【机器学习基础】无监督学习(3)——AutoEncoder
前面主要回顾了无监督学习中的三种降维方法,本节主要学习另一种无监督学习AutoEncoder,这个方法在无监督学习领域应用比较广泛,尤其是其思想比较通用。
AutoEncoder
0.AutoEncoder简介
在PCA一节中提到,PCA的可以看做是一种NN模型,通过输入数据,乘以权重w即可得到降维后的数据c,然后再利用c将数据进行还原。如下图:
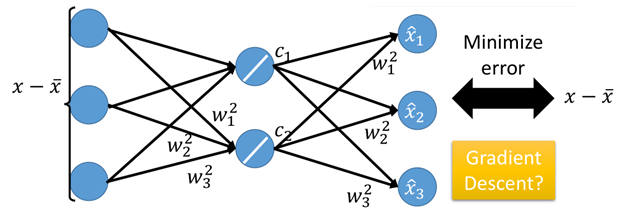
上面就是AutoEncoder的基本结构,对于前半部分(降维)是一个Encoder的过程,而对于后半部分(还原)则是一个Decoder的过程。
这里Encoder相当于一个降维,即无监督学习中开头介绍的“化繁为简”的过程,而后面一部分decoder则属于无监督学习中“无中生有”的内容。
Encoder可以想象成在谍战中的对情报进行加密的过程,而decoder相当于对加密的情报再解密的过程,而过程中参数W则是加密和解密所需要的“密码本”。
对于图片识别而言,则是向模型中丢进去一张图片,通过encode层将图片转变为一个code,而decode的作用则是输入一个code,它可以将这个code变成一张图片。如图所示:
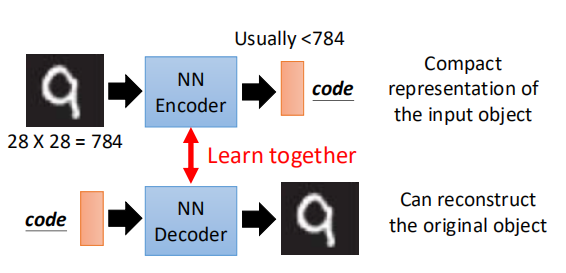
所以上面的这其实属于两个结构,但是当某一个结构单独存在的时候,则是无法进行学习的,但是如果将两个接在一起,就可以进行学习了。像前面PCA中说的那样。如下图所示:
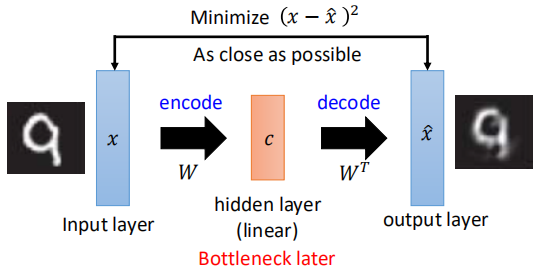
通过输入一个图片,经encode之后得到code,再将code经decode之后,达到将数据重构的目的,我们期望原数据与重构的数据越接近越好,称之为reconstruction error。
当然,既然有了隐藏层,那么AutoEncoder也可以像NN那样做到Deep AutoEncoder,如下图所示:
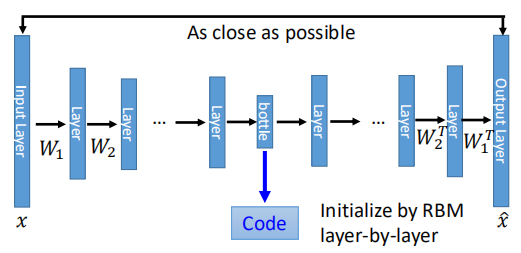
input经过很多层之后得到bottle layer也就是code,然后再解回得到output。
在06年是这样深的network受限于计算能力,使用的是RBM(受限玻尔兹曼机)来pre-train,但目前基本不再需要了。
通常设定encode的部分的参数与decode部分的参数是一致的,这样可以减少参数量,但这是非必要的。
Deep可以让模型学习的更好,对于数据重构而言,重构回去的数据更加接近原来的数据,因为deep可以让机器学到更抽象的东西,如下图:
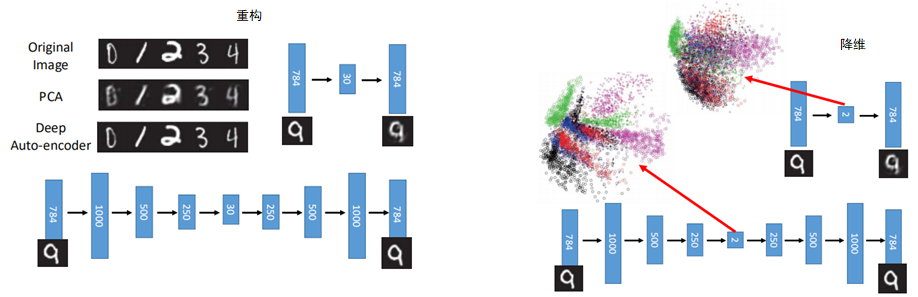
当然,有时为了避免模型直接将结果进行复制,最后又返回给输出层,一般会在输入中加入以下noise,如图:
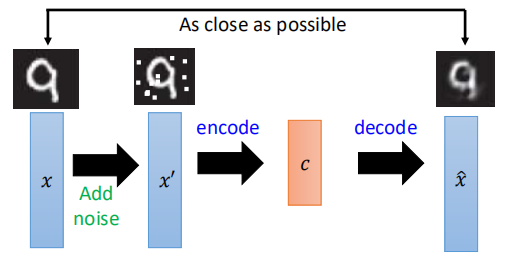
这种AutoEncoder成为de-nosiong AutoEncoder。
上面就是AutoEncoder的基本思想,就相当于是一种特殊的网络结构。由于Encoder和Decoder的作用不同,通常应用也不同,下面就分开先说一下二者的一些应用,最后再对AutoEncoder进行实现。
1.Encoder应用
Encoder前面说到就是一种利用NN进行降维的方法,所以Encoder最大的作用就是降维。
- 同前面的降维一样,进行降维的可视化,如下图:

左边是tsne的结果,可以看到“4”和“9”还是有些重叠,“1”中也掺杂了一些其他的点,右边是利用AutoEncoder所得到的结果,数字之间拉的就比较开,效果比较好。
这里需要注意的是:利用AutoEncoder进行训练时并没有用图中的样本进行训练,而是利用另一部分数据训练,然后将测试数据丢进模型产生一个code,然后再画出来。
- 可以用来做文本的挖掘,相当于word embedding
首先将每一篇文章按照bag of words进行表示:
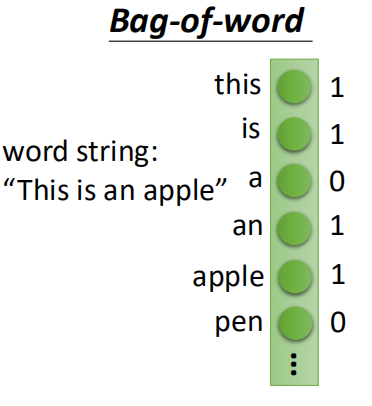
然后将利用encoder进行降维:
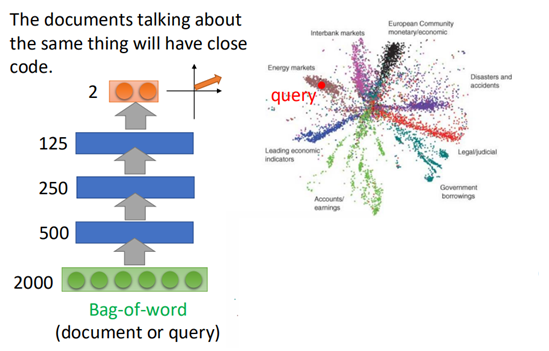
可以看到结果中不同的topic分布在不同的区域,当输入一个query时,则可以搜索与之最接近的topic。
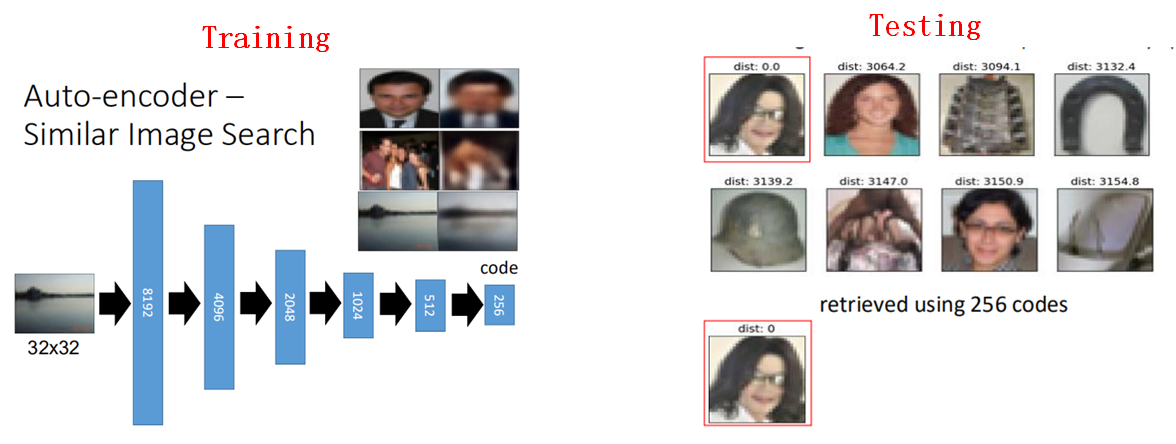
- Encoder可以用来做图片的检索
训练一个encoder,然后输入一张图片,将图片通过encoder之后生成一个code(即降维后的数据),然后在低维空间计算数据之间的相似度,从而找出与目标图片最相似的图片。
- Encoder可以用于与CNN结合起来做无监督学习
利用AutoEncoder的思想,结合CNN可以用来做无监督学习。
一张图片经过卷积、池化之后,生成一个code,然后code在经过反卷积、反池化之后还原为原来的图片,还原后的图片与原图片越接近越好。
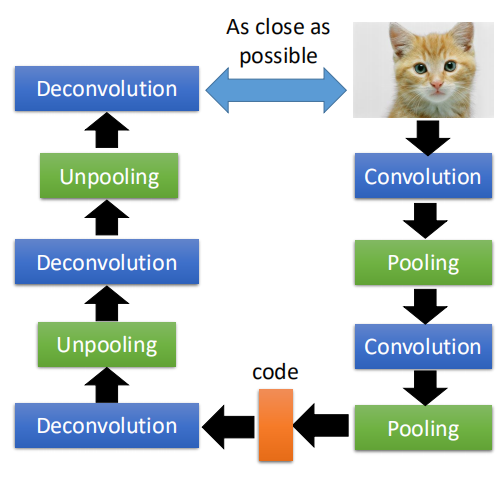
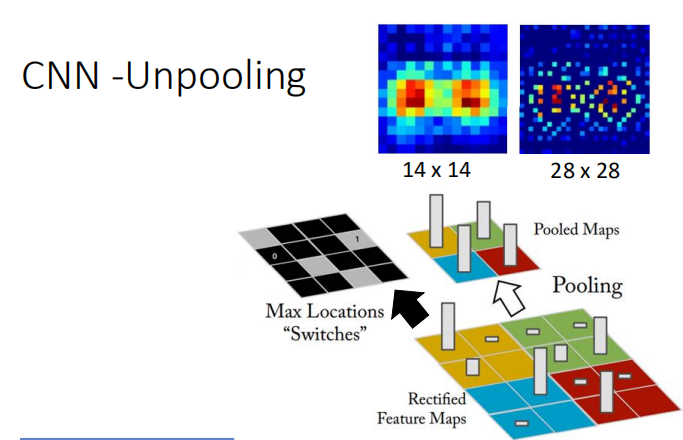
这里主要的操作就是反卷积和反池化,下面大致说一下这二者的原理:
首先是反池化,就是将通过pooling之后的数据再进行反向的操作。这里以maxpooling举例,在CNN中学过,在池化过程中:
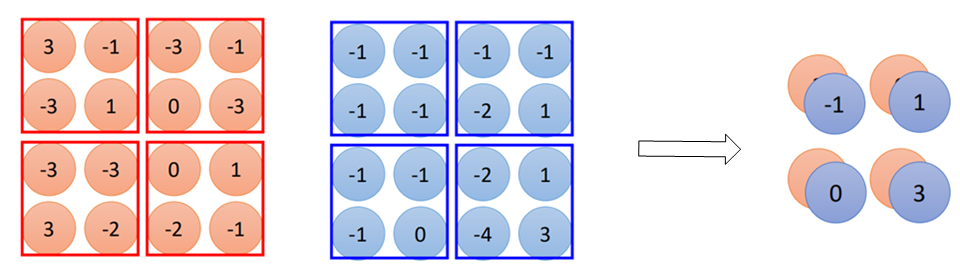
每一个channel4*4经过2*2的pooling之后变成了2*2大小的尺寸,而反池化就是将一个2*2还原成为原来的4*4大小。
在max pooling中我们对每一组取一个最大值(记下最大值的那个索引),但其他的值直接舍弃掉了,现在想要还原回去,就无法得到原本的值,那么怎么办呢?
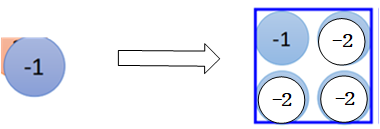
在进行反池化时,这些原本被舍弃掉的值进行填充时一般都填充为同样的值,并且这个值小于原本保留的那个最大值。
比如第一个蓝色方框内四个值都为-1,那么经过pooling之后,就是一个-1,现在将-1还原成四个值,由于原本都是-1,这里假设选择其中一个作为最大值,那么其他值则可以填为-2(也或者令这个-1的地方等于1,其他地方为0):
对于反卷积过程,其实就是卷积过程,下面来解释一下:
在卷积过程中,如下图所示:
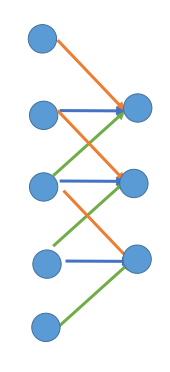
将一个图片经过一个filter之后进行缩小,假设原来有5*1大小,那么经过3*1的filter之后变成了3*1个,图中每条边表示filter的一个元素,
那么在反卷积过程中,要将3*1大小的还原成原来的5*1,那么这个过程同样可以看成一个卷积的过程,只不过这个卷积要3*1大小的尺寸“看作”是7*1,那么其经过3*1的filter之后就会变成5*1。
那么怎么能把3*1的看成是7*1的呢,其实很简单,就是在空缺的部分补0就好了。如图所示:
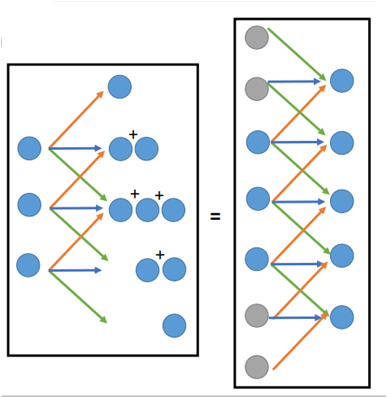
左边那一部分中每个神经元乘以三个weight(weight就是filter),每一个weight都会生成3个值,然后放在对应的位置,将重叠的部分相加。这也就等价于3*1看成7*1,然后其他部分补零,同样用filter进行卷积即可。
因此可以说反卷积其实就是一种卷积。
2.Decoder应用
上面介绍了一些Encoder的应用,同样Decoder也可以用来做一些事情,首先先来看一下,将若干张Mnist图片降维成2维后,变成code,然后画在图上的样子:
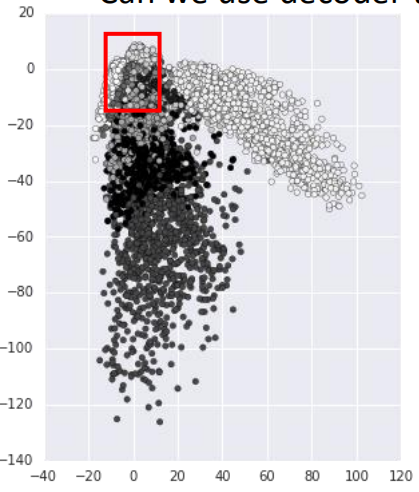
图上面的每一个点都是一张Mnist图片,通过训练已经得到一个encoder和decoder了,上图中的每个点就是一个code。
也就是说,把这里的每一个点(code)再代回decoder里(code作为输入),则会生成对应的图片,

那么选取红色框中的code所代表的图片就是这样的:

如果不选取这些已经存在的点,而是选取一些不存在的code放进decoder中也会产生图片出来吗?
从下面红色的框中,以某个点为中心取出一些点出来,丢进decoder里,则会产生这样的图片:
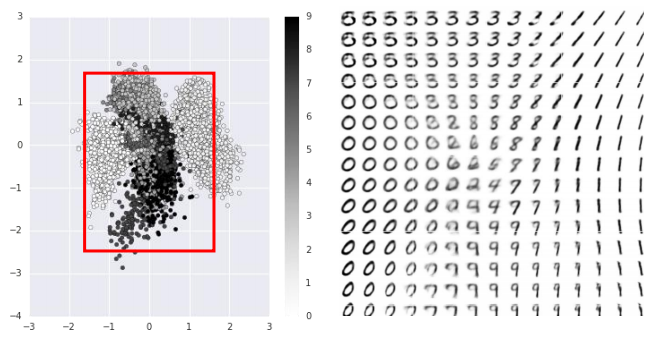
可以看到decoder可以根据输入的code产生相应的结果,而且呈现一定的规律性。
那么decoder可以用来做生成模型中图片的生成,但有时我们随机取出的点并非那么准确地刚好落在想取的区域或者刚好是想要的点。因此还有其它的生成模型到后面再说。
3.AutoEncoder的Tensorflow实现
最近在学习tensorflow和深度学习有关内容,刚好到这里对AutoEncoder进行一个简单的实现,可以同时复习到最近学习的东西。
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
import pylab
import matplotlib.pyplot as plt
import numpy as np
# 读取数据集
mnist = input_data.read_data_sets('MNIST_data/', one_hot=True)
im = mnist.train.images[-1]
print(im.shape) # 784
im = im.reshape(-1, 28)
print(im.shape) # 28*28
pylab.imshow(im)
pylab.show()
# 输入输出都是784维
n_input = 784
n_output = 784
# encoder和decoder都是两层,784→256→128→256→784
n_layer1 = 256
n_layer2 = 128
# 占位符,y这里不需要
x = tf.placeholder(tf.float32, [None, n_input])
# y = tf.placeholder(tf.float32, [None, n_output])
# 初始化权重,每一层有一个对应的权重矩阵
weights = {'h1_encoder': tf.Variable(tf.truncated_normal([n_input, n_layer1])),
'h2_encoder': tf.Variable(tf.truncated_normal([n_layer1, n_layer2])),
'h1_decoder': tf.Variable(tf.truncated_normal([n_layer2, n_layer1])),
