gradle中的增量构建
gradle中的增量构建
简介
在我们使用的各种工具中,为了提升工作效率,总会使用到各种各样的缓存技术,比如说docker中的layer就是缓存了之前构建的image。在gradle中这种以task组合起来的构建工具也不例外,在gradle中,这种技术叫做增量构建。
增量构建
gradle为了提升构建的效率,提出了增量构建的概念,为了实现增量构建,gradle将每一个task都分成了三部分,分别是input输入,任务本身和output输出。下图是一个典型的java编译的task。
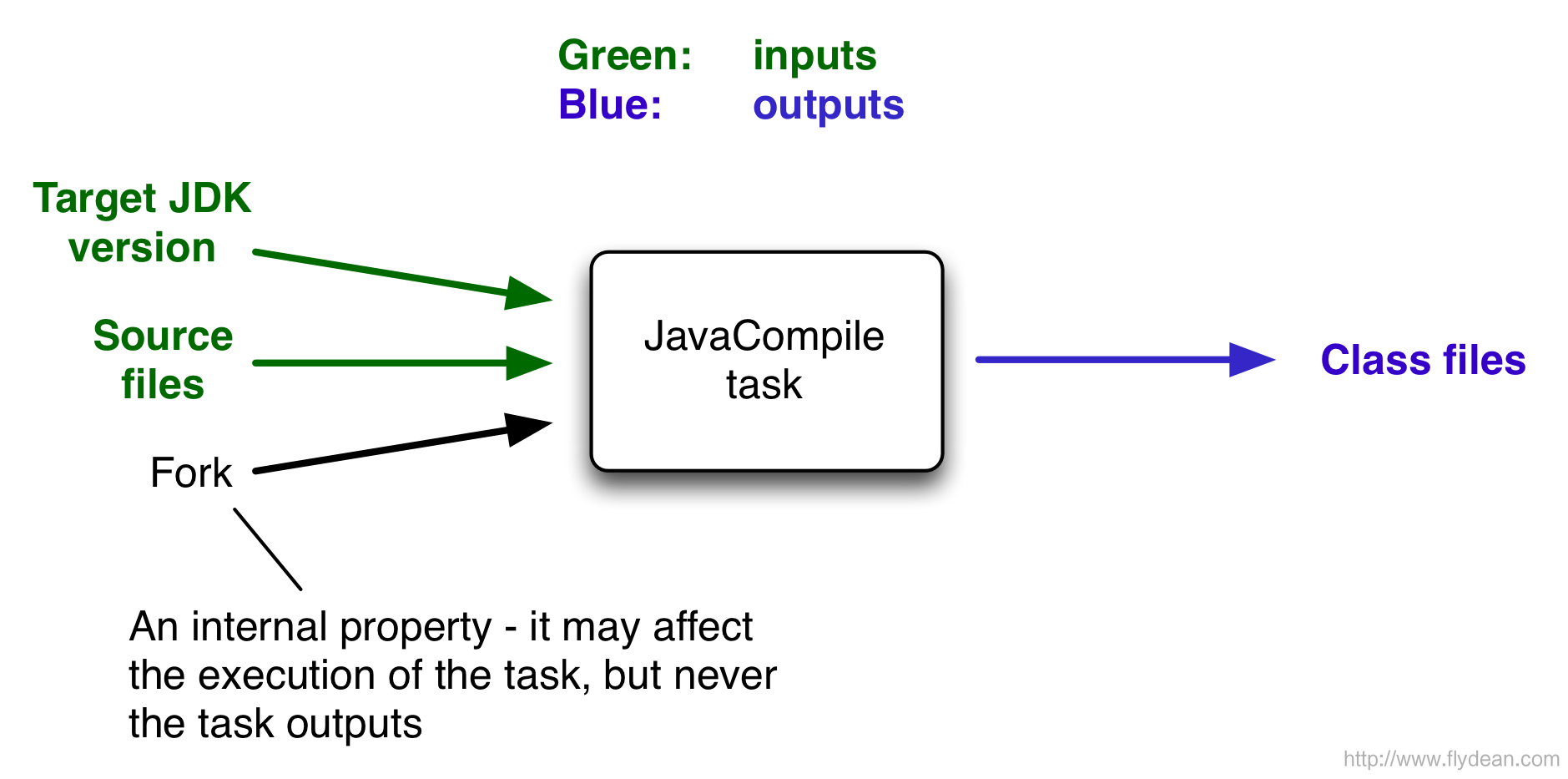
以上图为例,input就是目标jdk的版本,源代码等,output就是编译出来的class文件。
增量构建的原理就是监控input的变化,只有input发送变化了,才重新执行task任务,否则gradle认为可以重用之前的执行结果。
所以在编写gradle的task的时候,需要指定task的输入和输出。
并且要注意只有会对输出结果产生变化的才能被称为输入,如果你定义了对初始结果完全无关的变量作为输入,则这些变量的变化会导致gradle重新执行task,导致了不必要的性能的损耗。
还要注意不确定执行结果的任务,比如说同样的输入可能会得到不同的输出结果,那么这样的任务将不能够被配置为增量构建任务。
自定义inputs和outputs
既然task中的input和output在增量编译中这么重要,本章将会给大家讲解一下怎么才能够在task中定义input和output。
如果我们自定义一个task类型,那么满足下面两点就可以使用上增量构建了:
第一点,需要为task中的inputs和outputs添加必要的getter方法。
第二点,为getter方法添加对应的注解。
gradle支持三种主要的inputs和outputs类型:
简单类型:简单类型就是所有实现了Serializable接口的类型,比如说string和数字。
文件类型:文件类型就是 File 或者 FileCollection 的衍生类型,或者其他可以作为参数传递给 Project.file(java.lang.Object) 和 Project.files(java.lang.Object...) 的类型。
嵌套类型:有些自定义类型,本身不属于前面的1,2两种类型,但是它内部含有嵌套的inputs和outputs属性,这样的类型叫做嵌套类型。
接下来,我们来举个例子,假如我们有一个类似于FreeMarker和Velocity这样的模板引擎,负责将模板源文件,要传递的数据最后生成对应的填充文件,我们考虑一下他的输入和输出是什么。
输入:模板源文件,模型数据和模板引擎。
输出:要输出的文件。
如果我们要编写一个适用于模板转换的task,我们可以这样写:
import java.io.File;
import java.util.HashMap;
import org.gradle.api.*;
import org.gradle.api.file.*;
import org.gradle.api.tasks.*;
public class ProcessTemplates extends DefaultTask {
private TemplateEngineType templateEngine;
private FileCollection sourceFiles;
private TemplateData templateData;
private File outputDir;
@Input
public TemplateEngineType getTemplateEngine() {
