ElasticSearch7.3学习(二十一)----Filter与Query对比、使用explain关键字分析语法
1、数据准备
首先创建book索引
PUT /book/
{
"settings": {
"number_of_shards": 1,
"number_of_replicas": 0
},
"mappings": {
"properties": {
"name": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
},
"description": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
},
"studymodel": {
"type": "keyword"
},
"price": {
"type": "double"
},
"timestamp": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"
},
"pic": {
"type": "text",
"index": false
}
}
}
}插入数据
PUT /book/_doc/1
{
"name": "Bootstrap开发",
"description": "Bootstrap是一个非常流行的开发框架。此开发框架可以帮助不擅长css页面开发的程序人员轻松的实现一个css,不受浏览器限制的精美界面css效果。",
"studymodel": "201002",
"price": 38.6,
"timestamp": "2019-08-25 19:11:35",
"pic": "group1/M00/00/00/wKhlQFs6RCeAY0pHAAJx5ZjNDEM428.jpg",
"tags": [
"bootstrap",
"dev"
]
}
PUT /book/_doc/2
{
"name": "java编程思想",
"description": "java语言是世界第一编程语言,在软件开发领域使用人数最多。",
"studymodel": "201001",
"price": 68.6,
"timestamp": "2019-08-25 19:11:35",
"pic": "group1/M00/00/00/wKhlQFs6RCeAY0pHAAJx5ZjNDEM428.jpg",
"tags": [
"java",
"dev"
]
}
PUT /book/_doc/3
{
"name": "spring开发基础",
"description": "spring 在java领域非常流行,java程序员都在用。",
"studymodel": "201001",
"price": 88.6,
"timestamp": "2019-08-24 19:11:35",
"pic": "group1/M00/00/00/wKhlQFs6RCeAY0pHAAJx5ZjNDEM428.jpg",
"tags": [
"spring",
"java"
]
}2、Filter与Query示例
需求:用户查询description中有"java程序员",并且价格大于80小于90的数据。
2.1 Query
首先采用Query来进行查询,首先查询description中有"java程序员"。
GET /book/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"description": "java程序员"
}
}
]
}
}
}查询结果如下:
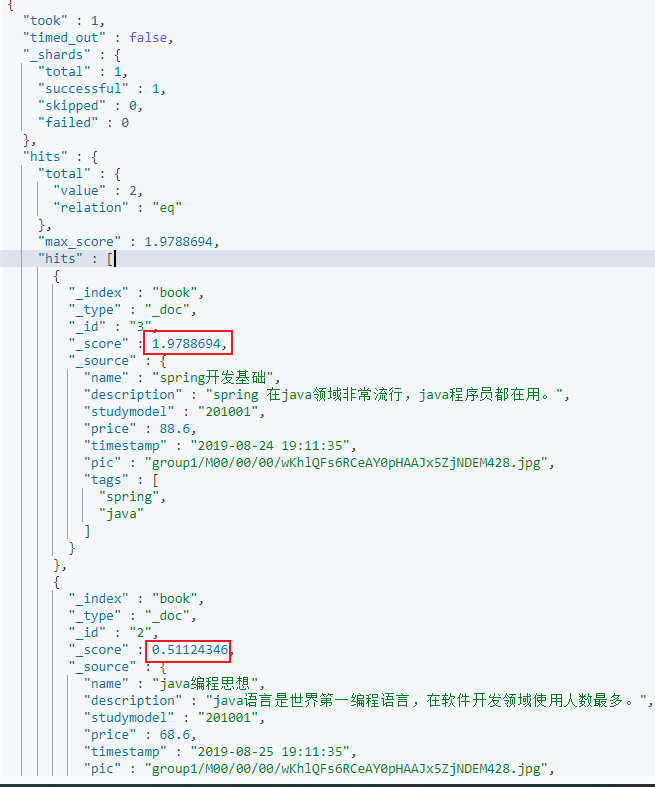
可以看到,查询出来两条数据,score分别是1.9、0.5。
然后查询description中有"java程序员",并且价格大于80小于90的数据
GET /book/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"description": "java程序员"
}
},
{
"range": {
"price": {
"gte": 80,
"lte": 90
}
}
}
]
}
}
}再次查看结果:

这次查询出来一条数据,score变为2.9。这一条数据在上一次的查询结果中的score为1.9。然后接着往下看使用Filter。
2.2 filter
还是相同的需求,首先查询description中有"java程序员"。
