sql处理重复的列,更好理清分组和分区
一、分组统计、分区排名
1、语法和含义:
如果查询结果看得有疑惑,看第二部分-sql处理重复的列,更好理清分组和分区,有建表插入数据的sql语句
分组统计:GROUP BY 结合 统计/聚合函数一起使用
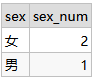
-- 举例子: 按照性别统计男生、女生的人数
select sex,count(distinct id) sex_num from student_score group by sex;
分区排名:ROW_NUMBER() OVER(PARTITION BY 分区的字段 ORDER BY 升序/降序字段 [DESC])
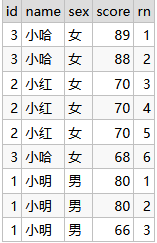
-- 举例子: 按照性别-男生、女生进行分区,按照成绩进行降序
select id,name,sex,score,
ROW_NUMBER() OVER(PARTITION BY sex ORDER BY score DESC) rn
from student_score;
2、使用注意事项:
▷ 排名函数row_number() 需要的mysql 版本需要8及以上!
▷ 对于分组统计 group by 容易出现的报错问题:
因为规定要求 select 列表的字段非聚合字段,必须出现在group by后面进行分组。
报错:Expression #1 of SELECT list is not in GROUP BY clause and contains nonaggregated column '数据库.表.字段' which is not functionally dependent on columns in GROUP BY clause; this is incompatible with sql_mode=only_full_group_by
SELECT列表的表达式-不在GROUP BY子句中,并且包含非聚合列'数据库.表.字段'。
▷ 对于排名函数ROW_NUMBER,容易出现的报错问题:
- 一般是你的分区字段写得有问题,可以坚持一下分区字段!比如在hive中,分区字段为 get_json_object(map_col,'$.title'),但是漏掉了一个'
报错:Failed to breakup Windowing invocations into Groups. At least 1 group must only depend on input columns. Also check for circular dependencies.
未能将窗口调用分解为组。至少 1 个组必须仅依赖于输入列。还要检查循环依赖。
二、sql处理重复的列,更好理清分组和分区
1、sql语句-建表、插入数据的语句
DROP TABLE IF EXISTS `student_score`;
CREATE TABLE `student_score` (
`id` int(6),
`name` varchar(255),
`sex` varchar(255),
`subject` varchar(30),
`score` float
) ENGINE = InnoDB;
INSERT INTO `student_score` VALUES (1, '小明', '男','语文', 80);
INSERT INTO `student_score` VALUES (2, '小红', '女','语文', 70);
INSERT INTO `student_score` VALUES (3, '小哈', '女','语文', 88);
