Flink SQL管理平台flink-streaming-platform-web安装搭建
文章都在个人博客网站:https://www.ikeguang.com/ 同步,欢迎访问。
最近看到有人在用flink sql的页面管理平台,大致看了下,尝试安装使用,比原生的flink sql界面确实好用多了,我们看下原生的,通过bin/sql-client.sh命令进入那个黑框,一只松鼠,对,就是那个界面。。。。
这个工具不是Flink官方出的,是一个国内的小伙伴写的,Github地址:
https://github.com/zhp8341/flink-streaming-platform-web
根据github上,作者的描述,flink-streaming-patform-web主要功能:
- [1] 任务支持单流 、双流、 单流与维表等。
- [2] 支持本地模式、yarn-per模式、STANDALONE模式 Application模式
- [3] 支持catalog、hive。
- [4] 支持自定义udf、连接器等,完全兼容官方连接器。
- [5] 支持sql的在线开发,语法提示,格式化。
- [6] 支持钉钉告警、自定义回调告警、自动拉起任务。
- [7] 支持自定义Jar提交任务。
- [8] 支持多版本flink版本(需要用户编译对应flink版本)。
- [9] 支持自动、手动savepoint备份,并且从savepoint恢复任务。
- [10] 支持批任务如:hive。
- [11] 连接器、udf等三jar管理
是不是觉得很强大,很多同学已经摩拳擦掌想试试了。
安装
这里只介绍flink on yarn模式的安装,如果你的hadoop集群已经安装好了,大概半个小时就能好;否则,安装hadoop集群可老费事儿了。总体步骤如下:
第一步 hadoop集群
这里假设你的hadoop集群是好的,yarn是可以正常使用的,8088端口可以访问,如下:
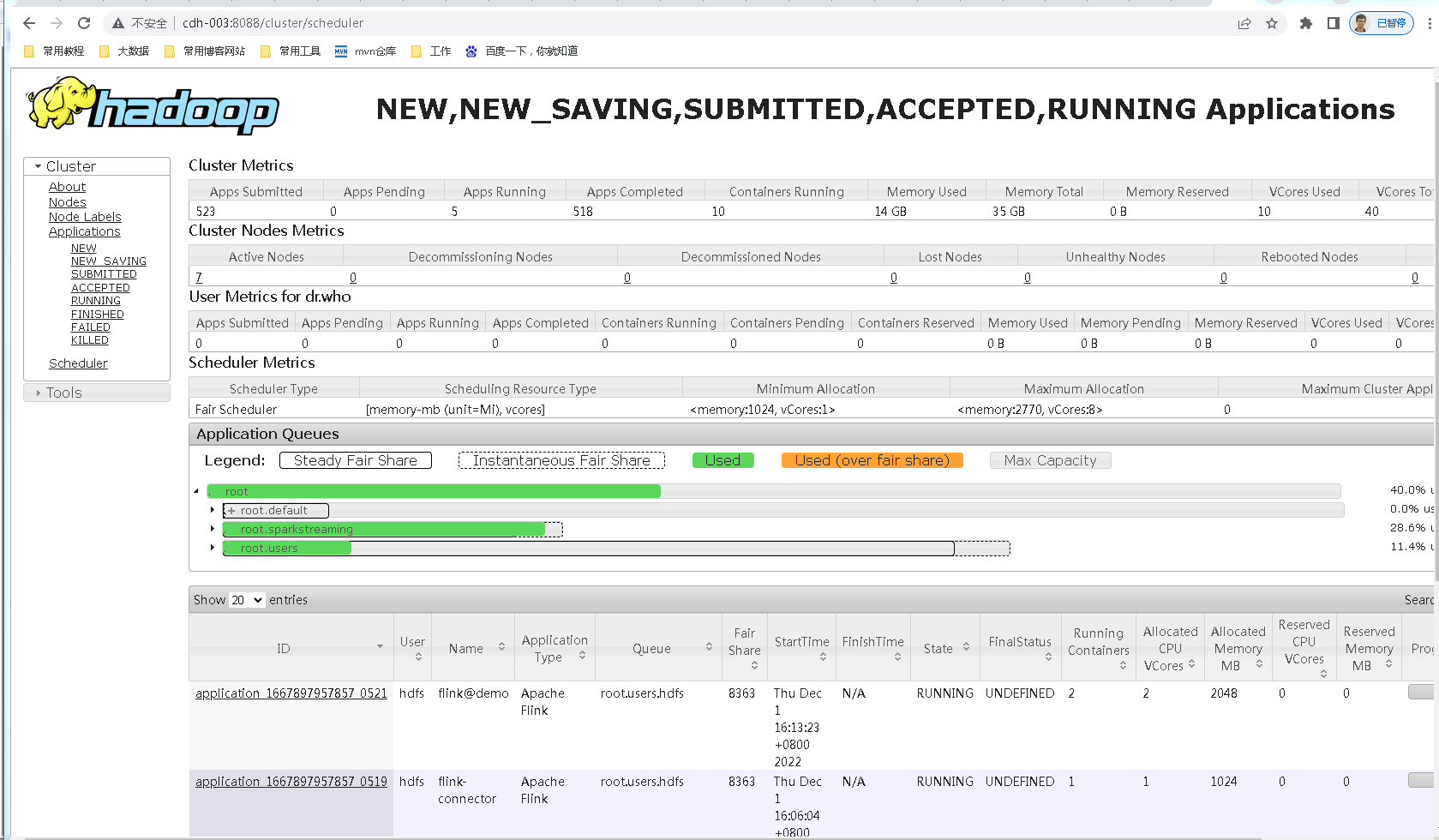
第二步 下载flink