GET /book/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"description": "java程序员"
}
}
]
}
}
}查询结果如下:
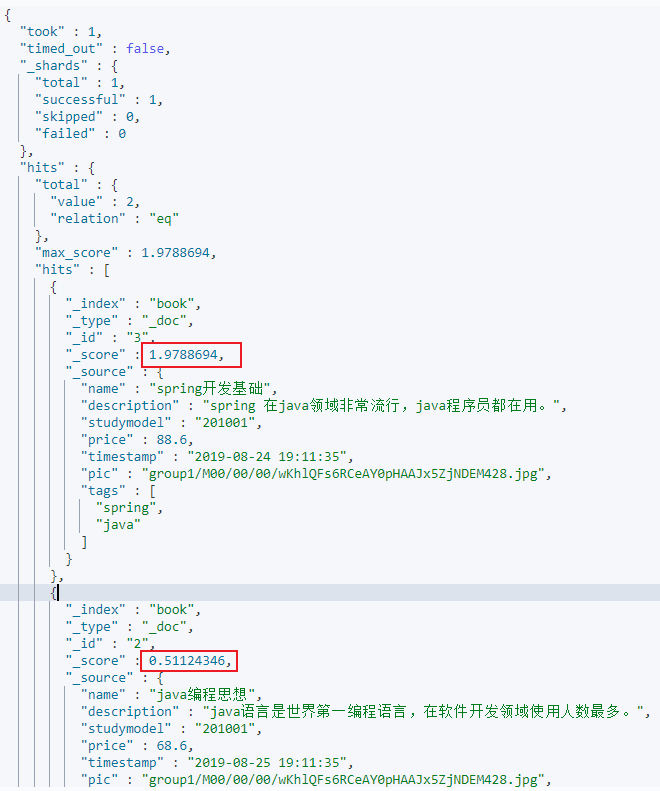
通过查询结果可以看到,查询的两条数据的score是1.9、0.5。
然后使用filter查询description中有"java程序员",并且价格大于80小于90的数据
GET /book/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"description": "java程序员"
}
}
],
"filter": {
"range": {
"price": {
"gte": 80,
"lte": 90
}
}
}
}
}
}查询结果如下:

可以看到,查询出来的数据与使用query查询结果一样,但是score依旧为1.9。
说明在使用query查询的过程中,影响到了相关度(score)的排序,在使用filter进行查询,并不会影响相关度(score)的计算。
2.3 filter与query对比
filter,仅仅只是按照搜索条件过滤出需要的数据而已,不计算任何相关度分数,对相关度没有任何影响。
query,会去计算每个document相对于搜索条件的相关度,并按照相关度进行排序。
应用场景:
一般来说,如果你是在进行搜索,需要将最匹配搜索条件的数据先返回,那么用query。如果你只是要根据一些条件筛选出一部分数据,不关注其排序,那么用filter。
2.4 filter与query性能
filter,不需要计算相关度分数,不需要按照相关度分数进行排序,同时还有内置的自动cache最常使用filter的数据。比如在范围查询,keyword字段查询中推荐使用filter来进行查询。
query,相反,要计算相关度分数,按照分数进行排序,而且无法cache结果。
在同等查询结果下,filter的性能一般是要优于query的。
3、explain分析语法
在实际的应用过程中,需要查询的逻辑一般比较复杂,那当语句冗长的时候,这时候显然不太可能通过直接执行语句来调试语法正确与否,这个时候就可以通过explain来验证语句的正确性。
验证错误语句:
GET /book/_validate/query?explain
{
"query": {
"mach": {
"description": "java程序员"
}
}
}返回结果如下,错误信息为没有名叫mach的query。
{
"valid" : false,
"error" : "org.elasticsearch.common.ParsingException: no [query] registered for [mach]"
}再来看语句正确的情况下
GET /book/_validate/query?explain
{
"query": {
"match": {
"description": "java程序员"
}
}
}返回,返回结果还包含对语句的解释:从description查询java关键词,从description查询程序员关键词。
{
"_shards" : {
"total" : 1,
"successful" : 1,
"failed" : 0
},
"valid" : true,
"explanations" : [
{
"index" : "book",
"valid" : true,
"explanation" : "description:java description:程序员"
}
]
}应用场景:
一般用在那种特别复杂庞大的搜索下,比如你一下子写了上百行的搜索,这个时候可以先用validate api去验证一下,搜索是否合法。合法以后,explain就像mysql的执行计划,可以看到搜索的目标等信息。
ElasticSearch7.3学习(二十一)----Filter与Query对比、使用explain关键字分析语法的更多相关文章
- ElasticSearch教程——filter与query对比(转学习使用)
一.数据准备 PUT /company/employee/2 { "address": { "country": "china", &quo ...
- Elasticsearch学习笔记(十二)filter与query
一.keyword 字段和keyword数据类型 1.测试准备数据 POST /forum/article/_bulk { "index": { "_id" ...
