HanLP — 感知机(Perceptron)
感知机(Perceptron)是一个二类分类的线性分类模型,属于监督式学习算法。最终目的: 将不同的样本分本
感知机饮食了多个权重参数,输入的特征向量先是和对应的权重相乘,再加得到的积相加,然后将加权后的特征值送入激活函数,最后得到输出
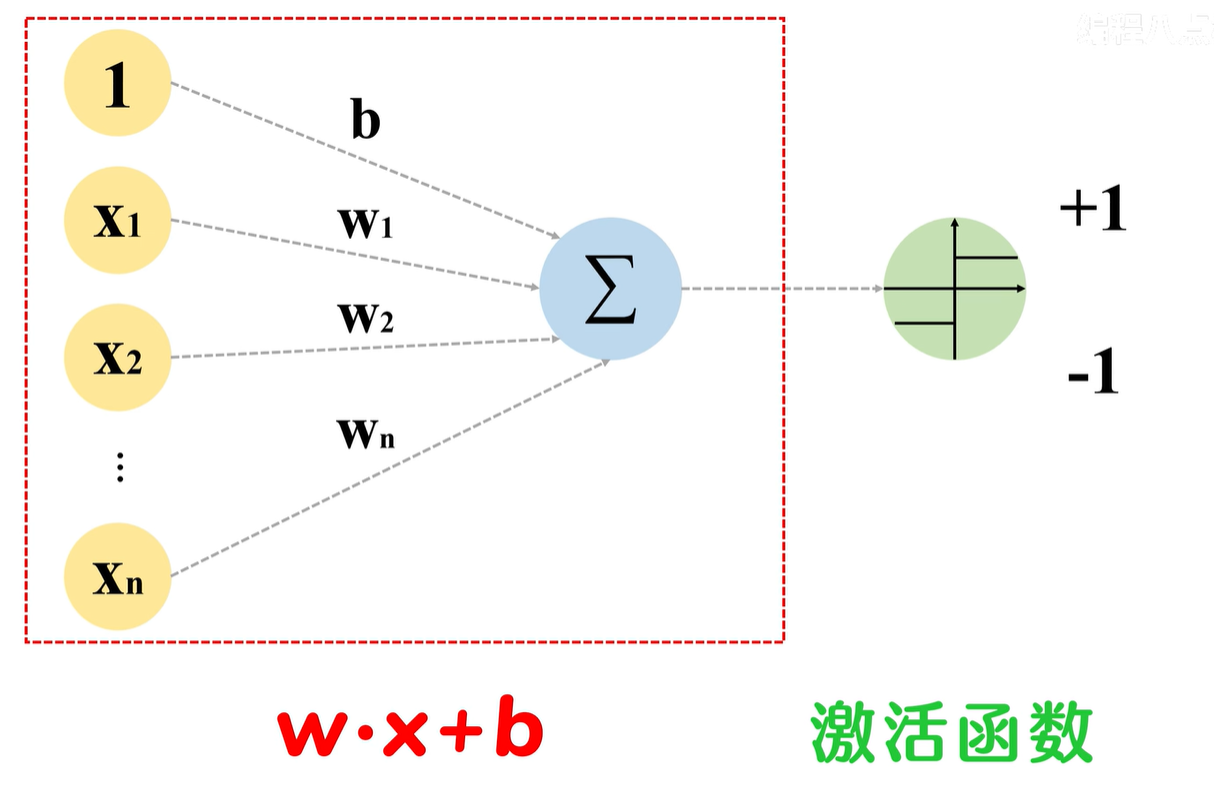
激活函数的前面部分,是线性方程 wx+b
线性方程输出的是连续的值,但对于分类来说,最终需要的类别信息是离散的值,这时候,激活函数就派上用场了,激活函数的存在,是将连续回归值,转变成1 -1 这样的离散值,从而实现类别划分
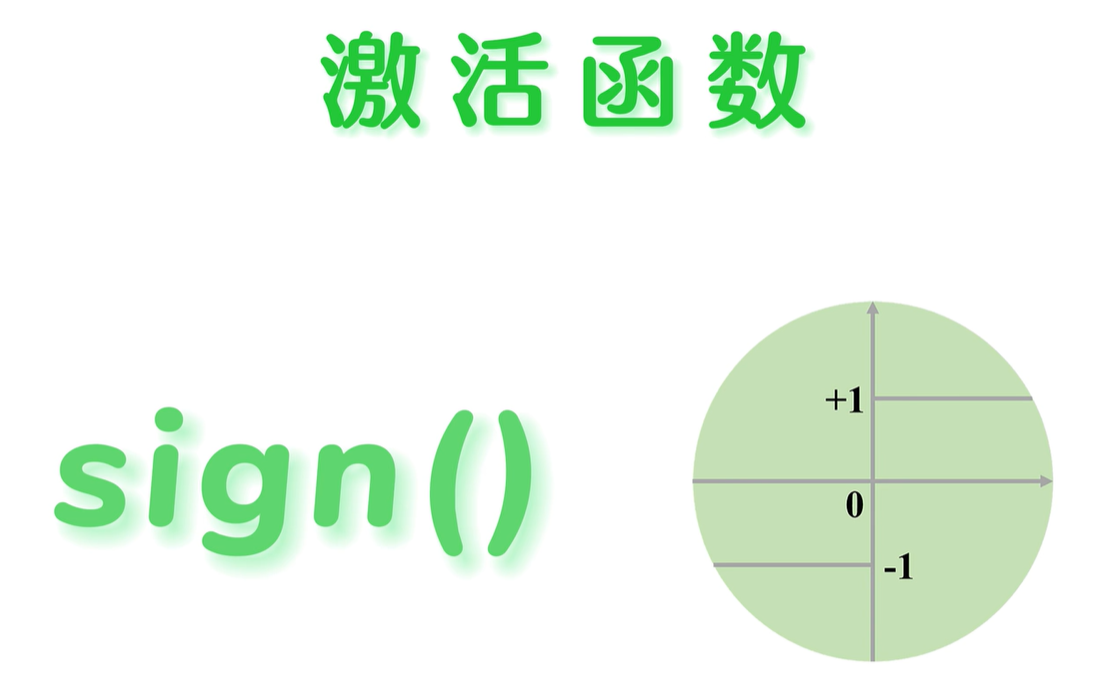
激活函数
激活函数有很多种,在深度学习中,有着非常重要的作用,在感知机中使用的激活函数是 sin(),
假如输入到模型中的是一个二维的特征向量(x1,x2),则整个过程可以表示为如下:
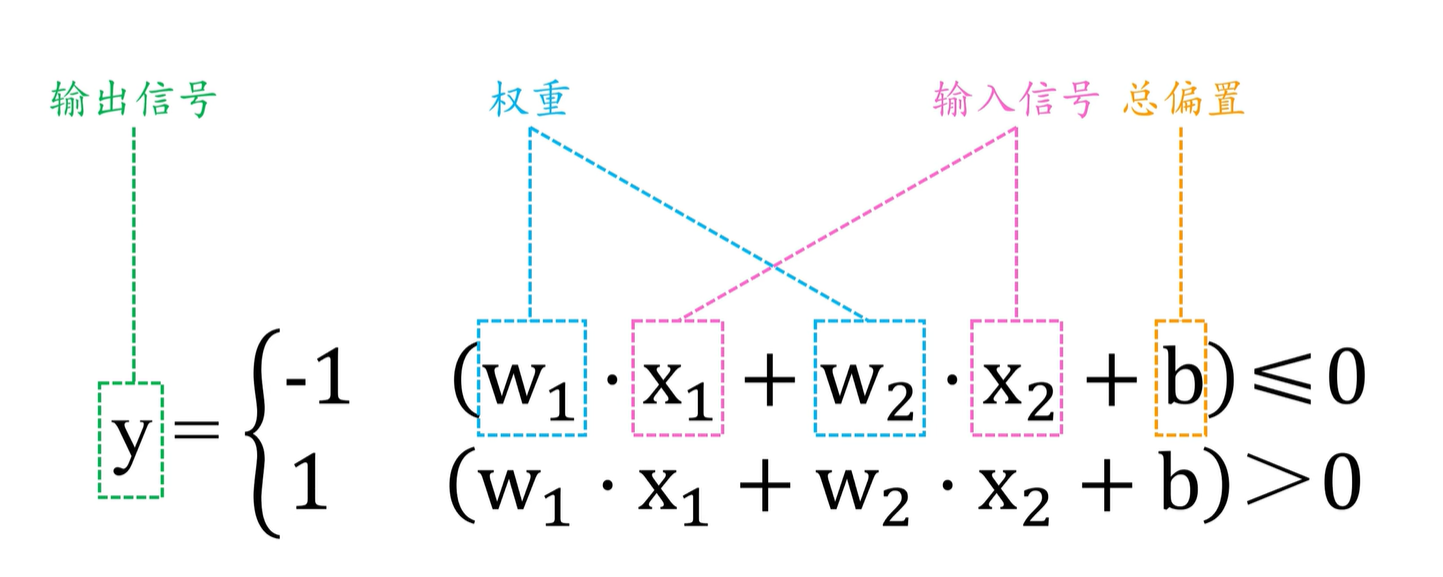