flink on yarn,只需要下载一个flink安装包即可使用,下载命令:
http://archive.apache.org/dist/flink/flink-1.13.5/flink-1.13.5-bin-scala_2.11.tgz
解压
tar -xvf flink-1.13.5-bin-scala_2.11.tgz
关键:这里问题来了,我的flink怎么识别hadoop呢,需要配置一个环境变量,编辑 /etc/profile,键入内容:
export HADOOP_CONF_DIR=填你的hadoop配置文件目录,比如我的是/usr/local/hadoop2.8/etc/hadoop/conf
export HADOOP_CLASSPATH=`hadoop classpath`
好了,这样一个flink on yarn的环境就搭建好了。
第三步 安装flink-streaming-patform-web
官方地址文章开头已经给出,在github找到下载地址: https://github.com/zhp8341/flink-streaming-platform-web/releases/,我下载的版本是这个。
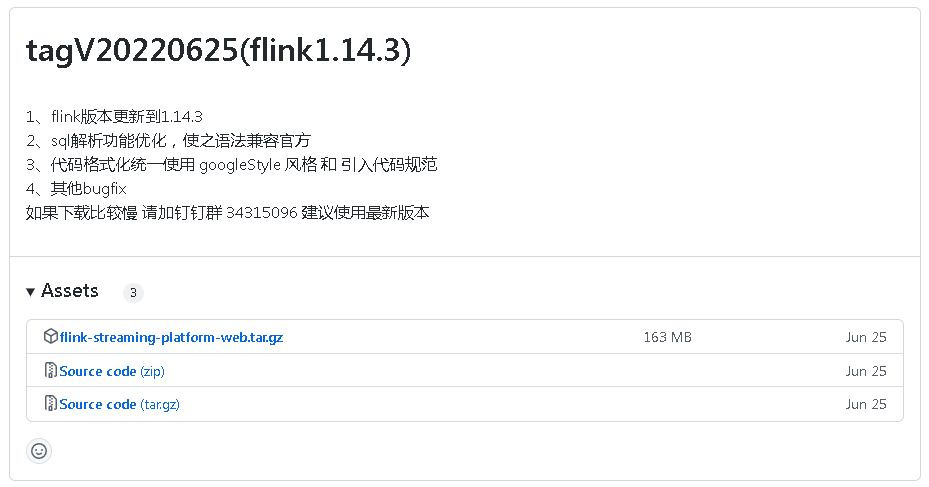
为什么我下的是适配flink 1.14.3的,我前面安装flink1.13.5,我也是下了一堆flink,经过尝试,才发现flink1.13.5这个版本,适配flink-streaming-platform-web tagV20220625。
解压后,修改配置文件:application.properties,懂的人知道这个其实是个springboot的配置文件。
#### jdbc信息
server.port=9084
spring.datasource.url=jdbc:mysql://192.168.1.1:3306/flink_web?serverTimezone=UTC&useUnicode=true&characterEncoding=utf-8&useSSL=false
