elasticsearch中使用bucket script进行聚合
1、背景
此篇文档简单的记录一下在es使用bucket script来进行聚合的一个例子。
2、需求
假设我们有一个简单的卖车数据,记录每个月month在卖了brand品牌的车salesVolume的数量。
此处我们需要聚合出 每个月brand=宝马的车在每个月的销售占比
3、准备数据
3.1 mapping
PUT /index_bucket_script
{
"mappings": {
"properties": {
"month": {
"type": "keyword"
},
"brand": {
"type": "keyword"
},
"salesVolume": {
"type": "integer"
}
}
}
}
3.2 插入数据
PUT /index_bucket_script/_bulk
{"index":{"_id":1}}
{"month":"2023-01","brand":"宝马","salesVolume":100}
{"index":{"_id":3}}
{"month":"2023-02","brand":"大众","salesVolume":80}
{"index":{"_id":4}}
{"month":"2023-02","brand":"宝马","salesVolume":20}
注意: 此处2023-02月份的数据插入了2个品牌的数据。
4、bucket_script聚合的语法

5、聚合
5.1 根据月份分组排序
GET index_bucket_script/_search
{
"query": {
"match_all": {}
},
"size": 0,
"aggs": {
"根据月份分组": {
"terms": {
"field": "month",
"order": {
"_key": "asc"
}
}
}
}
}
5.2 统计每个月卖了多少辆车
GET index_bucket_script/_search
{
"query": {
"match_all": {}
},
"size": 0,
"aggs": {
"根据月份分组": {
"terms": {
"field": "month",
"order": {
"_key": "asc"
}
},
"aggs": {
"统计每个月卖了多少辆车": {
"sum": {
"field": "salesVolume"
}
}
}
}
}
}
5.3 统计每个月卖了多少宝马车
GET index_bucket_script/_search
{
"query": {
"match_all": {}
},
"size": 0,
"aggs": {
"根据月份分组": {
"terms": {
"field": "month",
"order": {
"_key": "asc"
}
},
"aggs": {
"统计每个月卖了多少辆车": {
"sum": {
"field": "salesVolume"
}
},
"统计每个月卖了多少宝马车": {
"filter": {
"term": {
"brand": "宝马"
}
},
"aggs": {
"每个月卖出的宝马车辆数": {
"sum": {
"field": "salesVolume"
}
}
}
}
}
}
}
}
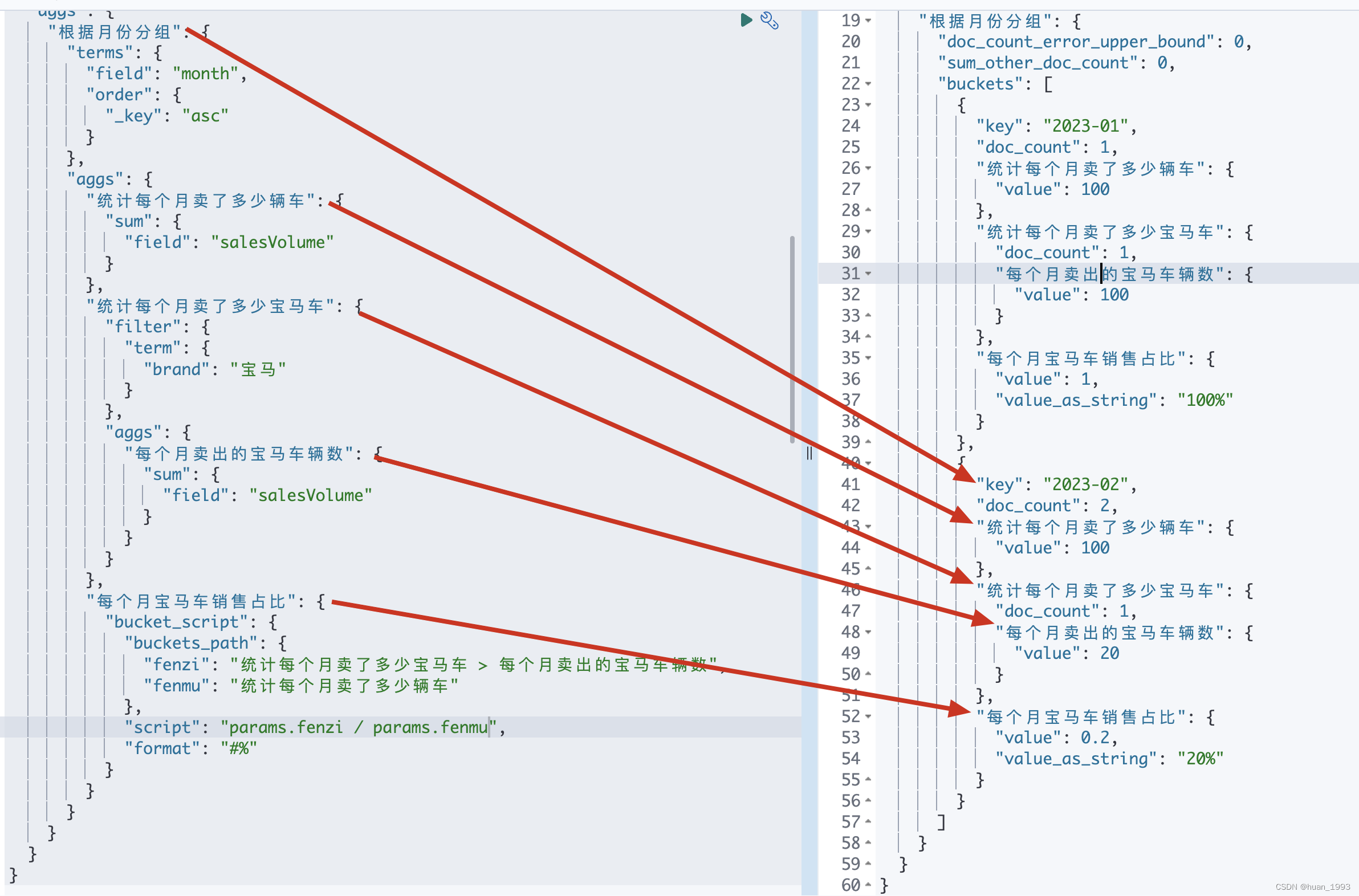
5.4 每个月宝马车销售占比
5.4.1 dsl
GET index_bucket_script/_search
{
"query": {
"match_all": {}
},
"size": 0,
"aggs": {
"根据月份分组": {
"terms": {
"field": "month",
"order": {
"_key": "asc"
}
},
"aggs": {
"统计每个月卖了多少辆车": {
"sum": {
"field": "salesVolume"
}
},
"统计每个月卖了多少宝马车": {
"filter": {
"term": {
"brand": "宝马"
}
},
"aggs": {
"每个月卖出的宝马车辆数": {
"sum": {
"field": "salesVolume"
}
}
}
},
"每个月宝马车销售占比": {
"bucket_script": {
"buckets_path": {
"fenzi": "统计每个月卖了多少宝马车 > 每个月卖出的宝马车辆数",