INSERT INTO `student_score` VALUES (1, '小明', '男','数学', 66);
INSERT INTO `student_score` VALUES (2, '小红', '女','数学', 70);
INSERT INTO `student_score` VALUES (3, '小哈', '女','数学', 89);
INSERT INTO `student_score` VALUES (1, '小明', '男','英语', 80);
INSERT INTO `student_score` VALUES (2, '小红', '女','英语', 70);
INSERT INTO `student_score` VALUES (3, '小哈', '女','英语', 68);
2、查询所有学生的成绩:
- select * from student_score;
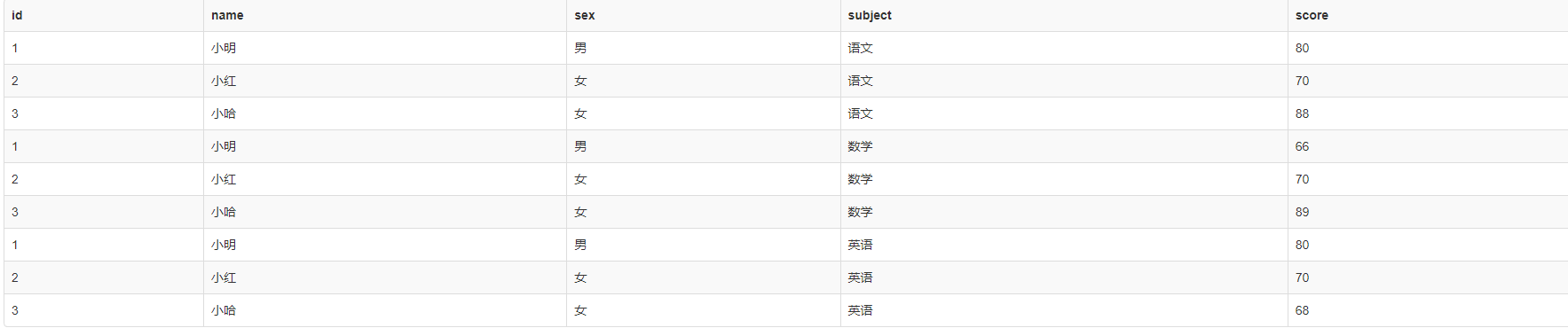
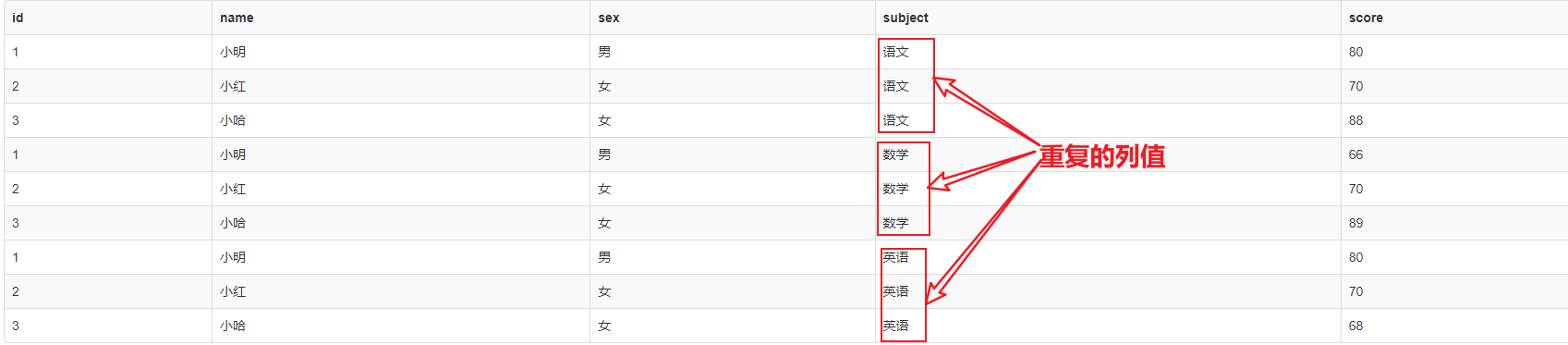
3、结果,有重复的列值
相应的成绩对应的学科名称是以列的形式展示的,造成了语文、语文、语文的重复
4-1、处理重复的列-方式1-合并去除重复的列值[列转行]
对应到常见的sql应用场景,统计各个学生的各科成绩,实现方式有两种,一种是分组统计的方式,一种是分区排名的方式
分组统计:
select id,name,sex,
max(case when subject='语文' then score else 0 end) as chinese,
max(case when subject='英语' then score else 0 end) as english,
max(case when subject='数学' then score else 0 end) as math
from student_score
group by id
order by score desc
- 结果:

按成绩降序排序,可以看到默认选择第一门学科-语文的成绩进行降序排序。
4-2、处理重复的列-方式2-对重复的列值进行排名
分区排名
select id,name,subject,score,
row_number() over(partition by subject order by score desc) rn
from student_score;
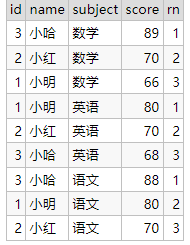
三、总结分组、分区的区别
例如按学科分组或按学科分区,那么,分组得到的是一个列值(一条记录数据)的结果,分区是多个列值(多条记录数据)的结果。
分组-一条记录

分区-多条记录

如果本文对你有帮助的话记得给一乐点个赞哦,感谢!
sql处理重复的列,更好理清分组和分区的更多相关文章
- SQL 表连接查询出现重复列,由此理清LEFT JOIN、INNER JOIN的区别
1.先创建两个临时表,并插入数据 CREATE TABLE #TEMP1( ID INT IDENTITY(1,1) PRIMARY KEY, name NVARCHAR(50)) CREATE TA ...
- SQL SERVER FOR 多列字符串连接 XML PATH 及 STUFF
原文:SQL SERVER FOR 多列字符串连接 XML PATH 及 STUFF 本来用 Writer 写一篇关于一列多行合并的博客来的,结果快写完了时候,在一个插入代码时候,崩了,重新打开,居然 ...
