vivo前端智能化实践:机器学习在自动网页布局中的应用
作者:vivo 互联网前端团队- Su Ning
在设计稿转网页中运用基于self-attention机制设计的机器学习模型进行设计稿的布局,能够结合dom节点的上下文得出合理的方案。
一、背景
切图作为前端的传统手艺却是大多数前端开发者都不愿面对的工作。
为了解决切图的各种问题,人们绞尽脑汁开发了各种各样的设计稿转代码(D2C)工具,这些D2C工具随着设计师使用的软件的变更又在不断地迭代。
从Photoshop时代,前端需要手动标记节点进行单独的样式导出(如图1),到sketch measure,可以整体页面输出(如图2),其效率、结果都已经有了一个质的提升。
但是还是未能彻底解决切图的问题,因为设计稿所包含的信息只负责输出样式,而没有办法输出网页布局,我们还是没有办法直接copy生成的代码到我们的项目中直接使用。
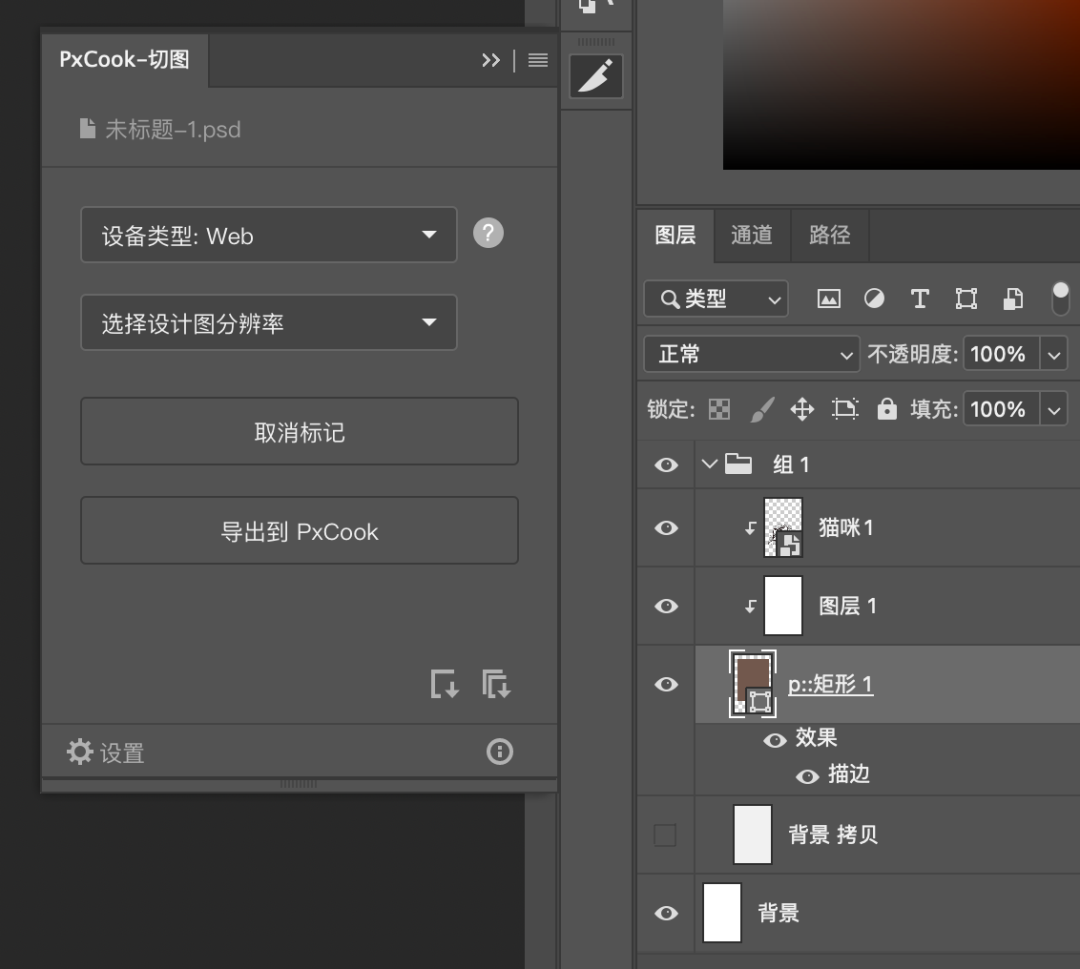
图1
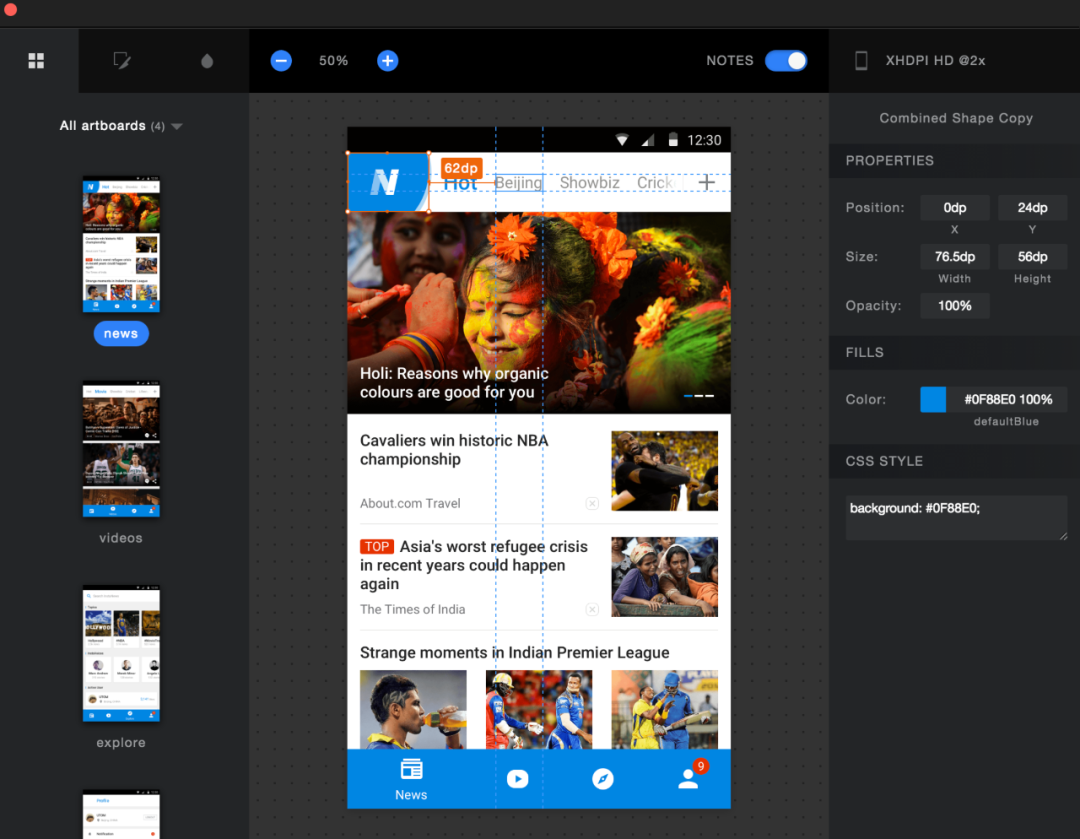
图2
在学习现有的D2C案例的过程中,我们发现很多成熟的方案中引用了机器学习辅助代码的生成,其中绝大多数的工作是用于视觉识别和语义识别,于是我们想,机器学习是否能够应用到网页的布局中呢?