"fenmu": "统计每个月卖了多少辆车"
},
"script": "params.fenzi / params.fenmu * 100"
}
}
}
}
}
}
5.4.2 java
@Test
@DisplayName("统计宝马车每个月销售率")
public void test01() throws IOException {
SearchRequest request = SearchRequest.of(searchRequest ->
searchRequest.index(INDEX_PERSON)
.query(query -> query.matchAll(matchAll -> matchAll))
.size(0)
.aggregations("根据月份分组", monthAggr ->
monthAggr.terms(terms -> terms.field("month").order(
NamedValue.of("_key", SortOrder.Asc)
))
.aggregations("统计每个月卖了多少辆车", agg1 ->
agg1.sum(sum -> sum.field("salesVolume"))
)
.aggregations("统计每个月卖了多少宝马车", agg2 ->
agg2.filter(filter -> filter.term(term -> term.field("brand").value("宝马")))
.aggregations("每个月卖出的宝马车辆数", agg3 ->
agg3.sum(sum -> sum.field("salesVolume"))
)
)
.aggregations("每个月宝马车销售占比", rateAggr ->
rateAggr.bucketScript(bucketScript ->
bucketScript.bucketsPath(path ->
path.dict(
new HashMap<String, String>() {
{
put("fenzi", "统计每个月卖了多少宝马车>每个月卖出的宝马车辆数");
put("fenmu", "统计每个月卖了多少辆车");
}
}
)
)
.script(script ->
script.inline(inline -> inline.source("params.fenzi/params.fenmu"))
)
.format("#%")
)
)
)
);
System.out.println("request: " + request);
SearchResponse<String> response = client.search(request, String.class);
System.out.println("response: " + response);
}
5.4.3 运行结果
5、完整代码
6、参考文档
1、https://www.elastic.co/guide/en/elasticsearch/reference/current/search-aggregations-pipeline.html#buckets-path-syntax
2、https://www.elastic.co/guide/en/elasticsearch/reference/current/search-aggregations-pipeline-bucket-script-aggregation.html
3、https://docs.oracle.com/en/java/javase/17/docs/api/java.base/java/text/DecimalFormat.html
elasticsearch中使用bucket script进行聚合的更多相关文章
- Elasticsearch 中映射参数doc_values 和 fielddata分析比较
doc_values 默认情况下,大部分字段是索引的,这样让这些字段可被搜索.倒排索引(inverted index)允许查询请求在词项列表中查找搜索项(search term),并立即获得包含该词项 ...
- Elasticsearch使用系列-基本查询和聚合查询+sql插件
Elasticsearch使用系列-ES简介和环境搭建 Elasticsearch使用系列-ES增删查改基本操作+ik分词 Elasticsearch使用系列-基本查询和聚合查询+sql插件 Elas ...
