MapReduce实现TopN的效果
1、背景
最近在学习Hadoop的MapReduce,此处记录一下如何实现 TopN 的效果,以及在MapReduce中如何实现 自定义分组。
2、需求
我们有一份数据,数据中存在如下3个字段,订单编号,订单项和订单项价格。 输出的数据,需求如下:
订单编号与订单编号之间需要正序输出。- 输出
每个订单价格最高的2个订单项。
3、分析
订单编号与订单编号之间需要正序输出,那么订单编号必须要作为Key,因为只有Key才有排序操作。- 输出
每个订单价格最高的2个订单项: 这个输出是在reduce阶段,并且是每个订单,因此需要根据订单编号进行分组操作(前后2个key比较,相同则为一组),而分组也只有Key才有,因此就需要JavaBean(订单编号、订单项、订单项价格)来作为组合Key。 订单编号与订单编号之间需要正序输出 && 输出每个订单价格最高的2个订单项: 可以看出在Key中的排序规则为:根据订单编号升序,然后根据订单项价格倒序排序, 并且是根据订单编号来分组。- 我们知道
默认MapReduce中默认的分区规则是,根据key的hascode来进行分区,而 分区 下是有多个 分组,每个分组调用一次reduce方法。 而我们上方的思路是,根据订单编号来进行分组,当我们Key是JavaBean组合Key时,相同的订单编号所在的JavaBean会被分在一个分组吗,这个不一定,因为JavaBean的hashcode不一定一致,因此就需要我们自定义分区(继承Partitioner类)。此处我们job.setNumReduceTasks设置为1个,因此不考虑这个分区的问题。 - 一个分区下有多个分组,每个分组调用一次
reduce方法。
4、准备数据
4.1 准备数据
20230713000010 item-101 10
20230713000010 item-102 30
20230713000015 item-151 10
20230713000015 item-152 20
20230713000010 item-103 20
20230713000015 item-153 30
20230713000012 item-121 50
20230713000012 item-122 10
20230713000012 item-123 30
4.2 每行数据格式
订单编号 订单项 订单项价格
20230713000012 item-123 30
每行数据的分隔符为空格
4.3 期望输出结果
20230713000010 item-102 30
20230713000010 item-103 20
20230713000012 item-121 50
20230713000012 item-123 30
20230713000015 item-153 30
20230713000015 item-152 20
5、编码实现
5.1 引入jar包
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.3.4</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.22</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-jar-plugin</artifactId>
<version>3.2.2</version>
<configuration>
<archive>
<manifest>
<addClasspath>true</addClasspath>
<classpathPrefix>lib/</classpathPrefix>
<mainClass>com.huan.hadoop.mr.TopNDriver</mainClass>
</manifest>
</archive>
</configuration>
</plugin>
</plugins>
</build>
5.2 编写实体类
package com.huan.hadoop.mr;
import lombok.Getter;
import lombok.Setter;
import org.apache.hadoop.io.WritableComparable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
/**
* 订单数据
*
* @author huan.fu
* @date 2023/7/13 - 14:20
*/
@Getter
@Setter
public class OrderVo implements WritableComparable<OrderVo> {
/**
* 订单编号
*/
private long orderId;
/**
* 订单项
*/
private String itemId;
/**
* 订单项价格
*/
private long price;
@Override
public int compareTo(OrderVo o) {
// 排序: 根据 订单编号 升序, 如果订单编号相同,则根据 订单项价格 倒序
int result = Long.compare(this.orderId, o.orderId);
if (result == 0) {
// 等于0说明 订单编号 相同,则需要根据 订单项价格 倒序
result = -Long.compare(this.price, o.price);
}
return result;
}
@Override