'h2_decoder': tf.Variable(tf.truncated_normal([n_layer1, n_output]))}
# 初始化偏置
biases = {'b1_encoder': tf.Variable(tf.zeros([n_layer1])),
'b2_encoder': tf.Variable(tf.zeros([n_layer2])),
'b1_decoder': tf.Variable(tf.zeros([n_layer1])),
'b2_decoder': tf.Variable(tf.zeros([n_output]))}
# encoder 784→256→128
def encoder(x, weights, biases):
layer1 = tf.nn.sigmoid(tf.matmul(x, weights['h1_encoder']) + biases['b1_encoder'])
layer2 = tf.nn.sigmoid(tf.matmul(layer1, weights['h2_encoder']) + biases['b2_encoder'])
return layer2
# decoder 128→256→784
def decoder(x, weights, biases):
d_layer1 = tf.nn.sigmoid(tf.matmul(x, weights['h1_decoder']) + biases['b1_decoder'])
y_pred = tf.nn.sigmoid(tf.matmul(d_layer1, weights['h2_decoder']) + biases['b2_decoder'])
return y_pred
# encoder的输出
code = encoder(x, weights, biases)
# decoder的输出
y_pred = decoder(code, weights, biases)
# 定义损失函数,(x-x~)^2
cost = tf.reduce_mean(tf.pow(y_pred - x, 2))
# 定义优化函数,选用Adam算法
optimizer = tf.train.AdamOptimizer(0.0001).minimize(cost)
# epoch为20, batch_size为128
training_epoch = 20
batch_size = 128
# 每一轮训练次数,总样本数/batch_size
num_batch = int(mnist.train.num_examples/batch_size)