spring.datasource.username=bigdata
spring.datasource.password=bigdata
这里配置了一个数据库,需要自己新建一下,建表语句作者给出了:https://github.com/zhp8341/flink-streaming-platform-web/blob/master/docs/sql/flink_web.sql,把这段sql执行一下,在flink_web数据库建相应的一些整个系统运行需要的表。
启动web服务
# bin目录下面的命令
启动 : sh deploy.sh start
停止 : sh deploy.sh stop
服务启动后,通过9084端口在浏览器访问

第四步 配置flink web平台
这一步很关键,页面上点击系统设置,进入配置页面:
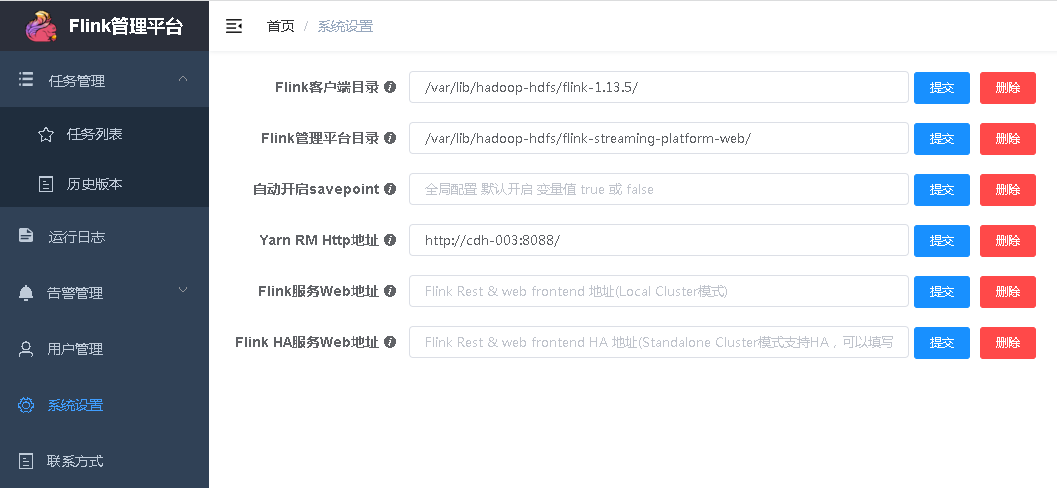
这里的参数意义:
- Flink客户端目录:就是安装的Flink目录;
- Flink管理平台目录:就是下载的flink-streaming-platform-web放的目录;
- yarn RM http地址:就是yarn.resourcemanager.webapp.address,通常是8088端口;
经过测试,配置这3个参数即可使用。
第五步 运行demo
这里以官方demo为例,[demo1 单流kafka写入mysqld 参考](https://github.com/zhp8341/flink-streaming-platform-web/blob/master/docs/sql_demo/demo_1.md),这是一个通过flink sql消费kafka,聚合结果写入mysql的例子。
- 在flink_web数据建表
CREATE TABLE sync_test_1 (
`day_time` varchar(64) NOT NULL,
`total_gmv` bigint(11) DEFAULT NULL,