输入的特征向量(x1,x2)先分别和权重(w1,w2)相乘,再将两者相加,最后加上偏置 b ,最终得到的值,和阈值 0 做比较,如果值大于0 则输出1,否则则输出 -1
这样一来,就会划分到了线性方程 wx+b=0 两侧的样本,就分成了正、负两类,用感知机进行二分类,需要先找到能够将正、负样本完全区分开的决策函数 wx+b=0,如下图
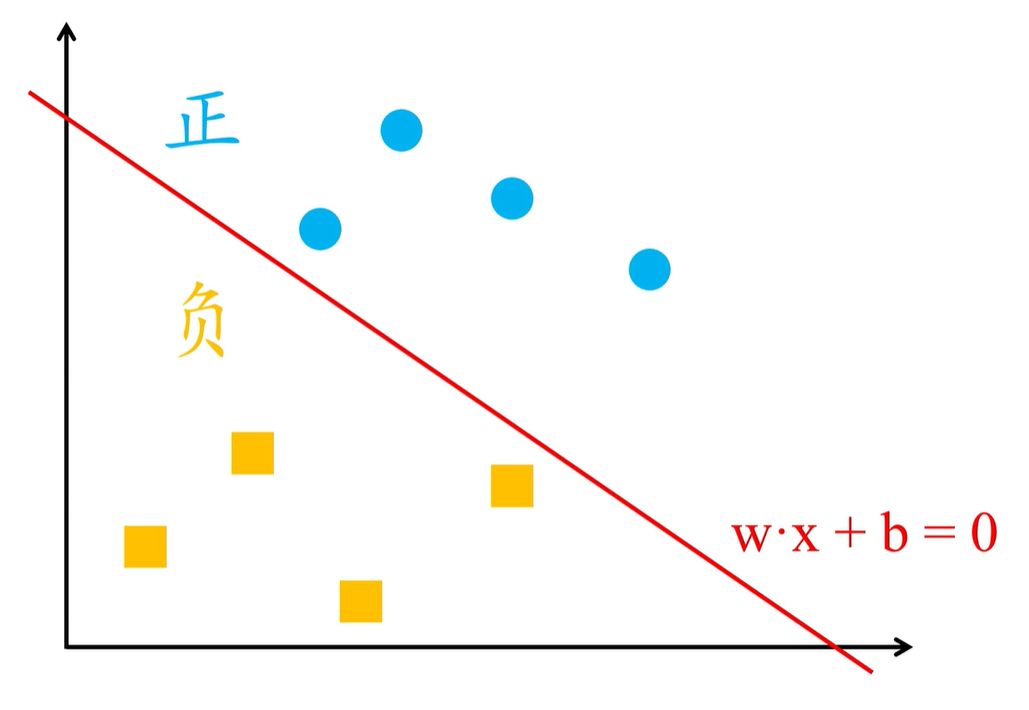
因此就需要确定一个学习策略,也就是定义一个损失函数,再通过训练样本,通过减小损失值,不断迭代模型参数,最终找到最优参数 w 和 b ,