为了验证我们的猜想,也为了解决我们工作中的实际痛点,我们决定自己开发一个D2C工具,希望能够通过机器帮我们实现网页布局的过程,整体工作流程大致如图3,首先获取设计稿的元数据,然后对设计稿的数据进行一系列的处理导出自由的dsl,然后根据这个dsl生成相应端的代码。
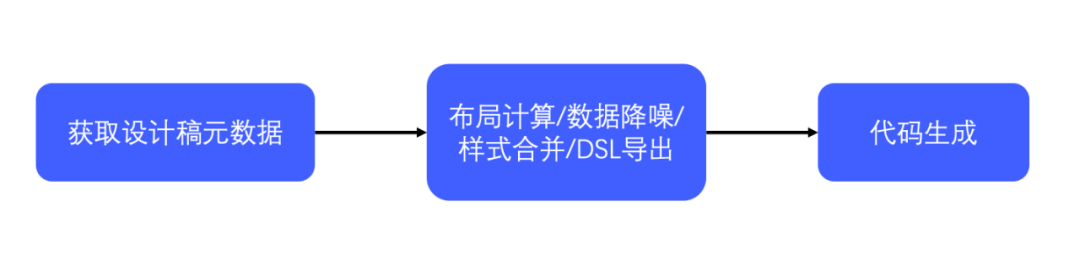
图3
二、页面布局
要处理网页的布局需要解决两个问题,节点的父子关系以及节点之间的位置关系。
2.1 节点的父子关系
节点的父子关系指的是一个节点包含了哪些子节点,又被哪个节点所包含。这部分的内容可以直接使用规则处理,通过节点的顶点位置和中心点的位置信息判断一个节点是否是另一个节点的子节点。这里我们就不展开讨论了。
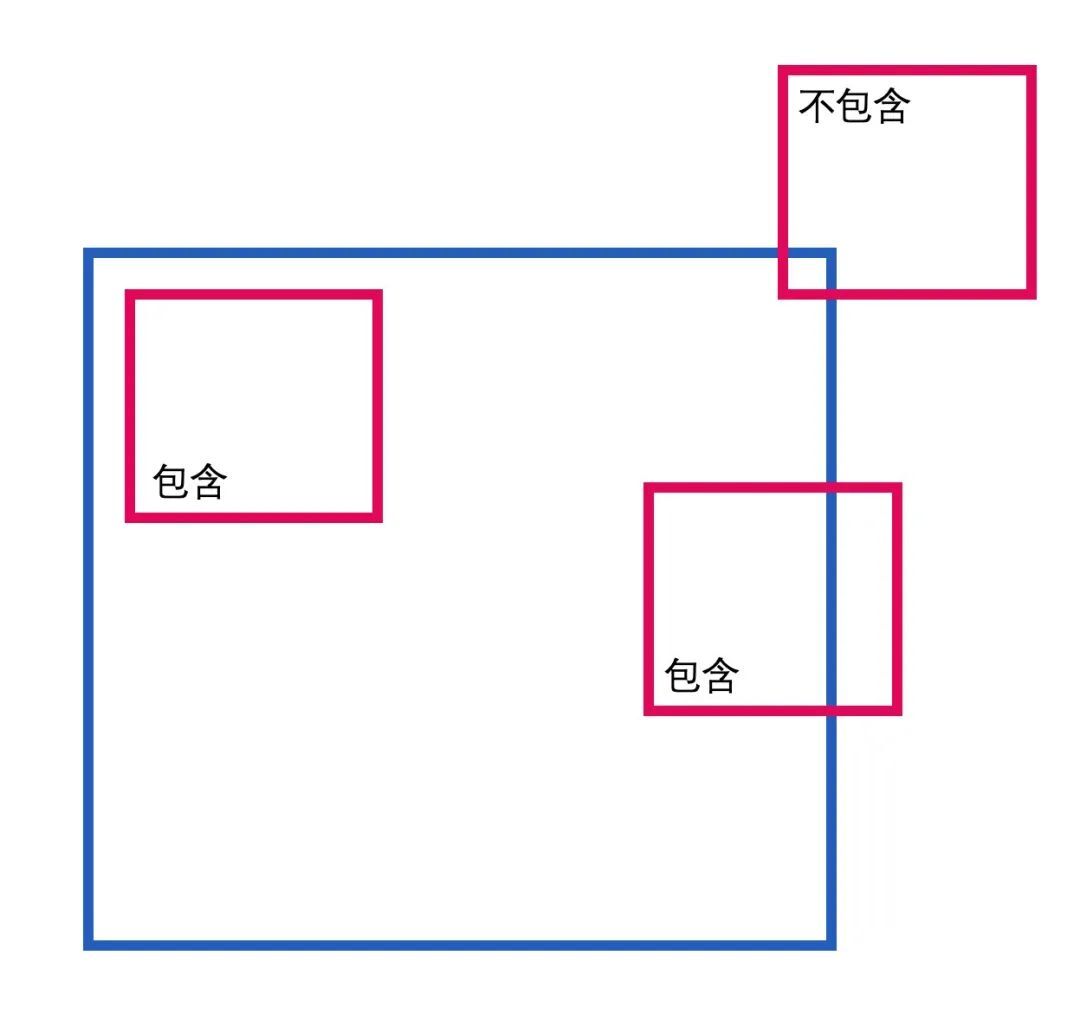
同一层级节点之间的位置关系,才是我们这次着重需要解决的问题。
2.2 节点之间的位置关系
网页的布局有很多种,线性布局,流式布局,网格布局,还有随意定位的绝对定位等等,而我们在导出样式的时候,无非需要确认两件事情,节点的定位方式(relative、absolute、fixed)和节点的布局方向(纵向、横向)。
线性布局

流式布局

网格布局
按照*时切图的习惯,我们会首先识别一组*级节点之间有没有明显的上下或者左右的位置关系,然后将他们放入到网格中,最后独立在这些节点外面的节点就是绝对定位。
