Hive数据导入Hbase
方案一:Hive关联HBase表方式
适用场景:数据量不大4T以下(走hbase的api导入数据)
一、hbase表不存在的情况
创建hive表hive_hbase_table映射hbase表hbase_table,会自动创建hbase表hbase_table,且会随着hive表删除而删除,这里需要指定hive的schema到hbase schema的映射关系:
1、建表
CREATE TABLE hive_hbase_table(key int, name String,age String)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES ("hbase.columns.mapping" = ":key,cf1:name,cf1:age")
TBLPROPERTIES ("hbase.table.name" = "hbase_table",
"hbase.mapred.output.outputtable" = "hbase_table");


2、创建一张原始的hive表,准备一些数据
create table hive_data (key int,name String,age string);
insert into hive_data values(1,"za","13");
insert into hive_data values(2,"ff","44");
3、把hive原表hive_data的数据,通过hive表hive_hbase_table导入到hbase的表hbase_table中
insert into table hive_hbase_table select * from hive_data;
4、查看hbase表hbase_table中是否有数据

二、hbase表存在的情况
创建hive的外表关联hbase表,注意hive schema到hbase schema的映射关系。删除外表不会删除对应hbase表
CREATE EXTERNAL TABLE hive_hbase_external_table(key String, name string,sex String,age String,department String)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES ("hbase.columns.mapping" = ":key,info:name,info:sex,info:age,info:department")
TBLPROPERTIES ("hbase.table.name" = "filtertest",
"hbase.mapred.output.outputtable" = "filtertest");
其他步骤与上面相同
方案二:HIve表生成hfile,通过bulkload导入到hbase
1、适用场景:数据量大(4T以上)
2、把hive数据转换为hfile
3、启动hive并添加相关的hbase的jar包
add jar /mnt/hive/lib/hive-hbase-handler-2.1.1.jar;
add jar /mnt/hive/lib/hbase-common-1.1.1.jar;
add jar /mnt/hive/lib/hbase-client-1.1.1.jar;
add jar /mnt/hive/lib/hbase-protocol-1.1.1.jar;
add jar /mnt/hive/lib/hbase-server-1.1.1.jar;
4、创建一个outputformat为HiveHFileOutputFormat的hive表
其中/tmp/hbase_table_hfile/cf_0是hfile保存到hdfs的路径,cf_0是hbase family的名字
create table hbase_hfile_table(key int, name string,age String)
stored as
INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.hbase.HiveHFileOutputFormat'
TBLPROPERTIES ('hfile.family.path' = '/tmp/hbase_table_hfile/cf_0');
5、原始数据表的数据通过hbase_hfile_table表保存为hfile
insert into table hbase_hfile_table select * from hive_data;
6、查看对应hdfs路径是否生成了hfile
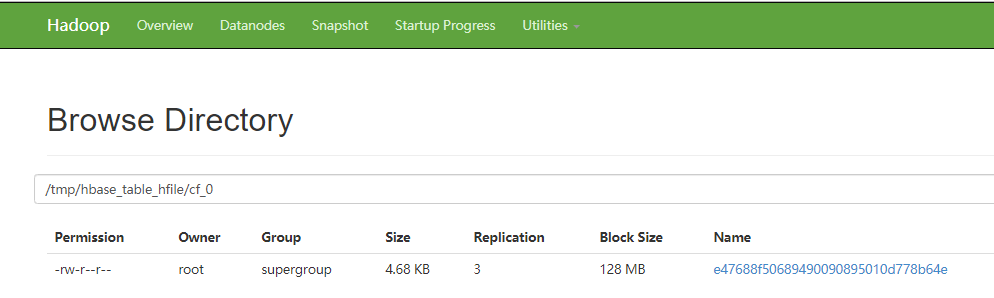
7、通过bulkload将数据导入到hbase表中
建表:使用hbase客户端创建具有上面对应family的hbase表
create 'hbase_hfile_load_table','cf_0'
下载hbase客户端,配置hbase-site.xml,并将hdfs-site.xml、core-site.xml拷贝到hbase/conf目录
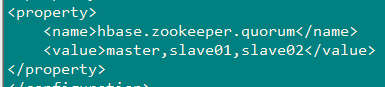
导入:
hbase org.apache.hadoop.hbase.mapreduce.LoadIncrementalHFiles \
hdfs://master:9000/tmp/hbase_table_hfile/ hbase_hfile_load_table
8、查看