public void write(DataOutput out) throws IOException {
// 序列化
out.writeLong(orderId);
out.writeUTF(itemId);
out.writeLong(price);
}
@Override
public void readFields(DataInput in) throws IOException {
// 反序列化
this.orderId = in.readLong();
this.itemId = in.readUTF();
this.price = in.readLong();
}
@Override
public String toString() {
return this.getOrderId() + "\t" + this.getItemId() + "\t" + this.getPrice();
}
}
- 此处需要实现
WritableComparable接口 - 需要编写
排序和序列化方法
5.3 编写分组方法
package com.huan.hadoop.mr;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator;
/**
* 分组: 订单编号相同说明是同一组,否则是不同的组
*
* @author huan.fu
* @date 2023/7/13 - 14:30
*/
public class TopNGroupingComparator extends WritableComparator {
public TopNGroupingComparator() {
// 第二个参数为true: 表示可以通过反射创建实例
super(OrderVo.class, true);
}
@Override
public int compare(WritableComparable a, WritableComparable b) {
// 订单编号 相同说明是同一个对象,否则是不同的对象
return ((OrderVo) a).getOrderId() == ((OrderVo) b).getOrderId() ? 0 : 1;
}
}
- 实现
WritableComparator接口,自定义分组规则。 - 分组是发生在
reduce阶段,前后2个key比较,相同则为一组,一组调用一次reduce方法。
5.4 编写 map 方法
package com.huan.hadoop.mr;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* map 操作: 输出的key为OrderVo, 输出的value为: price
*
* @author huan.fu
* @date 2023/7/13 - 14:28
*/
public class TopNMapper extends Mapper<LongWritable, Text, OrderVo, LongWritable> {
private final OrderVo outKey = new OrderVo();
private final LongWritable outValue = new LongWritable();
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, OrderVo, LongWritable>.Context context) throws IOException, InterruptedException {
// 获取一行数据 20230713000010 item-101 10
String row = value.toString();
// 根据 \t 进行分割
String[] cells = row.split("\\s+");
// 获取订单编号
long orderId = Long.parseLong(cells[0]);
// 获取订单项
String itemId = cells[1];
// 获取订单项价格
long price = Long.parseLong(cells[2]);
// 设置值
outKey.setOrderId(orderId);
outKey.setItemId(itemId);
outKey.setPrice(price);
outValue.set(price);
// 写出
context.write(outKey, outValue);
}
}
- map 操作: 输出的key为OrderVo, 输出的value为: price
5.5 编写reduce方法
package com.huan.hadoop.mr;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* reduce操作: Key(OrderVo)相同的分为一组, 此处 OrderVo 作为key, 分组是根据 TopNGroupingComparator 来实现,
* 即 订单编号 相同的认为一组
*
* @author huan.fu
* @date 2023/7/13 - 14:29
*/
public class TopNReducer extends Reducer<OrderVo, LongWritable, OrderVo, NullWritable> {
@Override