让机器识别节点之间的位置关系,就成了解决问题的关键一环。

判断节点之间的位置关系只需要节点的位置和宽高信息,因此我们的输入数据设计如下:
[
{
width:200,
height:50,
x:0,
y:0
},
{
width:200,
height:100,
x:0,
y:60
},
{
width:200,
height:100,
x:210,
y:60
}
]同时我们希望获得的输出结果是每一个节点是上下排列,左右排列,还是绝对定位的,输出的数据设计如下:
[
{
layout:'col'
},
{
layout:'row'
},
{
layout:'absolute'
}
]起初我们是希望通过书写一定的规则进行布局的判断,通过判断前后两个节点的位置关系是上下还是左右来进行布局,然而这样只关注两个节点位置关系的规则却很难判断绝对定位的节点,并且固定的规则总是不够灵活。于是我们想到了善于处理分类问题的机器学习。
很显然通过大量数据训练的机器学习模型可以很好的模仿我们*时切图的习惯,在处理各种边缘场景的时候也能够更加的灵活。只要进行合理的模型设计,就可以辅助我们进行布局的处理。
三、为什么是self-attention?
从上文我们可以看出,我们需要训练一个模型,输入一个节点的列表,输出一个节点的布局信息,是不是有点像文本识别里面的词性翻译呢?