# 开始训练
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for i in range(training_epoch):
avg_loss = 0
for j in range(num_batch):
xs, ys = mnist.train.next_batch(batch_size)
_, loss = sess.run([optimizer, cost], feed_dict={x: xs})
avg_loss += loss/num_batch
if i%2 == 0:
print('epoch:', i, 'loss:', avg_loss)
print('Finished')
# 用测试数据的前10张图片进行对比,并画图
decode_image = sess.run(y_pred, feed_dict={x: mnist.test.images[:10]})
fig, ax = plt.subplots(2, 10, figsize=(10, 2))
for i in range(10):
ax[0][i].imshow(np.reshape(mnist.test.images[i], (28, 28)))
ax[1][i].imshow(np.reshape(decode_image[i], (28, 28)))
plt.show()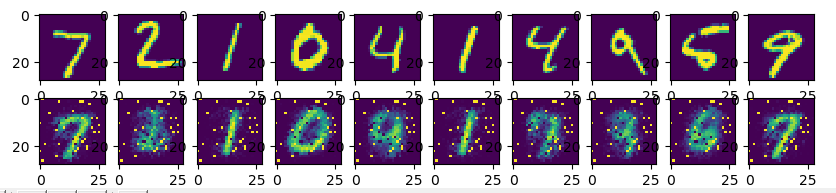
可以看到在进行还原时的图片有的与原图差距还是比较大的,可以尝试一下更深层次的网络,可能还原效果更好。
以上就是AutoEncoder的内容了,其原理比较简单,相当于一个“收窄”的深度神经网络,但其内在的原理一定要清楚。后面后进一步说到有关生成模型会对这一部分再进行一个简单的回顾。
参考文献:
《李宏毅机器学习——深度自编码》
后面也开始学习一些深度学习的有关内容,同时tensorflow框架。后面更新打算更新机器学习基础的同时,再开对应的深度学习和tensorflow学习专题。
【机器学习基础】无监督学习(3)——AutoEncoder的更多相关文章
- Spark机器学习基础-无监督学习
0.K-means from __future__ import print_function from pyspark.ml.clustering import KMeans#硬聚类 #from p ...
- Python 机器学习实战 —— 无监督学习(上)
前言 在上篇<Python 机器学习实战 -- 监督学习>介绍了 支持向量机.k近邻.朴素贝叶斯分类 .决策树.决策树集成等多种模型,这篇文章将为大家介绍一下无监督学习的使用.无监督学习顾 ...