损失函数的作用: 用来衡量模型的输出结果,和真实结果之间的偏差,然后根据偏差,修正模型,
回归任务
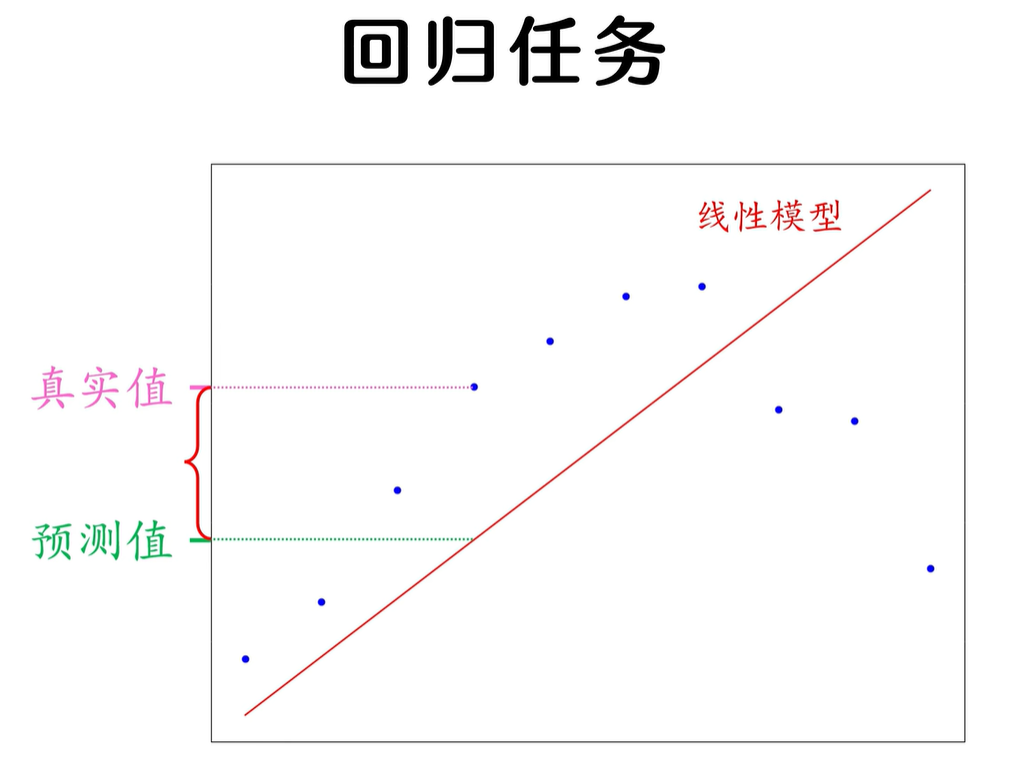
在回归任务中,标签和模型输出都是连续的数值,很容易就能衡量出二者之间的差异。
可对于感知机的分类问题来说,我们又该如何衡量差异呢?一个直观的想法,就是去统计误分类样本的个数作为损失值,误分类的样本个数越多,说明这个该样本空间下的表现越差,但是这样的函数是非连续的,对 w 和 b 不可导,所以我们无法使用这样的损失函数来更新 w 和 b.