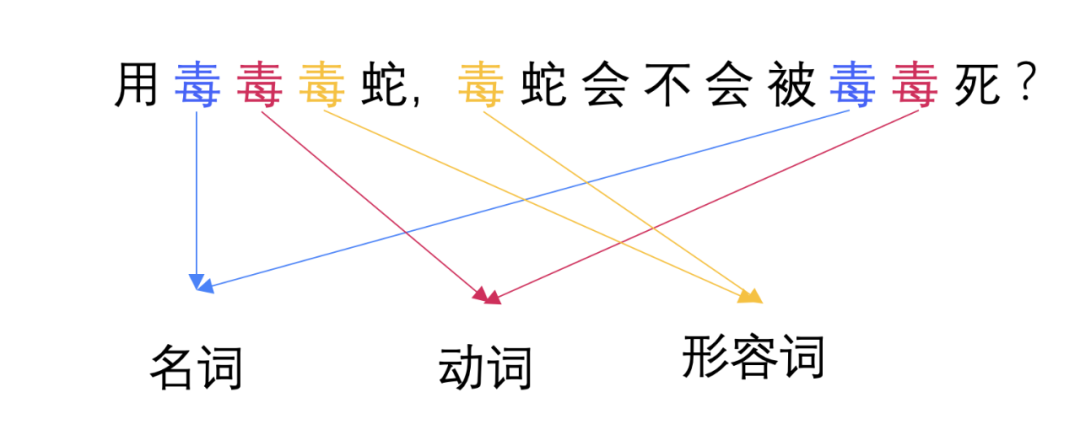
对于具体的一个节点,我们是没有办法判断其真正的布局的,只有将其放到文档流中结合上下文来看才能体现出其实际的意义。
在处理词性标记这块,RNN(循环神经网络)、LSTM(长短期记忆网络)都比较合适此类场景,RNN作为经典的神经网络模型通过将前一次训练的权重带入到下一次训练中建立上下文的关联,LSTM作为RNN的一种变体解决了RNN难以解决的长期依赖问题,用来训练网页布局看起来是一个不错的选择。
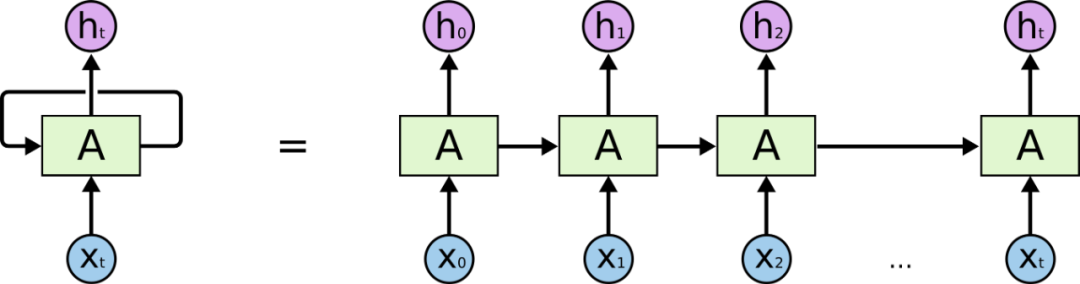
RNN(循环神经网络)
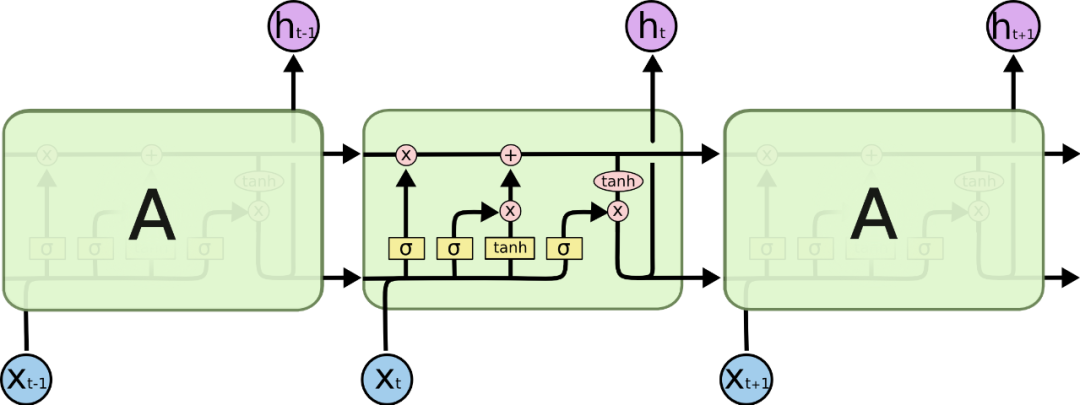
665px LSTM(长短期记忆网络)
使用LSTM的确可以解决我们的问题,但是由于此类神经网络对于时序的依赖导致上下文的数据没有办法进行并行运算,这使得我们的计算机没有办法更高效的训练模型,并且网页布局只需要获取不同节点的定位信息,对于装载的顺序并没有强要求。
随着2017年的一篇文章《Attention is All you Need》的横空出世,整个机器学习领域迎来了新一轮的革命,目前最主流的框架transformer、BERT、GPT全是在attention的基础上发展起来的。
self-attention自注意力机制是attention机制的变体,通过全局关联权重得出单个向量在全局中的加权信息,因为每一个节点都采用相同的运算方式,所以同一个序列中的节点可以同时进行上下文计算,极大地提升了模型训练的效率,也更方便我们优化和回归模型。
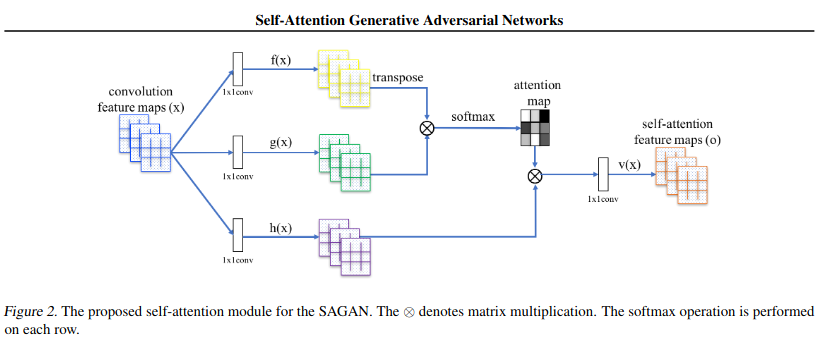
self-attention
综上,考虑到attention对于上下文更好的关联和更好的并行性能,我们决定基于此进行建模。
四、模型设计
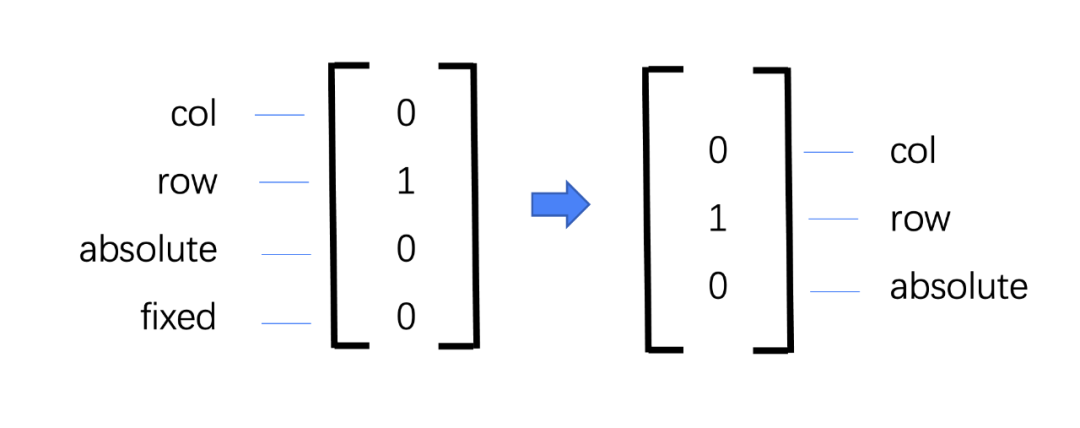