protected void reduce(OrderVo key, Iterable<LongWritable> values, Reducer<OrderVo, LongWritable, OrderVo, NullWritable>.Context context) throws IOException, InterruptedException {
int topN = 0;
// 随着每次遍历, key的 orderId 是相同的(因为是根据这个分组的),但是里面的itemId和price是不同的
for (LongWritable price : values) {
topN++;
if (topN > 2) {
break;
}
// 注意: 此处的key每次输出都不一样
context.write(key, NullWritable.get());
}
}
}
- reduce操作: Key(OrderVo)相同的分为一组, 此处 OrderVo 作为key, 分组是根据 TopNGroupingComparator 来实现,即 订单编号 相同的认为一组.
- 随着每次遍历, key的 orderId 是相同的(因为是根据这个分组的),但是里面的itemId和price是不同的
5.6 编写driver类
package com.huan.hadoop.mr;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
/**
* @author huan.fu
* @date 2023/7/13 - 14:29
*/
public class TopNDriver extends Configured implements Tool {
public static void main(String[] args) throws Exception {
// 构建配置对象
Configuration configuration = new Configuration();
// 使用 ToolRunner 提交程序
int status = ToolRunner.run(configuration, new TopNDriver(), args);
// 退出程序
System.exit(status);
}
@Override
public int run(String[] args) throws Exception {
// 构建Job对象实例 参数(配置对象,Job对象名称)
Job job = Job.getInstance(getConf(), "topN");
// 设置mr程序运行的主类
job.setJarByClass(TopNDriver.class);
// 设置mr程序运行的 mapper类型和reduce类型
job.setMapperClass(TopNMapper.class);
job.setReducerClass(TopNReducer.class);
// 指定mapper阶段输出的kv数据类型
job.setMapOutputKeyClass(OrderVo.class);
job.setMapOutputValueClass(LongWritable.class);
// 指定reduce阶段输出的kv数据类型,业务mr程序输出的最终类型
job.setOutputKeyClass(OrderVo.class);
job.setOutputValueClass(NullWritable.class);
// 配置本例子中的输入数据路径和输出数据路径,默认输入输出组件为: TextInputFormat和TextOutputFormat
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 先删除输出目录(方便本地测试)
FileSystem.get(this.getConf()).delete(new Path(args[1]), true);
// 设置分组
job.setGroupingComparatorClass(TopNGroupingComparator.class);
return job.waitForCompletion(true) ? 0 : 1;
}
}
- 需要设置分组
job.setGroupingComparatorClass(TopNGroupingComparator.class);
5.7 运行结果
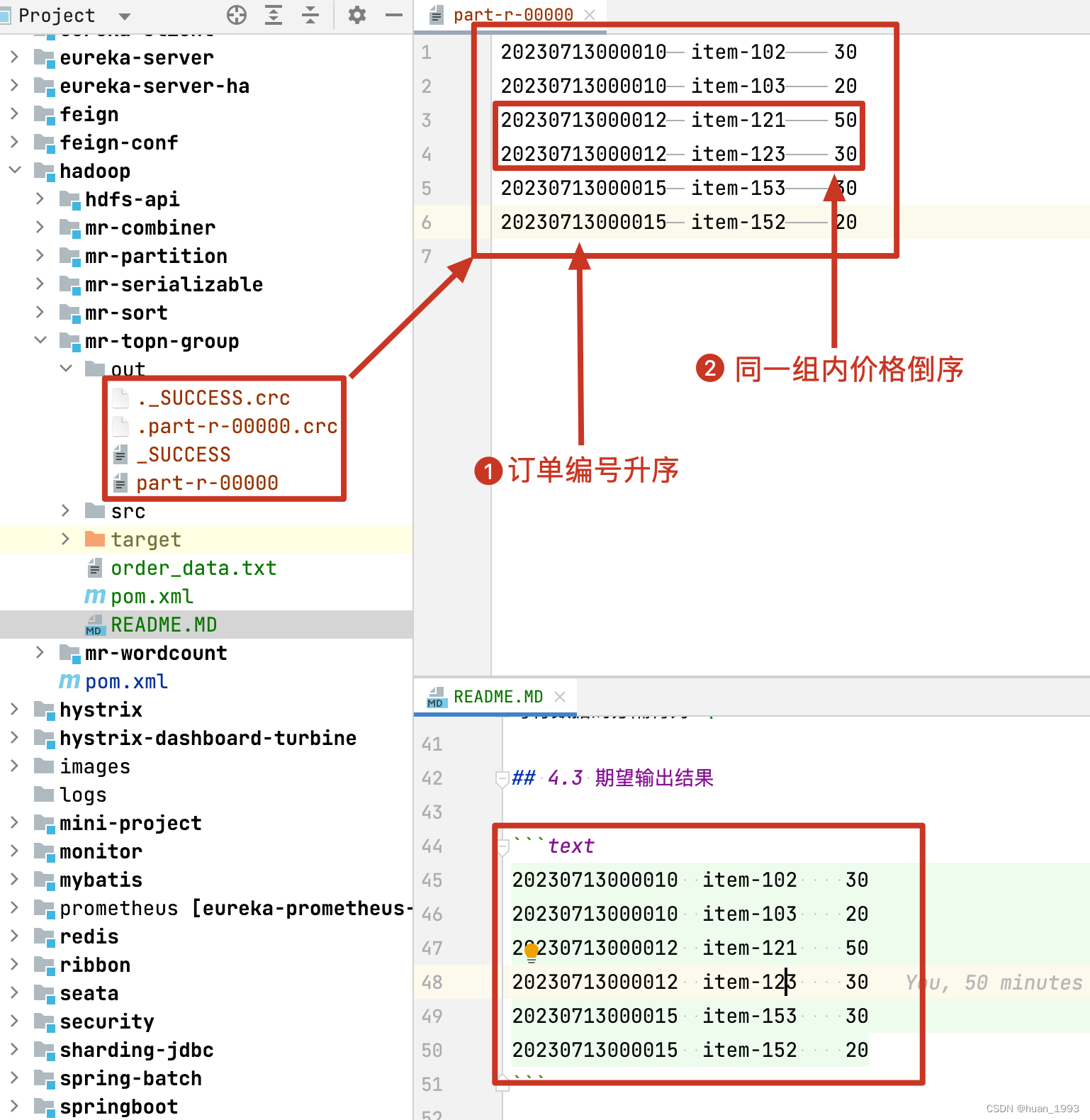
6、完整代码
https://gitee.com/huan1993/spring-cloud-parent/tree/master/hadoop/mr-topn-group
MapReduce实现TopN的效果的更多相关文章
- Hadoop基础-Map端链式编程之MapReduce统计TopN示例
Hadoop基础-Map端链式编程之MapReduce统计TopN示例 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.项目需求 对“temp.txt”中的数据进行分析,统计出各 ...
- Hadoop学习之路(二十)MapReduce求TopN
前言 在Hadoop中,排序是MapReduce的灵魂,MapTask和ReduceTask均会对数据按Key排序,这个操作是MR框架的默认行为,不管你的业务逻辑上是否需要这一操作. 技术点 MapR ...
- 大数据学习——mapreduce学习topN问题
求每一个订单中成交金额最大的那一笔 top1 数据 Order_0000001,Pdt_01,222.8 Order_0000001,Pdt_05,25.8 Order_0000002,Pdt_05 ...