PRIMARY KEY (`day_time`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
- 下载依赖jar包
因为涉及到kafka和mysql,需要对应的connector依赖jar包,下图中标注出来了,放在Flink的lib目录(/var/lib/hadoop-hdfs/flink-1.13.5/lib)下面:
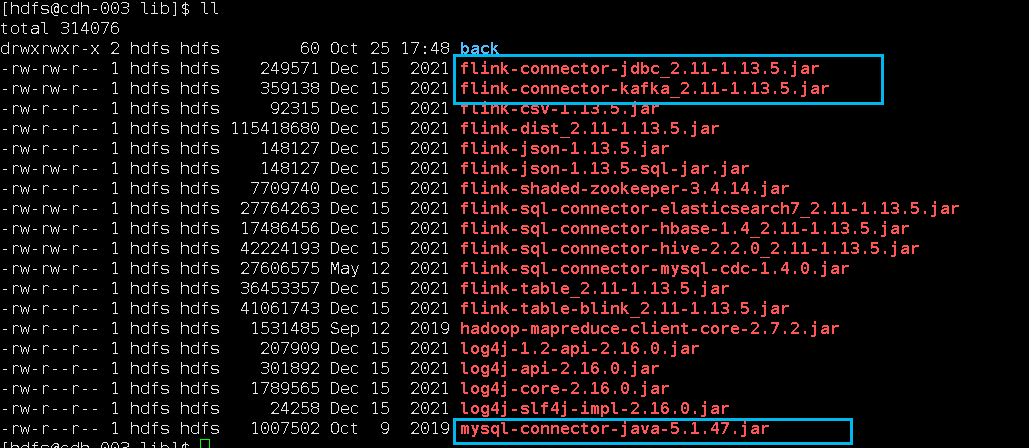
wget https://repo1.maven.org/maven2/org/apache/flink/flink-connector-jdbc_2.11/1.13.5/flink-connector-jdbc_2.11-1.13.5.jar
https://repo1.maven.org/maven2/org/apache/flink/flink-connector-kafka_2.11/1.13.5/flink-connector-kafka_2.11-1.13.5.jar
技巧:下载Flink的依赖jar包,有个地方下载很方便,地址是:
https://repo1.maven.org/maven2/org/apache/flink/
这样依赖,一切都准备好了。
在web页面新建sql流任务:
我建的一个,任务属性我是这样填写的:
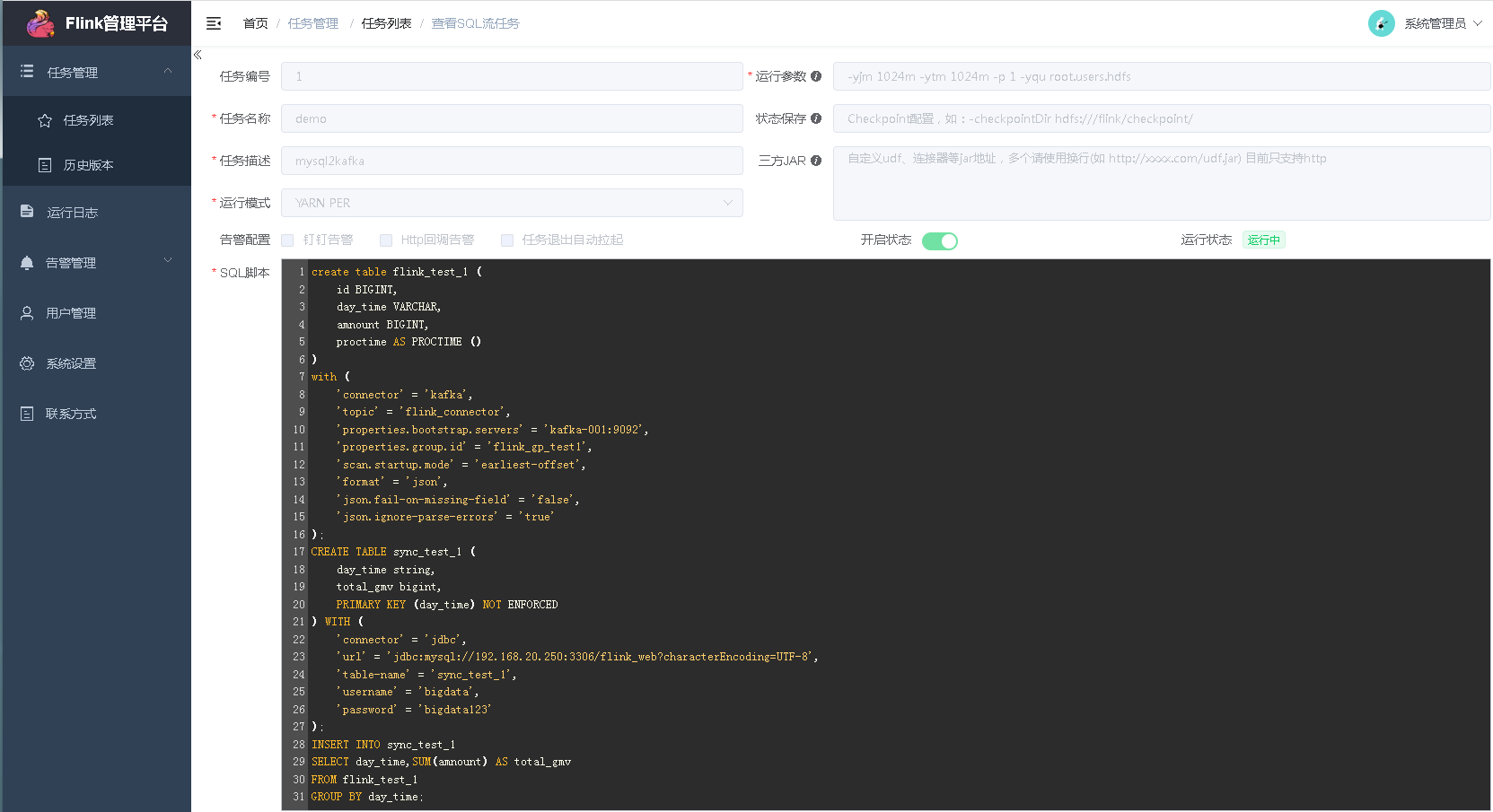
sql脚本内容:
create table flink_test_1 (
id BIGINT,
day_time VARCHAR,
amnount BIGINT,
proctime AS PROCTIME ()
)
with (
'connector' = 'kafka',
'topic' = 'flink_connector',
'properties.bootstrap.servers' = 'kafka-001:9092',
'properties.group.id' = 'flink_gp_test1',