我们起初设计了一个输出的向量用于识别数据处理的结果,[1,0,0,0]代表是正常的竖向排列,[0,1,0,0]代表了横向排列,以此类推依次代表了absolute和fixed定位方式,但是后来我们发现fixed由于是相对于整个页面的定位方式,所以在单一层级下很难做标记,所以我们将输出值精简成了竖向排列,横向排列和绝对定位三种情况。
模型的整体设计如下,通过self-attention将节点转化为上下文信息,再通过前馈神经网络将上下文信息训练成具体的布局。
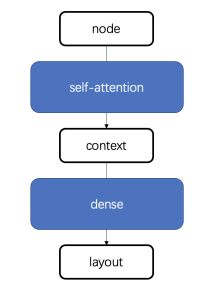
(1)在获取到一组数据后,为了去掉数值的大小的影响,我们首先对数据进行一次归一处理,将输入数据的每一个值分别除以这一组数据中的最大值。
(2)将每一组数据分别进行三次线性变换, 得到每组数据相应的Q,K,V,接下来我们就可以进行self-attention运算了。
(3)我们以node1为例,如果需要计算node1和其他节点的相关性,则需要使用Q1分别和每一个节点的key进行点积操作,将他们的和与V1相乘,为了防止权重值相乘以后过大,最后进行一次softmax计算,就得到了node1和其他节点的上下文信息。
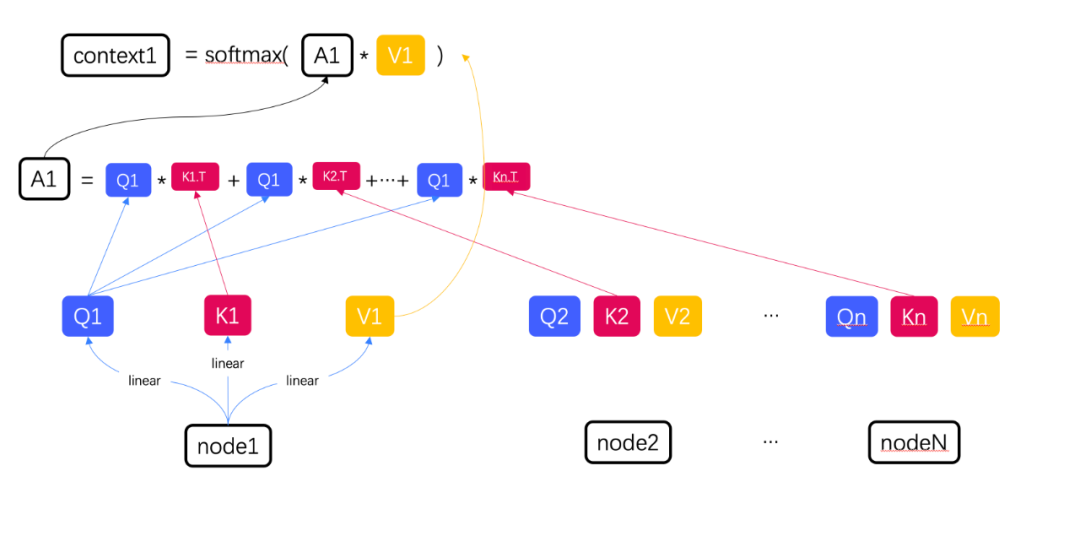
我们将一组数据中所有QKV看成三个矩阵,得到的上下文context的集合就可以看成一个矩阵计算。
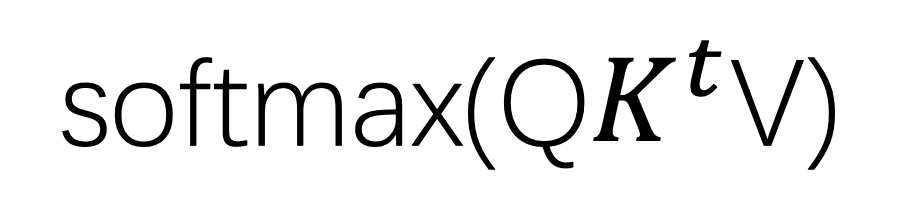
(4)为了提升训练的效果,每个节点的上下文信息输入到前馈神经网络进行最后的布局结果的训练,将得到的结果进行softmax计算就可以得到单个节点在一组数据中布局的概率分布了,由于同一组节点的运算没有前后顺序,故单个节点的运算可以同时进行,配合GPU加速极大地提升了训练的效率。
五、数据准备