为了得到连续可导的损失函数,感知机选择用误分类样本到决策函数的距离,来衡量偏差

这里是单个样本点到决策函数的距离公式
\(\frac {1}{||w||} |w*x_0+b|\)
其中 \(x_0\) 表示样本点的输入 \(||w||\)等于权重向量 \(w\) 的模长 \(||w|| = \sqrt{(w_1^2 + w_2^2 + ... + w_n^2)}\)
对于感知机分类问题来说,可以用 \(-y_0(w*x_0+b)\) 来代替 \(|w*x_0+b|\)
\(y_0\) 表示样本点 \(x_0\) 对应的标签值。
为什么可以这样代替呢?
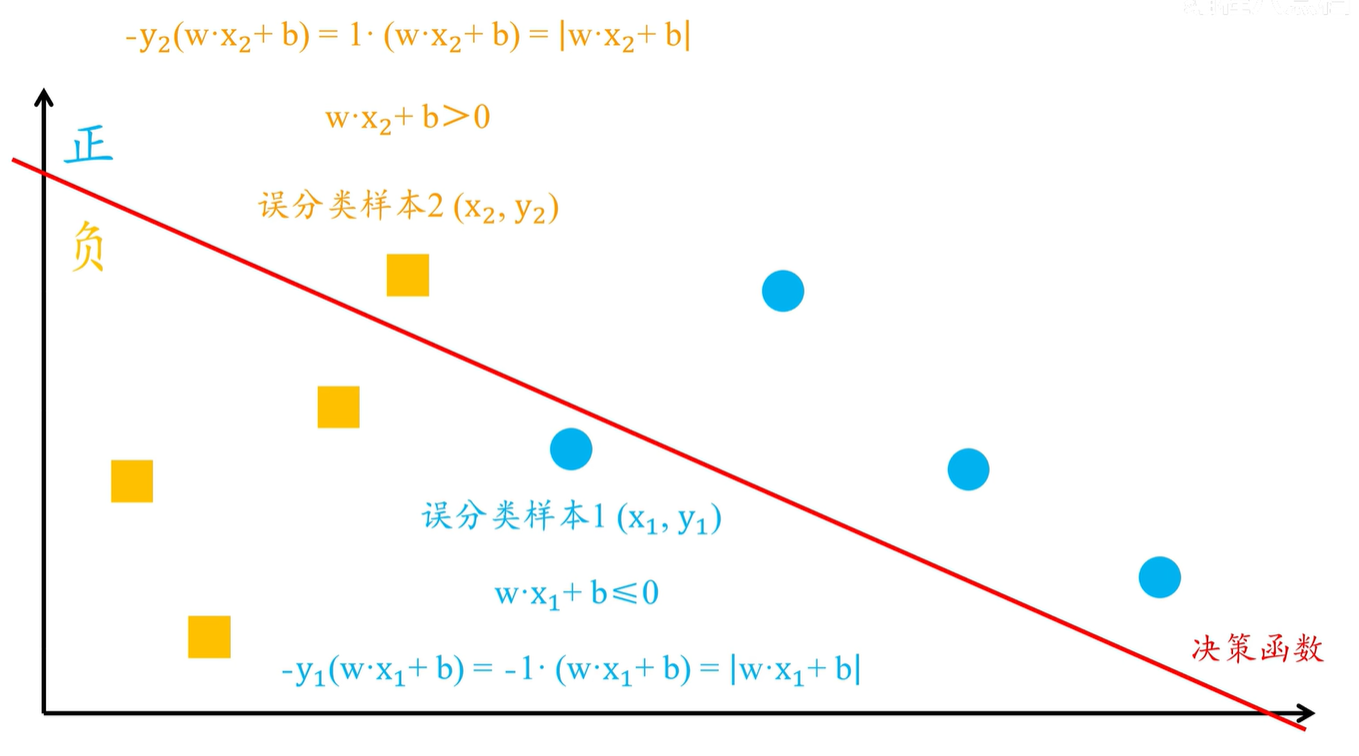
假设有两个误分类样本
样本1 \((x_1,y_1)\) 样本2 $(x_2,y_2) \(,
样本1 的真实类别为正样本,即:\)y_1 = 1$,但是在模型中,样本1 却被误分类为了负样本,也就是计算得到的 \(wx1+b \leq 0\),那么 \(-y_1(w*x_1+b)=-1(w*x_1+b)\) 最终的结果变成了正值,大小等于 \(|w*x_1+b|\)
样本2 的真实类别为负样本,\(y_2=-1\) 即在模型中被误分类为了正样本。也就是计算得到的 \(w*x_2+b > 0\),那么 \(-y_2(w*x_2+b)\) 就等于 \(1(w*x_2+b)\) ,结果仍为正值,大小等于 \(|w*x_2+b|\)