'scan.startup.mode' = 'earliest-offset',
'format' = 'json',
'json.fail-on-missing-field' = 'false',
'json.ignore-parse-errors' = 'true'
);
CREATE TABLE sync_test_1 (
day_time string,
total_gmv bigint,
PRIMARY KEY (day_time) NOT ENFORCED
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://192.168.1.1:3306/flink_web?characterEncoding=UTF-8',
'table-name' = 'sync_test_1',
'username' = 'bigdata',
'password' = 'bigdata'
);
INSERT INTO sync_test_1
SELECT day_time,SUM(amnount) AS total_gmv
FROM flink_test_1
GROUP BY day_time;
创建好任务后,启动任务吧。
启动后,可以在yarn的8088端口页面看到起了一个application,名称是新建任务填写的名称加flink@前缀:
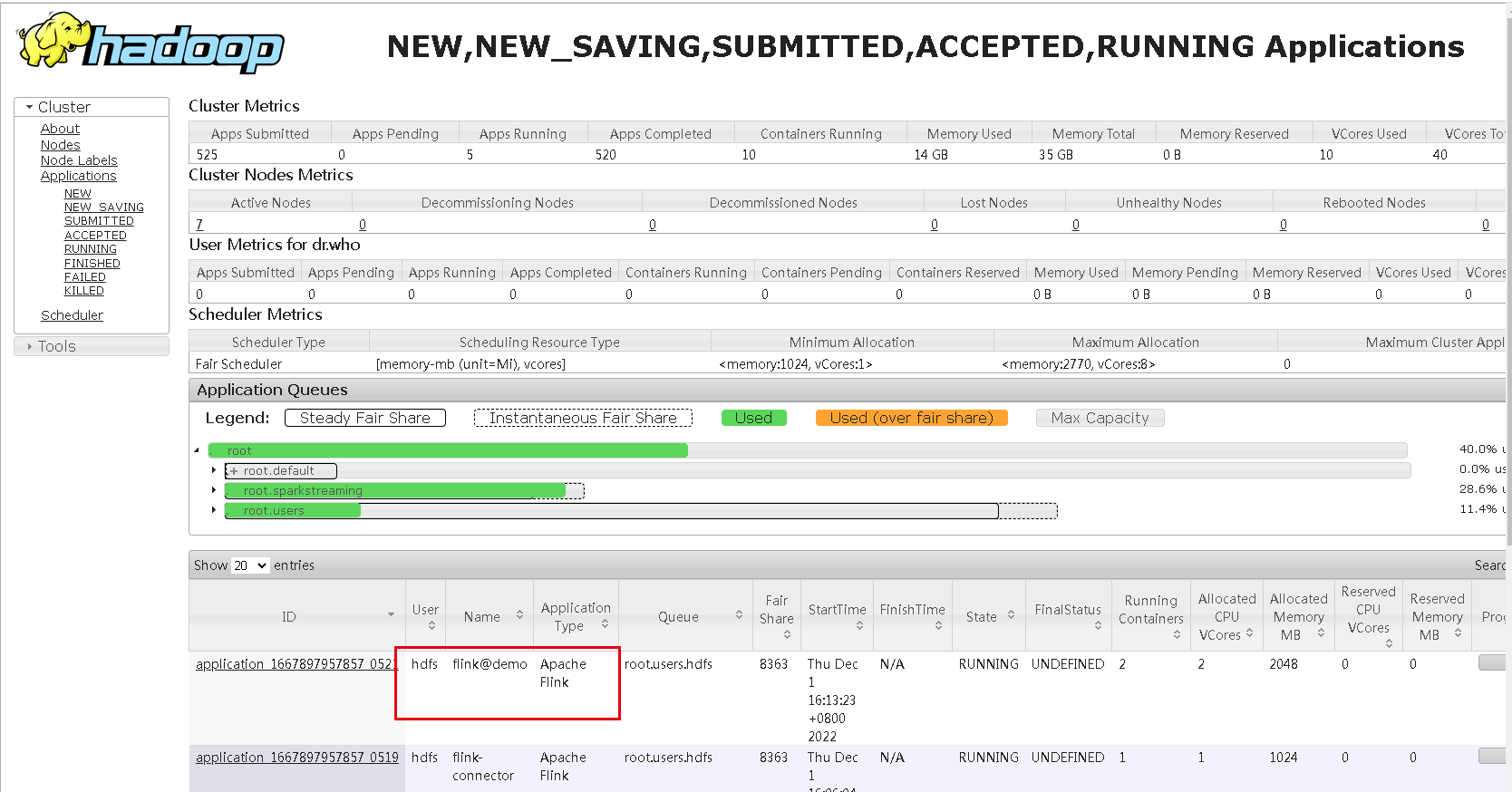
这个任务,我们点进去看,通过管理平台提交的sql任务确实跑起来了,这个页面了解Flink的同学就很熟悉了:

其实,这段sql脚本,我们可以在flink的bin/sql-client.sh进入的那个小松鼠的黑框里面执行的,你们可以试一下。

kafka控制台往主题里面写数据,主题不存在会自动创建:

我们再看看mysql里面:
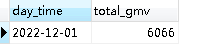
数据已经进来了。
与Flink SQL的比较