- ES 15 - Elasticsearch中的数据类型 (text、keyword、date、geo等)
目录 1 核心数据类型 1.1 字符串类型 - string(不再支持) 1.1.1 文本类型 - text 1.1.2 关键字类型 - keyword 1.2 数字类型 - 8种 1.3 日期类型 ...
- ElasticSearch中倒排索引和正向索引
ElasticSearch搜索使用的是倒排索引,但是排序.聚合等不适合倒排索引使用的是正向索引 倒排索引 倒排索引表以字或词为关键字进行索引,表中关键字所对应的记录项记录了出现这个字或词的所有文档,每 ...
- ElasticSearch中的sort排序和filedData作用
默认情况下,ElasticSearch 会根据算分进行排序: 可以使用 sort API 指定排序的规则: POST /kibana_sample_data_ecommerce/_search { & ...
- Elasticsearch中最重要的文档CRUD要牢记
Elasticsearch文档CRUD要牢记 转载参考:https://juejin.im/post/5ddbf298e51d4523053c42e7 在Elasticsearch中,文档(docum ...
- Elasticsearch 中为什么选择倒排索引而不选择 B 树索引
目录 前言 为什么全文索引不使用 B+ 树进行存储 全文检索 正排索引 倒排索引 倒排索引如何存储数据 FOR 压缩 RBM 压缩 倒排索引如何存储 字典树(Tria Tree) FST FSM 构建 ...
- Elasticsearch中的一些重要概念:cluster, node, index, document, shards及replica
首先,我们来看下一下如下的这个图: Cluster Cluster也就是集群的意思.Elasticsearch集群由一个或多个节点组成,可通过其集群名称进行标识.通常这个Cluster 的名字是可以在 ...
- 如何在Elasticsearch中安装中文分词器(IK+pinyin)
如果直接使用Elasticsearch的朋友在处理中文内容的搜索时,肯定会遇到很尴尬的问题--中文词语被分成了一个一个的汉字,当用Kibana作图的时候,按照term来分组,结果一个汉字被分成了一组. ...
- elasticsearch中常用的API
elasticsearch中常用的API分类如下: 文档API: 提供对文档的增删改查操作 搜索API: 提供对文档进行某个字段的查询 索引API: 提供对索引进行操作,查看索引信息等 查看API: ...
随机推荐
- python进阶(26)collections标准库
前言 这个模块实现了特定目标的容器,以提供Python标准内建容器dict ,list ,set , 和tuple 的替代选择. 这个模块提供了以下几个函数 函数 作用 namedtuple() 创建 ...
- (译)TDD(测试驱动开发)的5个步骤
原文:5 steps of test-driven development https://developer.ibm.com/articles/5-steps-of-test-driven-deve ...
- 自学 TypeScript 第二天 编译选项
前言: 昨天我们学习了 TS 的数据类型,不知道大家回去以后练习没练习,如果你练习了一定会发现一个问题,我们的 TS 好像和 JS 不太一样 JS 写完之后直接就可以放到页面上,就可以用了,而我们的 ...
- mindxdl---common--test_tools.go
// Copyright (c) 2021. Huawei Technologies Co., Ltd. All rights reserved.// Package common define co ...
- hashlib加密模块、加密补充说明、subprocess模块、logging日志模块
目录 hashlib加密模块 加密补充说明 subprocess模块 logging日志模块 日志的组成 日志配置字典 hashlib加密模块 1.何为加密 将明文数据处理成密文数据 让人无法看懂 2 ...
- 关于Linux pyinstaller打包zmq.h报错
报错信息 6:10: fatal error: zmq.h: No such file or directory #include <zmq.h> ^~~~~~~ compilation ...
- 文件服务器 — File Browser
前言 一直想部署一套文件服务器,供队友之间相互传输文件.平时用微信发送文件真的太烦了,每发送或者接收一次都会有一个新的文件,造成重复文件太多了.文件服务器统一管理,自己需要什么文件再下载. 前面也安装 ...
- Task02:艺术画笔见乾坤
Matplotlib的三层api(应用程序编程接口) matplotlib.backend_bases.FigureCanvas:绘图区 matplotlib.backend_bases.Render ...
- 【Shell案例】【awk匹配、grep查找文件内的字符串】6、去掉空行(删除空行)
描述写一个 bash脚本以去掉一个文本文件 nowcoder.txt中的空行示例:假设 nowcoder.txt 内容如下:abc 567 aaabbb ccc 你的脚本应当输出:abc567aaab ...
- 【Java EE】Day12 XML、约束(DTD、Schema)、解析方式、Jsoup、选择器(Selector、XPath)
一.XML介绍 1.概述 Extensible Markup Language--可扩展标记语言 标记语言 :标签构成 可扩展:可以自定义标签 2.功能 存储数据 作为配置文件使用 作为数据载体在网络 ...