因此:所有误分类的样本到决策函数的距离和就可以表示为如下

感知机所关心的,是怎么能将两类样本正确地区分开,对样本点到决策函数距离的大小并不关心,如下图,红线和绿线都能将两类样本正确地区分开,所以对感知机来说,这两条线的分类效果是一样的
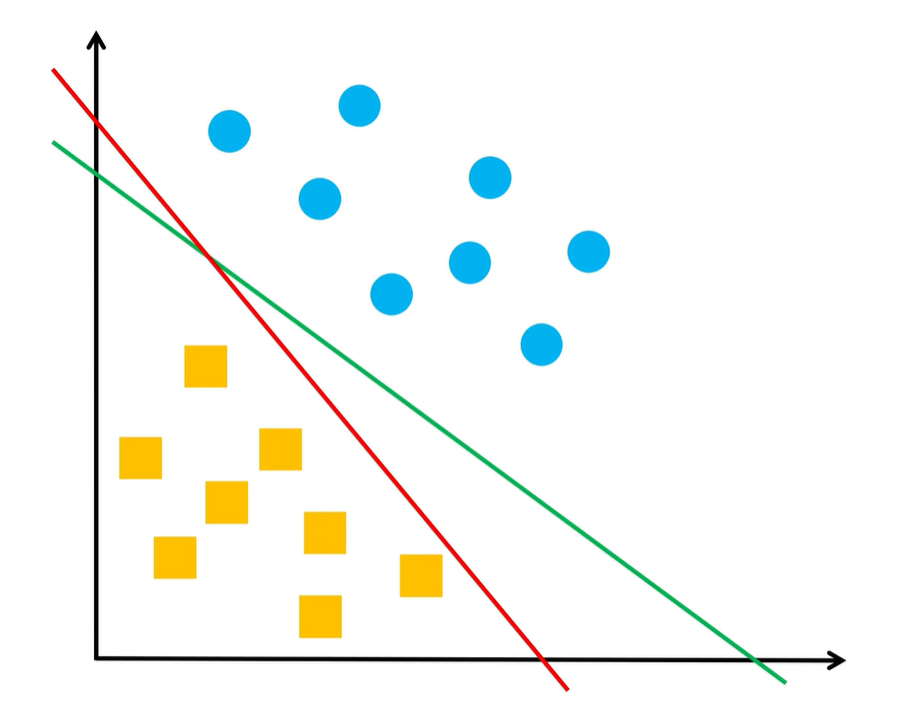
因此,可以把\(\frac {1}{||w||}\) 去掉
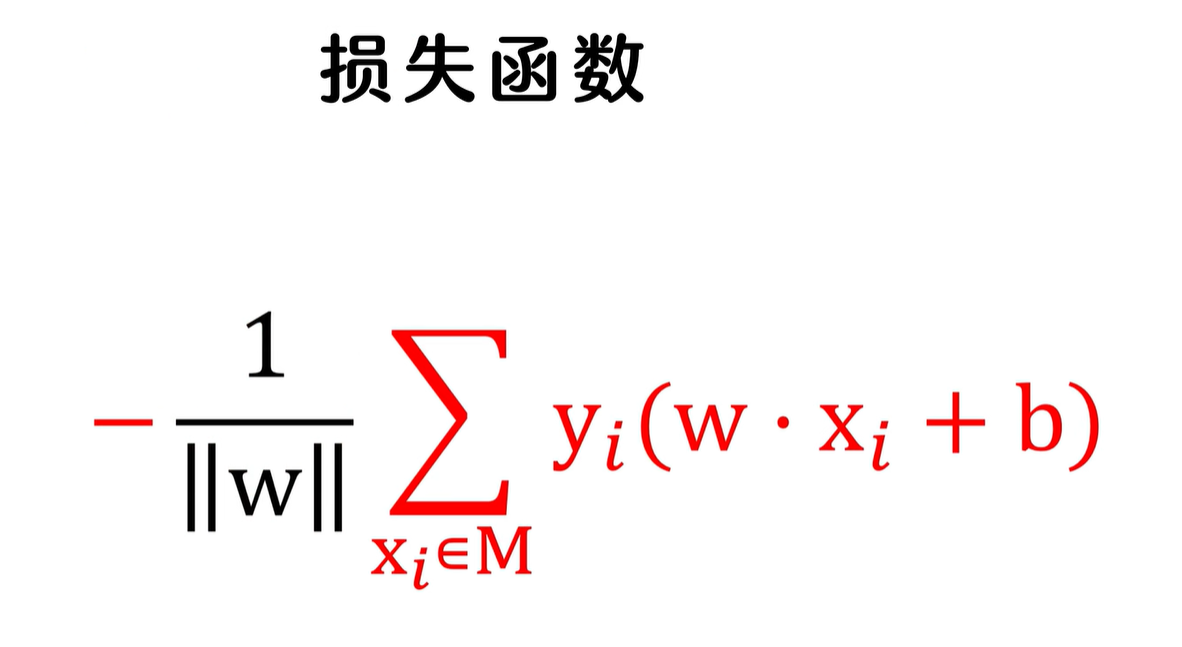
最终,感知机的函数就是 $$ L(w,b) = - \sum_{x_i{\in}M}y_i(w*x_i+b) $$

感知机适用于样本特征简单,且线性可分的二分类问题,因为运算简单,所以计算效率高。
不过在复杂的场景中,感知机往往不能胜任,所以我们在感知机的基础上,又诞生了多层感知机和神经网络
https://www.bilibili.com/video/BV19h4y1w7WL
HanLP — 感知机(Perceptron)的更多相关文章
- 2. 感知机(Perceptron)基本形式和对偶形式实现
1. 感知机原理(Perceptron) 2. 感知机(Perceptron)基本形式和对偶形式实现 3. 支持向量机(SVM)拉格朗日对偶性(KKT) 4. 支持向量机(SVM)原理 5. 支持向量 ...
- 感知机(perceptron)概念与实现
感知机(perceptron) 模型: 简答的说由输入空间(特征空间)到输出空间的如下函数: \[f(x)=sign(w\cdot x+b)\] 称为感知机,其中,\(w\)和\(b\)表示的是感知机 ...
- 20151227感知机(perceptron)
1 感知机 1.1 感知机定义 感知机是一个二分类的线性分类模型,其生成一个分离超平面将实例的特征向量,输出为+1,-1.导入基于误分类的损失函数,利用梯度下降法对损失函数极小化,从而求得此超平面,该 ...
- 感知机(perceptron)
- 神经网络 感知机 Perceptron python实现
import numpy as np import matplotlib.pyplot as plt import math def create_data(w1=3,w2=-7,b=4,seed=1 ...
- 分词工具Hanlp基于感知机的中文分词框架
结构化感知机标注框架是一套利用感知机做序列标注任务,并且应用到中文分词.词性标注与命名实体识别这三个问题的完整在线学习框架,该框架利用1个算法解决3个问题,时自治同意的系统,同时三个任务顺序渐进,构 ...