- ASP.NET中重复表格列合并的实现方法(转自脚本之家)
这几天做一个项目有用到表格显示数据的地方,客户要求重复的数据列需要合并,就总结了一下.NET控件GridView 和 Repeater 关于重复数据合并的方法. 这是合并之前的效果: 合并之后的效果图 ...
- sql去除重复语句
转自芙蓉清秀的BLOG http://blog.sina.com.cn/liurongxiu1211 sql去除重复语句 (2012-06-15 15:00:01) sql 单表/多表查询去除重复记 ...
- SQL Server 2014 聚集列存储
SQL Server 自2012以来引入了列存储的概念,至今2016对列存储的支持已经是非常友好了.由于我这边线上环境主要是2014,所以本文是以2014为基础的SQL Server 的列存储的介绍. ...
- SQL中进行转列的几种方式
SQL中进行转列 在很多笔试的程序员中会有很多写SQL的情况,其中很多时候会考察行转列.那么这个时候如果能写出来几种行转列的SQL,会给面试官留下比较好的印象. 以下是这次sql转换的表结构以及数据 ...
- SQL Server-聚焦计算列或计算列持久化查询性能(二十二)
前言 上一节我们详细讲解了计算列以及计算列持久化的问题,本节我们依然如前面讲解来看看二者查询性能问题,简短的内容,深入的理解,Always to review the basics. 持久化计算列比非 ...
- SQL Server 2000 sp2 及更低版本不受此版本的 Windows 支持
SQL Server 2000 sp2 及更低版本不受此版本的 Windows 支持.在安装了 SQL Server 2000 之后请应用 sp3. 出现这种现象的原因在于:Windows Serve ...
- [转]java.sql.SQLException: 无效的列索引
原文地址:http://blog.sina.com.cn/s/blog_6bc811e401011a17.html java.sql.SQLException: 无效的列索引 “无效的列索引”其实是个 ...
- java.sql.SQLException: 无效的列索引
java.sql.SQLException: 无效的列索引 "无效的列索引"其实是个低级的错误,原因无非几个: 1.sql串的?号数目和提供的变量数目不一致: 例如:jdbcTem ...
随机推荐
- linux篇之WC(word count)的使用概述
Text. Linux系统中的wc(Word Count)命令的功能为统计指定文件中的字节数.字数.行数,并将统计结果显示输出. 1.命令格式: wc [选项] [文件1] [文件2] ... 2.命 ...
- PostScript语言教程(四、程序变量使用)
4.1.变量定义 POSTSCRIPT 变量 变量的定义是将比那两名和值用def进行关联类似 /ppi 75 def %将ppi定义为75 /ppi ppi 1 add def %将ppi + 1的值 ...
- #ifdef _WIN32 #ifdef _WIN64
#ifdef _WIN32#ifdef _WIN64 这样的代码,实际上这提供了一种抽象机制,使代码可以在不同平台间移植. #ifdef _WIN32 #ifdef _WIN64 {windows 6 ...
- 学PHP的第二天!
这是我学PHP的第二天,我改了一些代码,终于把我喜欢的OJ网站的默认模板给改掉了,竟然能用!!!我从来都没有这么的欣喜过,看来PHP果真是一门非常好用的编程语言,但这个OJ有些用的是python的模块 ...
- 使用Wireshark完成实验1
用来观察协议执行实体之间交换的报文的基本工具被称为分组嗅探器(packet sniffer),一个分组嗅探器被动地拷贝(嗅探)计算机发送和接受的报文,也能显示出这些被捕获报文的各个协议字段的内容.Wi ...
- SQL-增删改
-- 删除表drop table -- 建表create table -- 表注释comment on table ... is ...-- 字段注释comment on column ... is ...
- Centos使用nohup实现后台运行程序
nohup和&的区别& : 指在后台运行 nohup : 不挂断的运行,注意并没有后台运行的功能,,就是指,用nohup运行命令可以使命令永久的执行下去,和用户终端没有关系,例如我们断 ...
- Java字符串的一些函数方法
一.substring()方法 String str="123456"; String s1=str.substring(2); //s1="3456" Str ...
- python基础篇 15-常用模块:random string sorted lambda函数
一.random import os,random,sys,time,string print(random.randint(1,10)) # 产生随机的整数 print(random.uniform ...
- IDEA-mybatis逆向工程使用
首先我们需要安装mybatis逆向工程插件mybatis Generator: 然后在pom.xml文件中添加逆向工程插件: <!--mybatis逆向工程插件--> <plugin ...