为 ...
随机推荐
- 使用CNI网络插件(calico)实现docker容器跨主机互联
目录 一.系统环境 二.前言 三.CNI网络插件简介 四.常见的几种CNI网络插件对比 五.Calico网络之间是如何通信的 六.配置calico让物理机A上的docker容器c1可以访问物理机B上的 ...
- Kotlin协程-那些理不清乱不明的关系
Kotlin的协程自推出以来,受到了越来越多Android开发者的追捧.另一方面由于它庞大的API,也将相当一部分开发者拒之门外.本篇试图从协程的几个重要概念入手,在复杂API中还原出它本来的面目,以 ...
- 园子的商业化努力:欢迎参加DataFun联合行行AI举办的数据智能创新与实践人工智能大会
大家好,今年是园子商业化生死攸关的一年,正在艰难而努力地向前推进,今天在首页发布一篇大会推广博文,望谅解. DataFun联合行行AI举办第四届"数据智能创新与实践人工智能大会", ...
- 打包 IPA processing failed 失败
查看报错日志:有些SDK含有x86_64架构,移除即可 1. cd 该库SDK路径下 2.执行 lipo -remove x86_64 BaiduTraceSDK -o BaiduTraceSDK 解 ...
- 跟运维学 Linux - 01
跟运维学 Linux - 01 运维的诞生 运维工程师有很多叫法:系统运维.Linux 工程师.系统管理员... 网管可以说是运维工程师最早的雏形.在个人电脑未普及时,大家去网吧玩游戏. 玩家:&qu ...
- Python数据分析易错知识点归纳(四):Matplotlib
四.matplotlib 基本特性 import matplotlib.pyplot as plt import numpy as np x = np.linspace(-3, 3, 50) y1 = ...
- 【MAUI Blazor踩坑日记】6.mac标题栏颜色修改
MAUI中mac的标题栏颜色默认是灰白色的,有一点丑 如果我们想要自定义颜色,并且在运行时也能更改颜色,该怎么办呢 万幸从一个GitHub库中借鉴到了办法 https://github.com/Ben ...
- Cilium系列-5-Cilium替换KubeProxy
系列文章 Cilium 系列文章 前言 将 Kubernetes 的 CNI 从其他组件切换为 Cilium, 已经可以有效地提升网络的性能. 但是通过对 Cilium 不同模式的切换/功能的启用, ...
- Linux shell:根据盘符定位硬盘在服务器上的位置
disk-light.sh #!/bin/bash t_dev=$1 [ -b "$t_dev" ] || { echo "-b failed: $t_dev" ...
- javascript中的垃圾回收机制的一些知识记录
调用栈中的数据是如何回收的 原始类型的数据会分配到栈中 引用类型的数据会被分配到堆中 在执行代码的过程中,如果遇到了一个函数,js引擎会创建该函数的执行上下文,并将该函数的上下文压入调用栈中,与此同时 ...