return this.templateEngine;
}
@InputFiles
public FileCollection getSourceFiles() {
return this.sourceFiles;
}
@Nested
public TemplateData getTemplateData() {
return this.templateData;
}
@OutputDirectory
public File getOutputDir() { return this.outputDir; }
// 上面四个属性的setter方法
@TaskAction
public void processTemplates() {
// ...
}
}
上面的例子中,我们定义了4个属性,分别是TemplateEngineType,FileCollection,TemplateData和File。前面三个属性是输入,后面一个属性是输出。
除了getter和setter方法之外,我们还需要在getter方法中添加相应的注释: @Input , @InputFiles ,@Nested 和 @OutputDirectory, 除此之外,我们还定义了一个 @TaskAction 表示这个task要做的工作。
TemplateEngineType表示的是模板引擎的类型,比如FreeMarker或者Velocity等。我们也可以用String来表示模板引擎的名字。但是为了安全起见,这里我们自定义了一个枚举类型,在枚举类型内部我们可以安全的定义各种支持的模板引擎类型。
因为enum默认是实现Serializable的,所以这里可以作为@Input使用。
sourceFiles使用的是FileCollection,表示的是一系列文件的集合,所以可以使用@InputFiles。
为什么TemplateData是@Nested类型的呢?TemplateData表示的是我们要填充的数据,我们看下它的实现:
import java.util.HashMap;
import java.util.Map;
import org.gradle.api.tasks.Input;
public class TemplateData {
private String name;
private Map<String, String> variables;
public TemplateData(String name, Map<String, String> variables) {
this.name = name;
this.variables = new HashMap<>(variables);
}
@Input
public String getName() { return this.name; }
@Input
public Map<String, String> getVariables() {
return this.variables;
}
}
可以看到,虽然TemplateData本身不是File或者简单类型,但是它内部的属性是简单类型的,所以TemplateData本身可以看做是@Nested的。
outputDir表示的是一个输出文件目录,所以使用的是@OutputDirectory。
使用了这些注解之后,gradle在构建的时候就会检测和上一次构建相比,这些属性有没有发送变化,如果没有发送变化,那么gradle将会直接使用上一次构建生成的缓存。
注意,上面的例子中我们使用了FileCollection作为输入的文件集合,考虑一种情况,假如只有文件集合中的某一个文件发送变化,那么gradle是会重新构建所有的文件,还是只重构这个被修改的文件呢?