由于机器学习需要海量的数据,数据的数量和质量都会极大地影响模型最终的训练效果,所以数据的数量和质量都非常重要,我们采用了三种数据源用于数据的训练,分别是标记过的设计稿,抓取的真实网页数据,以及自动生成的数据。
5.1 设计稿的标记
在获取到设计稿数据以后只取每个节点的定位和宽高数据,通过上文的父子关系处理后获取每一层的节点数据,为了防止出现过拟合的情况我们去掉节点数量相对较少的层级,并对每一层的布局进行手动标记。设计稿标记数据是质量最好,但也是最费时费力的工作,所以需要其他的数据源进行数量的补充。
5.2 真实网页的抓取
作为标记设计稿的补充,网页中的真实数据也是可靠的数据源,但是抓取网页的过程中最大的难点在于判断页面中的节点属于横向还是纵向。
由于实现横向排列的方式千奇百怪,可以通过float,inline-block,flex等等方法,我们如果只获取网页中节点的定位和宽高信息,还是需要手动标记他的布局,所以还是要从节点的css入手,在批量获取之后进行手动筛选,去掉低质量的数据。相对于标记的设计稿是一个有效的补充。
5.3 网页生成器
为了更快的生成大量的数据,我们写了一个网页生成的算法,在一开始就决定节点的定位方式,然后将节点渲染成网页,最后在抓取节点的定位信息,但是随机生成的数据存在一些不稳定的边界场景,譬如生成的绝对定位的节点会正好定位到横向布局的右边。这时就需要手动进行甄别。
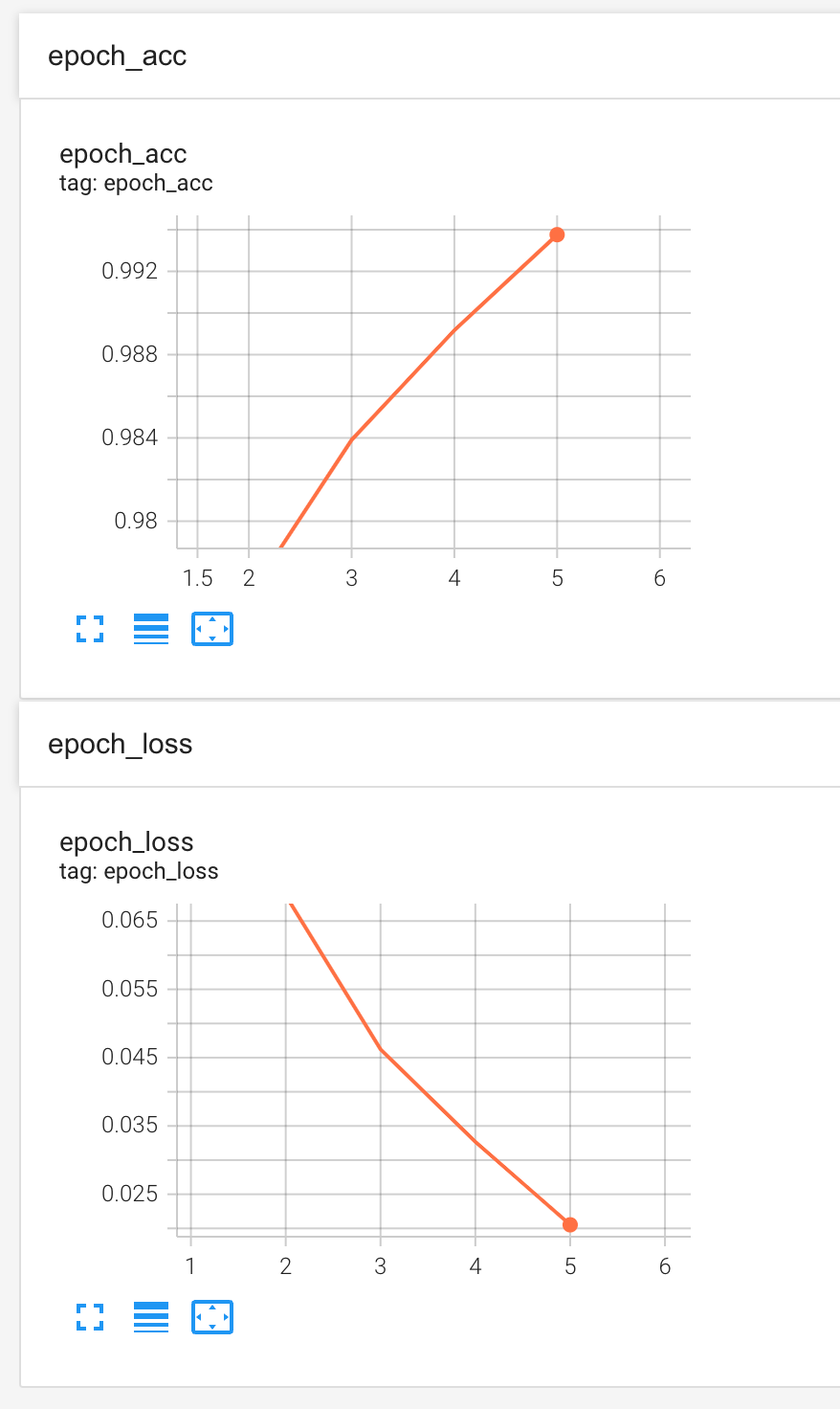
我们最终收集了大约两万多条数据,经过反复的训练与调试,最终准确率稳定在99.4%左右,达到一个相对可用的水*。
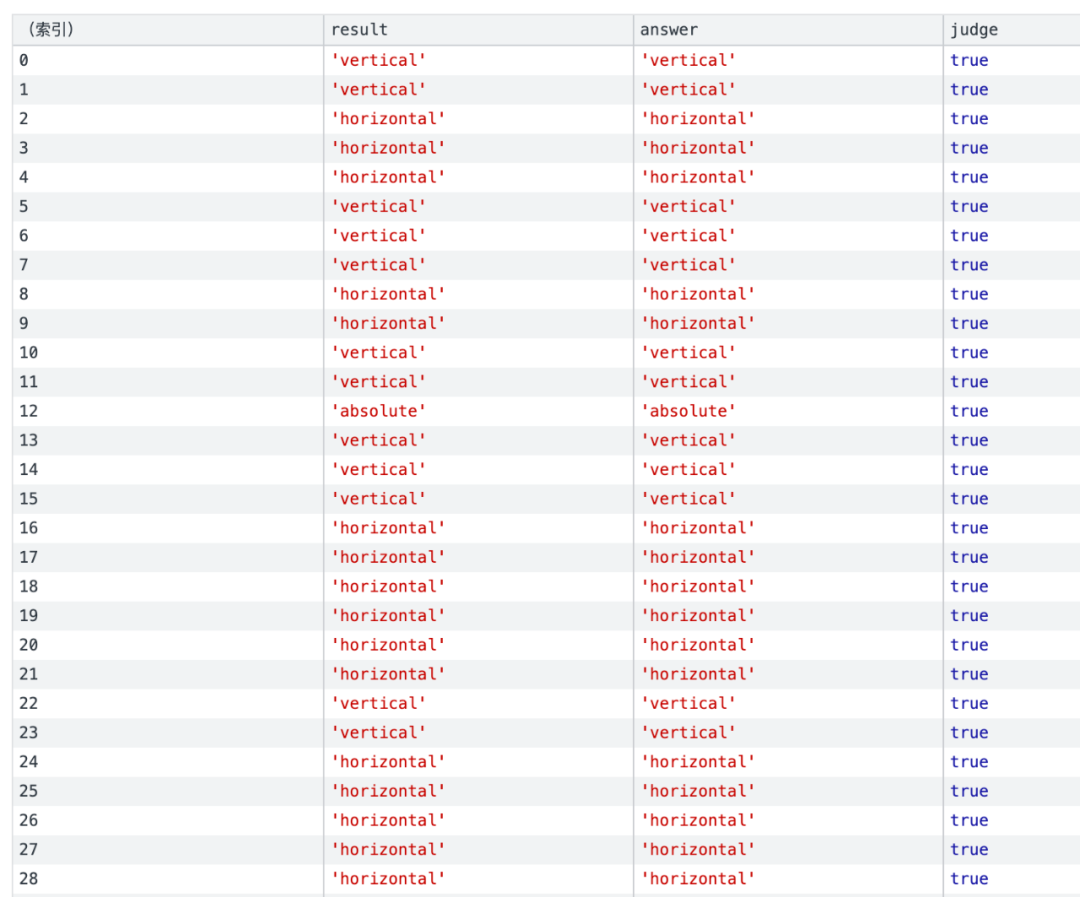
使用真实的dom进行回归验证,可以看出准确的识别出了网页的横向竖向布局以及绝对定位的节点。
六、优化方向
6.1 元素换行
设计稿中会出现列表一行放不下然后换行的情况,这些节点应该是属于横向的位置关系,但是机器面对两行会将每一行的首个元素识别成纵向排布,这就需要对重复节点进行相似度检测,对相似节点采用相同的布局策略。