Hive数据导入Hbase的更多相关文章
- Hive数据导入HBase引起数据膨胀引发的思考
最近朋友公司在做一些数据的迁移,主要是将一些Hive处理之后的热数据导入到HBase中,但是遇到了一个很奇怪的问题:同样的数据到了HBase中,所占空间竟增长了好几倍!详谈中,笔者建议朋友至少从几点原 ...
- sqoop将mysql数据导入hbase、hive的常见异常处理
原创不易,如需转载,请注明出处https://www.cnblogs.com/baixianlong/p/10700700.html,否则将追究法律责任!!! 一.需求: 1.将以下这张表(test_ ...
- Sqoop将mysql数据导入hbase的血与泪
Sqoop将mysql数据导入hbase的血与泪(整整搞了大半天) 版权声明:本文为yunshuxueyuan原创文章.如需转载请标明出处: https://my.oschina.net/yunsh ...
- 使用sqoop将MySQL数据库中的数据导入Hbase
使用sqoop将MySQL数据库中的数据导入Hbase 前提:安装好 sqoop.hbase. 下载jbdc驱动:mysql-connector-java-5.1.10.jar 将 mysql-con ...
- 利用sqoop将hive数据导入导出数据到mysql
一.导入导出数据库常用命令语句 1)列出mysql数据库中的所有数据库命令 # sqoop list-databases --connect jdbc:mysql://localhost:3306 ...
- Hive数据导入导出的几种方式
一,Hive数据导入的几种方式 首先列出讲述下面几种导入方式的数据和hive表. 导入: 本地文件导入到Hive表: Hive表导入到Hive表; HDFS文件导入到Hive表; 创建表的过程中从其他 ...
- MapReduce将HDFS文本数据导入HBase中
HBase本身提供了很多种数据导入的方式,通常有两种常用方式: 使用HBase提供的TableOutputFormat,原理是通过一个Mapreduce作业将数据导入HBase 另一种方式就是使用HB ...
- KUDU数据导入尝试一:TextFile数据导入Hive,Hive数据导入KUDU
背景 SQLSERVER数据库中单表数据几十亿,分区方案也已经无法查询出结果.故:采用导出功能,导出数据到Text文本(文本>40G)中. 因上原因,所以本次的实验样本为:[数据量:61w条,文 ...
- sqoop用法之mysql与hive数据导入导出
目录 一. Sqoop介绍 二. Mysql 数据导入到 Hive 三. Hive数据导入到Mysql 四. mysql数据增量导入hive 1. 基于递增列Append导入 1). 创建hive表 ...
随机推荐
- PyQt(Python+Qt)学习随笔:containers容器类部件QStackedWidget重要方法介绍
老猿Python博文目录 专栏:使用PyQt开发图形界面Python应用 老猿Python博客地址 StackedWidget堆叠窗口部件为一系列窗口部件的堆叠,对应类为QStackedWidget. ...
- 转:Python常见字符编码及其之间的转换
参考:Python常见字符编码 + Python常见字符编码间的转换 一.Python常见字符编码 字符编码的常用种类介绍 第一种:ASCII码 ASCII(American Standard Cod ...
- 第15.21节 PyQt(Python+Qt)入门学习:QListView的作用及属性详解
老猿Python博文目录 专栏:使用PyQt开发图形界面Python应用 老猿Python博客地址 一.概述 QListView是从QAbstractItemView 派生的类,实现了QAbstrac ...
- secret_key伪造session来进行越权
从swpuctf里面的一道ctf题目来讲解secret_key伪造session来进行越权. 以前没有遇到过这种题目,这次遇到了之后查了一些资料把它做了出来,记录一下知识点. 参考资料 http:// ...
- pytorch SubsetRandomSampler 用法和说明
官网:https://pytorch.org/docs/stable/data.html?highlight=subsetrandomsampler#torch.utils.data.SubsetRa ...
- 小程序map地图点击makert放大效果和点击放大地图
WXML文件和JS文件代码在下方 <view class='map'> <map id="map" longitude="{{location.lng} ...
- Codeforces Edu Round 67 A-C + E
A. Stickers and Toys 考虑尽量先买\(max(s, t)\)个里面单独的.那么如果\(s + t > n\)那么\(s + t - n\)的部分就该把\(min(s, t)\ ...
- js日期格式化-----总结
1. // 对Date的扩展,将 Date 转化为指定格式的String // 月(M).日(d).小时(h).分(m).秒(s).季度(q) 可以用 1-2 个占位符, // 年(y)可以用 1-4 ...
- Jmeter(2)基础知识
一.Jmeter测试计划 1.测试计划用来描述一个性能/接口测试的脚本和场景设计 独立运行每个线程组:用于控制测试计划中的多个线程组的执行顺序.不勾选时,默认各线程组并行.随机执行. 主线程结束后运行 ...
- sqli-labs less38-53(堆叠注入 order by之后相关注入)
堆叠注入 less-38 less-39 less-40 less-41 less-42 less-43 less-44 less-45 考察order by相关注入 less-46 less-47 ...