留给大家讨论
除了上讲到的4个注解之外,gradle还提供了其他的几个有用的注解:
@InputFile: 相当于File,表示单个input文件。
@InputDirectory: 相当于File,表示单个input目录。
@Classpath: 相当于Iterable,表示的是类路径上的文件,对于类路径上的文件需要考虑文件的顺序。如果类路径上的文件是jar的话,jar中的文件创建时间戳的修改,并不会影响input。
@CompileClasspath:相当于Iterable,表示的是类路径上的java文件,会忽略类路径上的非java文件。
@OutputFile: 相当于File,表示输出文件。
@OutputFiles: 相当于Map<String, File> 或者 Iterable,表示输出文件。
@OutputDirectories: 相当于Map<String, File> 或者 Iterable,表示输出文件。
@Destroys: 相当于File 或者 Iterable,表示这个task将会删除的文件。
@LocalState: 相当于File 或者 Iterable,表示task的本地状态。
@Console: 表示属性不是input也不是output,但是会影响console的输出。
@Internal: 内部属性,不是input也不是output。
@ReplacedBy: 属性被其他的属性替换了,不能算在input和output中。
@SkipWhenEmpty: 和@InputFiles 跟 @InputDirectory一起使用,如果相应的文件或者目录为空的话,将会跳过task的执行。
@Incremental: 和@InputFiles 跟 @InputDirectory一起使用,用来跟踪文件的变化。
@Optional: 忽略属性的验证。
@PathSensitive: 表示需要考虑paths中的哪一部分作为增量的依据。
运行时API
自定义task当然是一个非常好的办法来使用增量构建。但是自定义task类型需要我们编写新的class文件。有没有什么办法可以不用修改task的源代码,就可以使用增量构建呢?
答案是使用Runtime API。
gradle提供了三个API,用来对input,output和Destroyables进行获取:
Task.getInputs() of type TaskInputs
Task.getOutputs() of type TaskOutputs
Task.getDestroyables() of type TaskDestroyables
获取到input和output之后,我们就是可以其进行操作了,我们看下怎么用runtime API来实现之前的自定义task:
task processTemplatesAdHoc {
inputs.property("engine", TemplateEngineType.FREEMARKER)
inputs.files(fileTree("src/templates"))
.withPropertyName("sourceFiles")
.withPathSensitivity(PathSensitivity.RELATIVE)
inputs.property("templateData.name", "docs")
inputs.property("templateData.variables", [year: 2013])
outputs.dir("$buildDir/genOutput2")
.withPropertyName("outputDir")
doLast {
// Process the templates here
}
}
上面例子中,inputs.property() 相当于 @Input ,而outputs.dir() 相当于@OutputDirectory。
Runtime API还可以和自定义类型一起使用:
task processTemplatesWithExtraInputs(type: ProcessTemplates) {
// ...