6.2 分组问题
基于规则的分组会导致两个不相交的节点不会分配到一个组里面,比如网格中的图标和文字,导致布局的时候会分成两个独立的组,可以通过训练常见的布局结合内容识别进行更精准的分组。
6.3 通用布局
通过self-attention机制我们不仅可以判断单个节点在其层级的布局信息,我们也可以进行发散,通过训练整个层级的节点数据得出当前节点属于卡片流,标签,个人信息页等功能性的标记,进一步推导出每个节点的功能,再结合节点具体的布局信息,不仅可以更好的实现网页的排布,还可以节点的功能推到实现标签的语义化。
6.4 数据生成
为了解决更多的网页布局问题,同时减少我们人工标记的工作量,可以运用强化学习模型开发一套网页生成工具,让我们的数据更接*真实的网页布局,从而使布局模型训练的结果更加贴*生产的场景。
七、总结
机器学习非常擅长处理分类问题,相比于传统的手写规则布局,机器学习是基于我们现有的开发习惯进行训练,最终生成的代码也更加贴*我们*时的切图习惯,代码的可读性和可维护性都更上一层楼。
而机器生成的静态页面相较于不同的人手写的静态页面,遵循一致的代码规范,代码风格也更加统一。
在模型搭建的过程中可以将具体的使用场景类比为文本或者图像领域的内容,便于寻找现有的模型进行迁移学习。
运用机器学习解决网页布局问题的核心在于建立节点的上下文的关联,通过了解各种经典的神经网络模型的运行原理我们选出了循环神经网络和自注意力机制这种能够建立上下文关联的模型,而通过对于其运行原理的进一步了解我们选择了更贴*网页布局场景以及运行效率更高的self-attention模型,由此也可以看出了解模型的运行机制可以更好的帮助我们解决实际的应用场景。
vivo前端智能化实践:机器学习在自动网页布局中的应用的更多相关文章
- 在网页布局中合理使用inline formating context(IFC)
引子:给大家出一个小小的考题,如何使用css来实现类似下面的在指定区域内,内容自适应的垂直居中.