- mapreduce的cleanUp和setUp的特殊用法(TopN问题)和常规用法
一:特殊用法 我们上来不讲普通用法,普通用法放到最后.我们来谈一谈特殊用法,了解这一用法,让你的mapreduce编程能力提高一个档次,毫不夸张!!!扯淡了,让我们进入正题: 我们知道reduce和m ...
- MapReduce: Simplified Data Processing on Large Clusters 翻译和理解
MapReduce: Simplified Data Processing on Large Clusters 概述 MapReduce 是一种编程模型,用于处理和生成大型数据集的相应实现.用户定义一 ...
- Hadoop Pig简介、安装、试用
相比Java的MapReduce api,Pig为大型数据集的处理提供了更高层次的抽象,与MapReduce相比,Pig提供了更丰富的数据结构,一般都是多值和嵌套的数据结构.Pig还提供了一套更强大的 ...
- 关于Mongodb的全面总结
MongoDB的内部构造<MongoDB The Definitive Guide> MongoDB的官方文档基本是how to do的介绍,而关于how it worked却少之又少,本 ...
- MapReduce TopN(自主复习)
1.MyTopN 主程序 package com.littlepage.topn; import org.apache.hadoop.conf.Configuration; import org.a ...
- 大数据mapreduce全局排序top-N之python实现
a.txt.b.txt文件如下: a.txt hadoop hadoop hadoop hadoop hadoop hadoop hadoop hadoop hadoop hadoop hadoop ...
- hadoop mapreduce求解有序TopN(高效模式)
1.在map阶段对数据先求解改分片的topN,到reduce阶段再合并求解一次,求解过程利用TreeMap的排序特性,不用自己写算法. 2.样板数据,类似如下 1 13682846555 192.16 ...
随机推荐
- C++ sizeof与strlen,并借此明晰内存对齐
前言 sizeof()与strlen()都是为了获取对象的长度.在正常编写C++的算法程序代码时,可能这两个都很少用到,因为各种stl容器的封装已经给了我们很大的便利,比如我们在想要获取自定义的vec ...
- day02-Redis命令
Redis命令 1.Redis数据结构介绍 Redis是一个key-value的数据库,key一般是String类型,value的类型多种多样,value常见的八种类型: Redis支持五种基本的数据 ...
- Prometheus监控之SNMP Exporter介绍和数据展现
由于技术能力有限,文章仅能进行简要分析和说明,如有不对的地方,请指正,谢谢. 1 SNMP协议介绍 SNMP协议全称是:Simple Network Management Protocol,译为简单网 ...
- Python 字典嵌套
字典嵌套 含义:将一系列字典存储在列表中,或将列表作为值存储在字典中 在列表中嵌套字典.在字典中嵌套列表.在字典中嵌套字典 字典列表 创建多个字典,将字典存放在列表中 使用range()自动生成多个字 ...
- 《C和指针》第一章
1 第一章 C标准库中几个常用的IO函数 int puts(void *str): 从str中提取字符直到遇到第一个'\0'为止,将这些字符串加上'\n'后发送给stdout. int main(vo ...
- 2022-04-26:给定一个数组componets,长度为A, componets[i] = j,代表i类型的任务需要耗时j 给定一个二维数组orders,长度为M, orders[i][0]代表i
2022-04-26:给定一个数组componets,长度为A, componets[i] = j,代表i类型的任务需要耗时j 给定一个二维数组orders,长度为M, orders[i][0]代表i ...
- 2022-11-13:以下go语言代码中,如何获取结构体列表以及结构体内的指针方法列表?以下代码应该返回{“S1“:[“M1“,“M2“],“S2“:[],“S3“:[“M1“,“M3“]},顺序不限
2022-11-13:以下go语言代码中,如何获取结构体列表以及结构体内的指针方法列表?以下代码应该返回{"S1":["M1","M2"], ...
- 2021-12-16:给定两个数a和b, 第1轮,把1选择给a或者b, 第2轮,把2选择给a或者b, ... 第i轮,把i选择给a或者b。 想让a和b的值一样大,请问至少需要多少轮? 来自字节跳动。
2021-12-16:给定两个数a和b, 第1轮,把1选择给a或者b, 第2轮,把2选择给a或者b, - 第i轮,把i选择给a或者b. 想让a和b的值一样大,请问至少需要多少轮? 来自字节跳动. 答案 ...
- C# 中的“智能枚举”:如何在枚举中增加行为
目录 枚举的基本用法回顾 枚举常见的设计模式运用 介绍 智能枚举 代码示例 业务应用 小结 枚举的基本用法回顾 以下是一个常见的 C# 枚举(enum)的示例: enum Weekday { Mond ...
- 2023-05-26:golang关于垃圾回收和析构函数的选择题,多数人会选错。
2023-05-26:golang关于垃圾回收和析构的选择题,代码如下: package main import ( "fmt" "runtime" " ...