inputs.file("src/headers/headers.txt")
.withPropertyName("headers")
.withPathSensitivity(PathSensitivity.NONE)
}
上面的例子为ProcessTemplates添加了一个input。
隐式依赖
除了直接使用dependsOn之外,我们还可以使用隐式依赖:
task packageFiles(type: Zip) {
from processTemplates.outputs
}
上面的例子中,packageFiles 使用了from,隐式依赖了processTemplates的outputs。
gradle足够智能,可以检测到这种依赖关系。
上面的例子还可以简写为:
task packageFiles2(type: Zip) {
from processTemplates
}
我们看一个错误的隐式依赖的例子:
plugins {
id 'java'
}
task badInstrumentClasses(type: Instrument) {
classFiles = fileTree(compileJava.destinationDir)
destinationDir = file("$buildDir/instrumented")
}
这个例子的本意是执行compileJava任务,然后将其输出的destinationDir作为classFiles的值。
但是因为fileTree本身并不包含依赖关系,所以上面的执行的结果并不会执行compileJava任务。
我们可以这样改写:
task instrumentClasses(type: Instrument) {
classFiles = compileJava.outputs.files
destinationDir = file("$buildDir/instrumented")
}
或者使用layout:
task instrumentClasses2(type: Instrument) {
classFiles = layout.files(compileJava)
destinationDir = file("$buildDir/instrumented")
}
或者使用buildBy:
task instrumentClassesBuiltBy(type: Instrument) {
classFiles = fileTree(compileJava.destinationDir) {
builtBy compileJava
}
destinationDir = file("$buildDir/instrumented")
}
输入校验
gradle会默认对@InputFile ,@InputDirectory 和 @OutputDirectory 进行参数校验。
如果你觉得这些参数是可选的,那么可以使用@Optional。
自定义缓存方法
上面的例子中,我们使用from来进行增量构建,但是from并没有添加@InputFiles, 那么它的增量缓存是怎么实现的呢?
我们看一个例子:
public class ProcessTemplates extends DefaultTask {
// ...
private FileCollection sourceFiles = getProject().getLayout().files();
@SkipWhenEmpty
@InputFiles
@PathSensitive(PathSensitivity.NONE)
public FileCollection getSourceFiles() {
return this.sourceFiles;
}
public void sources(FileCollection sourceFiles) {
this.sourceFiles = this.sourceFiles.plus(sourceFiles);
}
// ...
}
上面的例子中,我们将sourceFiles定义为可缓存的input,然后又定义了一个sources方法,可以将新的文件加入到sourceFiles中,从而改变sourceFile input,也就达到了自定义修改input缓存的目的。
我们看下怎么使用:
task processTemplates(type: ProcessTemplates) {
templateEngine = TemplateEngineType.FREEMARKER
templateData = new TemplateData("test", [year: 2012])
outputDir = file("$buildDir/genOutput")
sources fileTree("src/templates")
}
我们还可以使用project.layout.files()将一个task的输出作为输入,可以这样做:
public void sources(Task inputTask) {
this.sourceFiles = this.sourceFiles.plus(getProject().getLayout().files(inputTask));
}
这个方法传入一个task,然后使用project.layout.files()将task的输出作为输入。
看下怎么使用:
task copyTemplates(type: Copy) {
into "$buildDir/tmp"
from "src/templates"
}
task processTemplates2(type: ProcessTemplates) {
// ...
sources copyTemplates
}
非常的方便。
如果你不想使用gradle的缓存功能,那么可以使用upToDateWhen()来手动控制:
task alwaysInstrumentClasses(type: Instrument) {
classFiles = layout.files(compileJava)
destinationDir = file("$buildDir/instrumented")
outputs.upToDateWhen { false }
}
上面使用false,表示alwaysInstrumentClasses这个task将会一直被执行,并不会使用到缓存。
输入归一化
要想比较gradle的输入是否是一样的,gradle需要对input进行归一化处理,然后才进行比较。
我们可以自定义gradle的runtime classpath 。
normalization {
runtimeClasspath {
ignore 'build-info.properties'
}
}
上面的例子中,我们忽略了classpath中的一个文件。
我们还可以忽略META-INF中的manifest文件的属性:
normalization {
runtimeClasspath {
metaInf {
ignoreAttribute("Implementation-Version")
}
}
}
忽略META-INF/MANIFEST.MF :
normalization {
runtimeClasspath {
metaInf {
ignoreManifest()
}
}
}
忽略META-INF中所有的文件和目录:
normalization {
runtimeClasspath {
metaInf {
ignoreCompletely()
}
}
}
其他使用技巧
如果你的gradle因为某种原因暂停了,你可以送 --continuous 或者 -t 参数,来重用之前的缓存,继续构建gradle项目。
你还可以使用 --parallel 来并行执行task。
本文已收录于 http://www.flydean.com/gradle-incremental-build/
最通俗的解读,最深刻的干货,最简洁的教程,众多你不知道的小技巧等你来发现!
欢迎关注我的公众号:「程序那些事」,懂技术,更懂你!
gradle中的增量构建的更多相关文章
- 在gradle中构建java项目
目录 简介 构建java项目的两大插件 管理依赖 编译代码 管理resource 打包和发布 生成javadoc 简介 之前的文章我们讲到了gradle的基本使用,使用gradle的最终目的就是为了构 ...