我们可以看到,flink-streaming-platform-web这个工具只是让我们不需要在这个黑框里面写sql了,而是在网页上面写sql,系统会把写的sql进行校验给flink去执行,不管是flink-streaming-platform-web网页也好,还是那个黑框sql控制台,都是客户端,本质上都是flink提供的一些table api去执行任务。
Flink SQL管理平台flink-streaming-platform-web安装搭建的更多相关文章
- 从零构建Flink SQL计算平台 - 1平台搭建
一.理想与现实 Apache Flink 是一个分布式流批一体化的开源平台.Flink 的核心是一个提供数据分发.通信以及自动容错的流计算引擎.Flink 在流计算之上构建批处理,并且原生的支持迭代计 ...
- 【青橙商城-管理后台开发】3. web模块搭建
[青橙商城-管理后台开发]3. web模块搭建 1.创建qingcheng_web_manager模块 pom.xml <?xml version="1.0" encodin ...
- Dubbo-Admin管理平台和Zookeeper注册中心的搭建(转)
林炳文Evankaka原创作品.转载请注明出处http://blog.csdn.net/evankaka ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubb ...
- Dubbo-Admin管理平台和Zookeeper注册中心的搭建(只支持jdk7)
林炳文Evankaka原创作品.转载请注明出处http://blog.csdn.net/evankaka ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubb ...
- Dubbo学习总结(3)——Dubbo-Admin管理平台和Zookeeper注册中心的搭建
ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件.它是一个为分布式应用提供一致性服务的软件,提供的功 ...