- ElasticSearch7.3学习(二十五)----Doc value、query phase、fetch phase解析
1.Doc value 搜索的时候,要依靠倒排索引: 排序的时候,需要依靠正排索引,看到每个document的每个field,然后进行排序. 所谓的正排索引,其实就是doc values. 在建立索引 ...
- ElasticSearch7.3学习(二十六)----搜索(Search)参数总结、结果跳跃(bouncing results)问题解析
1.preference 首先引入一个bouncing results问题,两个document排序,field值相同:不同的shard上,可能排序不同:每次请求轮询打到不同的replica shar ...
- ElasticSearch7.3学习(二十四)----相关度评分机制详解
1.算法介绍 relevance score(相关性分数) 算法,简单来说,就是计算出,一个索引中的文本,与搜索文本,他们之间的关联匹配程度.Elasticsearch使用的是 term freque ...
- ElasticSearch7.3学习(二十三)----RestHighLevelClient Java api实现match_all、ids、match、term、multi_match、bool、filter、sort等不同的搜索方式
1.数据准备 首先创建book索引 PUT /book/ { "settings": { "number_of_shards": 1, "number ...
- JavaWeb学习 (二十一)————基于Servlet+JSP+JavaBean开发模式的用户登录注册
一.Servlet+JSP+JavaBean开发模式(MVC)介绍 Servlet+JSP+JavaBean模式(MVC)适合开发复杂的web应用,在这种模式下,servlet负责处理用户请求,jsp ...
- Python3.5 学习二十一
本节内容概要: 上节回顾及补充知识点: 一.请求周期: URL->路由->函数或类->返回字符串或者模板 Form表单提交: 提交->url-函数或者类中的方法 -....(执 ...
- Scala学习二十一——隐式转换和隐式参数
一.本章要点 隐式转换用于类型之间的转换 必须引入隐式转换,并确保它们可以以单个标识符的形式出现在当前作用域 隐式参数列表会要求指定类型的对象.它们可以从当前作用域中以单个标识符定义的隐式对象的获取, ...
随机推荐
- python+pytest接口自动化(11)-测试函数、测试类/测试方法的封装
前言 在python+pytest 接口自动化系列中,我们之前的文章基本都没有将代码进行封装,但实际编写自动化测试脚本中,我们都需要将测试代码进行封装,才能被测试框架识别执行. 例如单个接口的请求代码 ...
- MySQL—分页查询
分页查询 应用场景:当要显示的数据,当一页显示不全,有很多的数据时,就需要分页提交sql请求 语法:select 查询列表 from表名 [ join type join 表2 on连接条件 whe ...
- 用ssh无密码登录远程linux
登录linux常用的方式是:用户名+密码,多次输入密码非常不方便,所以推荐使用密钥登录,安全又方便,下面我说下怎么使用密钥登录. 生成密钥 使用密钥登录首先需要本地有ssh密钥 如果本地没有密钥,那么 ...
- PCIe Tandem PROM 方法
PCIe Tandem PROM 方法 什么是Tandem PROM? 简单总结:市面多数的FPGA都是SRAM型,需要在上电时从外部存储器件完成代码的加载,对于具有PCIe功能的SRAM FPGA而 ...
- Azure DevOps (七) 通过SSH部署上传到服务器的应用
上一篇中,我们实现了通过FTP把流水线编译出来的制品上传到我们的公网服务器上,这一篇我们来研究一下通过azure的ssh连接到服务器 把应用在服务器上运行起来. 首先,我们书接上文,在release流 ...
- 【Python 第0课】Why Python?
为什么用Python作为编程入门语言? 原因很简单. 嗯...原因就是,很简单... 每种语言都会有它的支持者和反对者.去Google一下"why python"(程序员准则:要G ...
- JVM 内存 (堆(heap)、栈(stack)和方法区(method) )
JVM 内存初学 (堆(heap).栈(stack)和方法区(method) ) 堆区: 1.存储的全部是对象,每个对象都包含一个与之对应的class的信息.(class的目的是得到操作指令)2.jv ...
- 如何给Spring 容器提供配置元数据?
这里有三种重要的方法给Spring 容器提供配置元数据. XML配置文件. 基于注解的配置. 基于java的配置.
- 转:master公式(主方法)
master公式(也称主方法)是利用分治策略来解决问题经常使用的时间复杂度的分析方法,(补充:分治策略的递归解法还有两个常用的方法叫做代入法和递归树法),众所众知,分治策略中使用递归来求解问题分为三步 ...
- su 和 sudo的区别
su是一个命令,可切换其他用户进行操作:而 '-' 号则是代表是否完全切换指定的用户环境信息 sudo是一个服务,可通过/etc/sudoers进行配置文件,让被限制的用户只能执行被授予的命令操作.