- Python 机器学习实战 —— 无监督学习(下)
前言 在上篇< Python 机器学习实战 -- 无监督学习(上)>介绍了数据集变换中最常见的 PCA 主成分分析.NMF 非负矩阵分解等无监督模型,举例说明使用使用非监督模型对多维度特征 ...
- 【机器学习】无监督学习Autoencoder和VAE
众所周知,机器学习的训练数据之所以非常昂贵,是因为需要大量人工标注数据. autoencoder可以输入数据和输出数据维度相同,这样测试数据匹配时和训练数据的输出端直接匹配,从而实现无监督训练的效果. ...
- 2019-07-31【机器学习】无监督学习之聚类 K-Means算法实例 (图像分割)
样本: 代码: import numpy as np import PIL.Image as image from sklearn.cluster import KMeans def loadData ...
- 2019-07-31【机器学习】无监督学习之降维NMF算法 (人脸特征提取)
代码 from numpy.random import RandomState #加载RandomState用于创建随机种子 import matplotlib.pyplot as plt from ...
- 2019-07-31【机器学习】无监督学习之降维PCA算法实例 (鸢尾花)
样本 代码: import matplotlib.pyplot as plt from sklearn.decomposition import PCA from sklearn.datasets i ...
- 2019-07-28【机器学习】无监督学习之聚类 DBSCAN方法及其应用 (在线大学生上网时间分析)
样本: import numpy as np import sklearn.cluster as skc from sklearn import metrics import matplotlib.p ...
- 2019-07-25【机器学习】无监督学习之聚类 K-Means算法实例 (1999年中国居民消费城市分类)
样本 北京,2959.19,730.79,749.41,513.34,467.87,1141.82,478.42,457.64天津,2459.77,495.47,697.33,302.87,284.1 ...
随机推荐
- Spring ModelAttribute注解失效原因
public String test(@RequestParam(value = "test") @ModelAttribute("test") String ...
- JAVA DAEMON线程的理解
java线程分两种:用户线程和daemon线程.daemon线程或进程就是守护线程或者进程,但是java中所说的daemon线程和linux中的daemon是有一点区别的. linux中的daemon ...
- jdk 8 HashMap源码解读
转自:https://www.cnblogs.com/little-fly/p/7344285.html 在原来的作者的基础上,增加了本人对源代码的一些解读. 如有侵权,请联系本人 这几天学习了Has ...
- 从CSS盒子模型说起
前言 总括: 对于盒子模型,BFC,IFC和外边距合并等概念和问题的总结 原文地址:从CSS盒子模型说起 知乎专栏:前端进击者 博主博客地址:Damonare的个人博客 为学之道,莫先于穷理:穷理之要 ...
- 小程序web开发框架-weweb介绍
weweb是一个兼容小程序语法的前端框架,你可以用小程序的写法,来写web单面应用.如果你已经有小程序了,通过它你可以将你的小程序运行在浏览器中.在小程序大行其道的今天,它可以让你的小程序代码得到最大 ...
- Android:setOnItemClickListener cannot be used with a spinner报错
错误原因: Spinner对象不支持使用setOnItemClickListener方法监听点击事项 解决方法: 使用setOnItemSelectedListener方法代替setOnItemCli ...
- vue多个数据不一样的表格导出到同一张excel里面
刚来公司第二天, 甩了个需求, 把两个不同表格的数据 导出到同一个excel中 ........额,好吧 你要说,两个表格数据差不多, 直接合并数据导出就行: async function getDa ...
- sring框架的jdbc应用
xml配置 <?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http: ...
- Java Web项目与Java项目的区别
一.以下是我对Java Web项目和Java项目这两者的理解以及区别: 1.Java Web项目是基于Java EE类的:而Java项目是基于Java应用程序的. 2.Java Web项目是网页的编码 ...
- 小程序checkbox调整大小(checkbox样式修改)
.skyCheckbox{ transform: scale(0.7,0.7); -webkit-transform: scale(0.7,0.7); } <label class=" ...