- 8、Flink Table API & Flink Sql API
一.概述 上图是flink的分层模型,Table API 和 SQL 处于最顶端,是 Flink 提供的高级 API 操作.Flink SQL 是 Flink 实时计算为简化计算模型,降低用户使用实时 ...
- [源码分析] 带你梳理 Flink SQL / Table API内部执行流程
[源码分析] 带你梳理 Flink SQL / Table API内部执行流程 目录 [源码分析] 带你梳理 Flink SQL / Table API内部执行流程 0x00 摘要 0x01 Apac ...
- Flink SQL项目实录
一.Flink SQL层级 为Flink最高层的API,易于使用,所以应用更加广泛,eg. ETL.统计分析.实时报表.实时风控等. Flink SQL所处的层级: 二.Flink聚合: 1.Wind ...
- kvm虚拟化管理平台WebVirtMgr部署-完整记录(1)
公司机房有一台2U的服务器(64G内存,32核),由于近期新增业务比较多,测试机也要新增,服务器资源十分有限.所以打算在这台2U服务器上部署kvm虚拟化,虚出多台VM出来,以应对新的测试需求.当KVM ...
- (转)Centos下,Docker部署Yapi接口管理平台
接口测试的工具很多,公司引进了接口管理平台Yapi,自己尝试直接搭建,从安装Nodejs到配置MongoDB数据库,再到安装yapi的时候,遇到浏览器打开本地服务器Ip地址后,没有显示部署内容...没 ...
随机推荐
- js工厂模式和构造函数
<!DOCTYPE html><html><head> <title>工厂模式和构造函数</title> <meta charset ...
- Spring 后置处理器【1】
Spring 后置处理器[1] 简单介绍 一句话:bean 在初始化前或初始化后的瞬间,我自己添加一些业务逻辑 bean 后置处理器类的内容 简单代码 package com.hspedu.sprin ...
- 回滚Deployment控制器下的应⽤发布
若因各种原因导致滚动更新⽆法正常进⾏,如镜像⽂件获取失败."⾦丝雀"遇险等,则应该将应⽤回滚到之前的版本,或者回滚到由⽤户指定的历史记录中的版本. Deployment控制器的回滚 ...
- LINUX 新增的磁盘不建立分区,直接建立文件系统并挂载
假设新硬盘是 /dev/sdc fdisk操作的是/dev/sdc ,分区后才会有/dev/sdc1 /dev/sdc2 之类 一般mkfs.ext4 /dev/sdc1 来格式化一个分区,再moun ...
- 面试突击86:SpringBoot 事务不回滚?怎么解决?
在 Spring Boot 中,造成事务不自动回滚的场景有很多,比如以下这些: 非 public 修饰的方法中的事务不自动回滚: 当 @Transactional 遇上 try/catch 事务不自动 ...
- SQL日期查询语句
--查询当天(1: select * from ShopOrder where datediff(day,ordTime,getdate()-1)=0 --查询当天(2:select * from i ...
- 线上服务宕机,码农试用期被毕业,原因竟是给MySQL加个字段
1. 问题:怎么给线上表加字段? 工作中最常遇到的问题,怎么给线上频繁使用的大表添加字段? 比如:给下面的用户表(user)添加年龄(age)字段. CREATE TABLE `user` ( `id ...
- 云的安全组和网络ACL
云的安全组和网络ACL 1.流量控制: 安全组是云服务器.数据库等实例级别的流量控制 ACL是子网级别的流量控制 2.规则: 安全组和网络ACL都支持允许规则和拒绝规则 3.状态: 安全组有状态( ...
- get,post,put,delete四种基础方法对应增删改查
PUT,DELETE,POST,GET四种基础方法对应增删改查 1.GET请求会向数据库发索取数据的请求,从而来获取信息,该请求就像数据库的select操作一样,只是用来查询一下数据,不会修改.增加数 ...
- Java I/O(3):NIO中的Buffer
您好,我是湘王,这是我的博客园,欢迎您来,欢迎您再来- 之前在调用Channel的代码中,使用了一个名叫ByteBuffer类,它是Buffer的子类.这个叫Buffer的类是专门用来解决高速设备与低 ...