- 1. 感知机原理(Perceptron)
1. 感知机原理(Perceptron) 2. 感知机(Perceptron)基本形式和对偶形式实现 3. 支持向量机(SVM)拉格朗日对偶性(KKT) 4. 支持向量机(SVM)原理 5. 支持向量 ...
- 机器学习---三种线性算法的比较(线性回归,感知机,逻辑回归)(Machine Learning Linear Regression Perceptron Logistic Regression Comparison)
最小二乘线性回归,感知机,逻辑回归的比较: 最小二乘线性回归 Least Squares Linear Regression 感知机 Perceptron 二分类逻辑回归 Binary Logis ...
- pyhanlp:hanlp的python接口
HanLP的Python接口,支持自动下载与升级HanLP,兼容py2.py3. 安装 pip install pyhanlp 使用命令hanlp来验证安装,如因网络等原因自动安装失败,可参考手动配置 ...
- Hanlp自然语言处理工具之词法分析器
本章是接前两篇<分词工具Hanlp基于感知机的中文分词框架>和<基于结构化感知机的词性标注与命名实体识别框架>的.本系统将同时进行中文分词.词性标注与命名实体识别3个任务的子系 ...
随机推荐
- GaussDB(DWS)中的分布式死锁问题实践
本文分享自华为云社区<GaussDB(DWS)中的分布式死锁问题实践>,作者: 他强由他强 . 1.什么是分布式死锁 分布式死锁是相对于单机死锁而言,一个事务块中的语句,可能会分散在集群里 ...
- Llama2-Chinese项目:8-TRL资料整理
TRL(Transformer Reinforcement Learning)是一个使用强化学习来训练Transformer语言模型和Stable Diffusion模型的Python类库工具集, ...
- Python压缩JS文件,重点是 slimit
摘要:Python Web程序员必看系列,学习如何压缩 JS 代码. 本文分享自华为云社区<Python压缩JS文件,PythonWeb程序员必看系列,重点是 slimit>,作者: 梦想 ...
- iOS 应用上架的步骤和工具简介
编辑 APP开发助手是一款能够辅助iOS APP上架到App Store的工具,它解决了iOS APP上架流程繁琐且耗时的问题,帮助跨平台APP开发者顺利将应用上架到苹果应用商店.最重要的是,即使没有 ...
- 如何在上架App之前设置证书并上传应用
App上架教程 在上架App之前想要进行真机测试的同学,请查看<iOS- 最全的真机测试教程>,里面包含如何让多台电脑同时上架App和真机调试. P12文件的使用详解 注意: 同样可以 ...
- 不知如何优选达人?火山引擎 VeDI 零售行业解决方案一键解决!
技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,回复[1]进入官方交流群 "人-货匹配"这句营销老话,在直播电商兴起的这几年,似乎不再专指消费者与商品之间的关系. 过去 ...
- java -jar 启动 boot 程序 no main manifest attribute, in .\vipsoft-model-web-0.0.1-SNAPSHOT.jar
想让你的windows下 cmd 和我的一样帅吗.下载 cmder 绿色版,然后用我的配置文件,替换原来的文件启动就可以了 另外加cmder添加到右击菜单中,到安装目录中,执行下面命令 Cmder.e ...
- Buffer 缓冲区操作
1.缓冲区分片在 NIO 中,除了可以分配或者包装一个缓冲区对象外,还可以根据现有的缓冲区对象来创建一个子缓冲区,即在现有缓冲区上切出一片来作为一个新的缓冲区,但现有的缓冲区与创建的子缓冲区在底层数组 ...
- System.out.printf 格式化输出
System.out.printf @Test public void printTest() throws Exception { String str = "安倍晋三已无生命体征!!&q ...
- 阿里云CentOS数据盘挂载(磁盘扩容)
1. df -h Disk label type 值为dos表示MBR分区,值为gpt表示GPT分区. [root@iZuf66gcq71y5hlfv02w6aZ ~]# yum install -y ...