- Gradle中的buildScript代码块
在编写Gradle脚本的时候,在build.gradle文件中经常看到这样的代码: build.gradle 1 2 3 4 5 6 7 8 9 buildScript { repositories ...
- Gradle中使用idea插件的一些实践
如果你的项目使用了Gradle作为构建工具,那么你一定要使用Gradle来自动生成IDE的项目文件,无需再手动的将源代码导入到你的IDE中去了. 如果你使用的是eclipse,可以在build.gra ...
- Gradle学习系列之八——构建多个Project
在本系列的上篇文章中,我们讲到了Gradle的依赖管理,在本篇文章中,我们将讲到如何构建多个Project. 请通过以下方式下载本系列文章的Github示例代码: git clone https:// ...
- Gradle用户指南(3)-构建Java项目
1.构建基本的Java项目 为了使用 Java 插件,添加下面代码到构建文件: build.gradle apply plugin: 'java' 这个就是 定义一个 Java 项目的全部.它会将 J ...
- [转] Gradle中的buildScript代码块
PS: 在build script中的task apply plugin: 'spring-boot' 需要 classpath("org.springframework.boot:spri ...
- Gradle 1.12 翻译——第十七章. 从 Gradle 中调用 Ant
有关其他已翻译的章节请关注Github上的项目:https://github.com/msdx/gradledoc/tree/1.12,或访问:http://gradledoc.qiniudn.com ...
- Gradle中的闭包
Gradle是基于Groovy的DSL基础上的构建工具,Gradle中的闭包,其原型上实际上即Groovy中闭包.而在表现形式上,其实,Gradle更多的是以约定和基于约定基础上的配置去展现.但本质上 ...
- 在 Gradle 中使用 MyBatis Generator
在 Intellij IDEA 中结合 Gradle 使用 MyBatis Generator 逆向生成代码 Info: JDK 1.8 Gradle 2.14 Intellij IDEA 2016. ...
随机推荐
- 转 5 jmeter性能测试小小的实战
5 jmeter性能测试小小的实战 项目描述 被测网址:www.sogou.com指标:相应时间以及错误率场景:线程数 20.Ramp-Up Period(in seconds) 10.循环次数 ...
- 全栈性能测试修炼宝典-JMeter实战笔记(三)
JMeter体系结构 简介 JMeter是一款开源桌面应用软件,可用来模拟用户负载来完成性能测试工作. JMeter体系结构 X1~X5是负载模拟的一个过程,使用这些组件来完成负载的模拟 Y1:包含的 ...
- 【UNIAPP】接入导航系统完整版
// 查询附近/搜索关键词 <template> <view> <!--地图容器--> <map id="myMap" :markers= ...
- jQuery 移入显示div,移出当前div,移入到另一个div还是显示。
jQuery 移入移出 操作div 1 <style type="text/css"> 2 .box{ 3 position: relative; 4 } 5 .box ...
- 树莓派zero 使用usb串口连接
使用minicom连接bash$ lsusbBus 002 Device 001: ID 1d6b:0003 Linux Foundation 3.0 root hubBus 001 Device 0 ...
- TCP随笔
目录 前言 正文 time_wait和rst fin与连接关闭 nagel和ack延迟算法 滑动窗口与拥塞控制 文末 总结 测试代码 前言 网上已经有大量关于tcp的文章,感觉作为一名技术人员,不写一 ...
- Flink-v1.12官方网站翻译-P014-Flink Architecture
Flink架构 Flink是一个分布式系统,为了执行流式应用,需要对计算资源进行有效的分配和管理.它集成了所有常见的集群资源管理器,如Hadoop YARN.Apache Mesos和Kubernet ...
- 动态代理+静态代理+cglib代理 详解
代理定义:代理(Proxy):是一种设计模式,提供了对目标对象另外的访问方式;即通过代理对象访问目标对象.好处是:可以在目标对象实现的基础上,增强额外的功能操作,即扩展目标对象的功能. 动态代理+静态 ...
- jackson学习之八:常用方法注解
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- vs中python包安装教程
vs安装python很简单,只需要在vs安装包中选择python就可以了,这里使用的python3.7: 如果有了解,都知道安装python包的指令:"pip install xxx&quo ...