- CSS网页布局中易犯的30个小错误
即使是CSS高手,也难免在书写CSS代码的时候出一些小错误,或者说,任何一种代码都是如此.小错误却往往造成大问题,浪费很多无辜的时间来调试和排错.查看下面这份CSS网页布局中易犯的10个小错误,努力的 ...
- 关于网页布局中常见的margin: 0px ; padding: 0px; 总结
我们在网页布局中常用到margin: 0px; padding: 0px; 但是在大型的网站布局中通常不这样写通常是按下面这种方式. ul, li, ol, dl, dt, dd, div, p, ...
- 详解CSS网页布局中默认字体样式
浏览器默认的样式往往在不同的浏览器.不同的语言版本甚至不同的系统版本都有不同的设置,这就导致如 果直接利用默认样式的页面在各个浏览器下显示非常不一致,于是就有了类似YUI的reset之类用来尽量重写浏 ...
- 网页布局中页面内容不足一屏时页脚footer固定底部
方法一:给html.body都设置100%的高度,确定body下内容设置min-height有效,然后设置主体部分min-height为100%,此时若没有header.footer则刚好完美占满全屏 ...
- 简单实用的CSS网页布局中文排版技巧
由于汉字的特殊性,在css网页布局中,中文排版有别于英文排版.排版是一个麻烦的问题,小编认为,作为一个优秀的网页设计师和网页制作人员,掌握一些简单的中文排版技巧是不可或缺的,所以今天特意总结了几个简单 ...
- 【移动前端开发实践】从无到有(统计、请求、MVC、模块化)H5开发须知
前言 不知不觉来百度已有半年之久,这半年是996的半年,是孤军奋战的半年,是跌跌撞撞的半年,一个字:真的是累死人啦! 我所进入的团队相当于公司内部创业团队,人员基本全部是新招的,最初开发时连数据库都没 ...
- 蒲公英 · JELLY技术周刊 Vol.29: 前端智能化在阿里的那些事
蒲公英 · JELLY技术周刊 Vol.29 前端智能化是指借助于 AI 和机器学习的能力拓展前端,使其拥有一些超出现阶段前端能力的特性,这将是未来前端方向中一场重要的变革.目前各家互联网厂商都有自己 ...
- 有货前端 Web-APM 实践
有货前端 Web-APM 实践 0 背景 有货电商技术架构上采用的是前后端分离,前端是主要以业务展示和接口聚合为主,拥有自己的 BFF (Backend For Frontend),以 nodejs ...
随机推荐
- 写个js获取2019博客之星投票活动的名次与投票数
获取投票数 // app.jsvar request = require('request');var cheerio = require('cheerio');request('http://m23 ...
- UiPath数据抓取Data Scraping的介绍和使用
一.数据抓取(Data Scraping)的介绍 使用截据抓取使您可以将浏览器,应用程序或文档中的结构化数据提取到数据库,.csv文件甚至Excel电子表格中. 二.Data Scraping在UiP ...
- UiPath录制器的介绍和使用
一.录制器(Recording)的介绍 录制器是UiPath Studio的重要组成部分,可以帮助您在自动化业务流程时节省大量时间.此功能使您可以轻松地在屏幕上捕获用户的动作并将其转换为序列. 二.录 ...
- [LINUX] 像电影里的黑客一样用 terminal 作为日常开发
目录 1.效果预览 2.具体实现 2.1 定位鼠标位置 2.2 获取屏幕位置 2.3 计算鼠标在哪个窗口 2.4 1920x1080 平铺效果设计 2.5 1280x1024 平铺效果设计 3 代码 ...
- NC23046 华华教月月做数学
NC23046 华华教月月做数学 题目 题目描述 找到了心仪的小姐姐月月后,华华很高兴的和她聊着天.然而月月的作业很多,不能继续陪华华聊天了.华华为了尽快和月月继续聊天,就提出帮她做一部分作业. 月月 ...
- 漫谈客户端存储技术之Cookie篇
Cookie 说到Cookie,不管作为前端开发人员还是后端开发人员并不陌生,作为一种最古老.最稳定的客户端存储形式,即便是在当下各种新的客户端存储技术层出不穷的时代,它仍旧有其一席之位.Cookie ...
- 更强的 JsonPath 兼容性及性能测试之2022版(Snack3,Fastjson2,jayway.jsonpath)
2022年了,重新做了一份json path的兼容性与性能测试.三个市面上流行框架比较性测试. 免责声明:可能测试得方式不对而造成不科学的结果(另外,机器不同结果会有不同),可以留言指出来.以下测试数 ...
- java-数据输入,分支结构
数据输入 1.Scanner使用的基本步骤" 导包:import java.util.Scanner;(导包的动作必须出现在类定义的上边) 创建对象:Scanner sc = new Sca ...
- Mybatis SqlNode源码解析
1.ForEachSqlNode mybatis的foreach标签可以将列表.数组中的元素拼接起来,中间可以指定分隔符separator <select id="getByUserI ...
- 使用Java客户端发送消息和消费的应用
体验链接:https://developer.aliyun.com/adc/scenario/fb1b72ee956a4068a95228066c3a40d6 实验简介 本教程将Demo演示使用jav ...