【Deep Learning】DDPM
DDPM

1. 大致流程
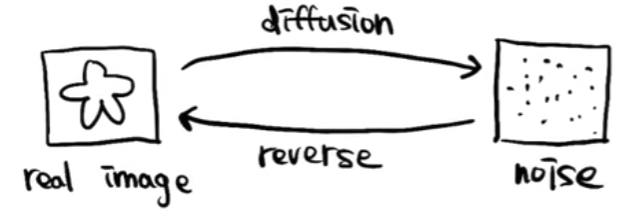
1.1 宏观流程
1.2 训练过程

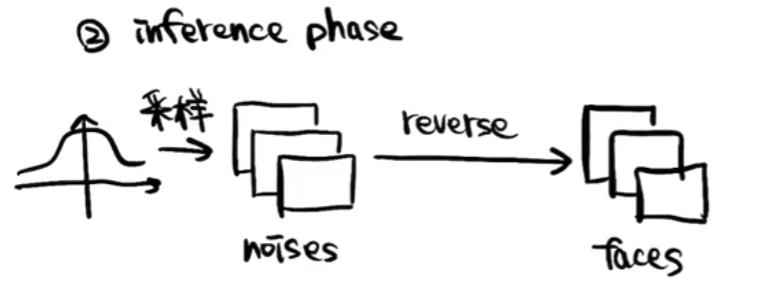
1.3 推理过程
2. 对比GAN
2.1 GAN流程

2.2 相比GAN优点
训练过程更稳定,损失函数指向性更强(loss数值大小指示训练效果好坏)
3. 详细流程
3.1 扩散阶段
如下图,X0为初始干净图像,XT由X0逐步添加噪声所得到

具体到一次Xt-1到Xt的扩散过程如下图,Zt为此时刻添加的随机噪声(服从标准正态分布),β随着时间t从0到T的过程逐步线性增大,通常扩散次数T选择1000(2000也行),选择这样的次数主要是希望最后得到的是一个完全噪声的图片,而不是还能看出图片中的内容

如上得到了每一步之间的扩散步骤,那么由最初的X0扩散到最终的XT,推导过程如下:
- 先用α替换掉β

- Xt由Xt-2表示

- Xt由X0表示

- t换成T来表示(最终XT是一个服从标准正态分布的随机噪声,即可以约等于噪声Z,即αT拔约等于0)
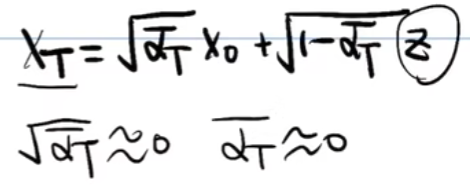
3.2 去噪重建阶段
- 大体过程
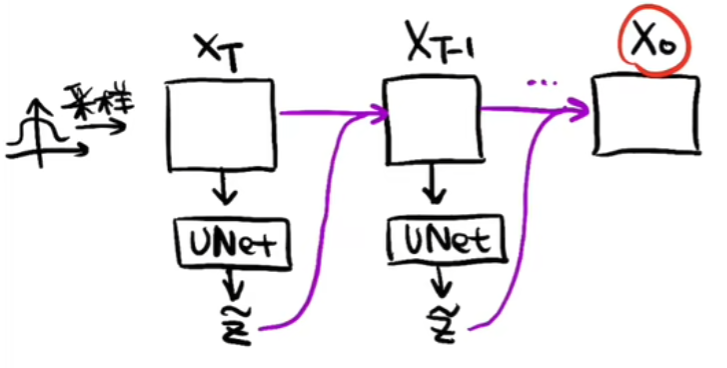
如下图,在去噪重建的过程中,先随机采样一个随机噪声XT,将XT放入U-Net预测噪声Z,然后将XT去除噪声Z得到XT-1,再将XT-1放入U-Net预测噪声...重复上述过程,直至最终预测出X0

- 用于预测噪声的U-Net如下,传入噪声Xt和t,t可以理解为positional embedding,因为在前向的扩散过程中每一时刻添加的噪声强度是不一样的,所以在进行预测的时候,预测出的每一时刻的噪声强度也是不一样的

- 如上我们已经可以使用U-Net预测出每一时刻的噪声了,那我们怎么通过预测出的噪声预测书上一时刻的图片呢?也就是怎么得到如下图的推理公式呢?
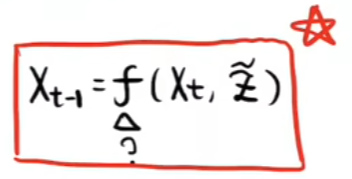
- 如下一系列图片即进行上述问题的推理
首先观察如何从Xt得到Xt-1,利用贝叶斯公式进行如下转化
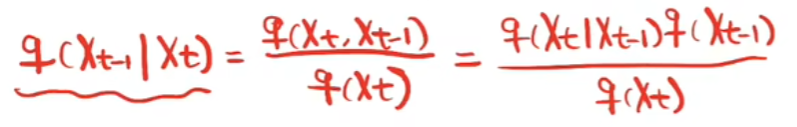
然后根据如下扩散过程推出上述每一部分的表达式


然后根据标准正态分布,求出整体表达式
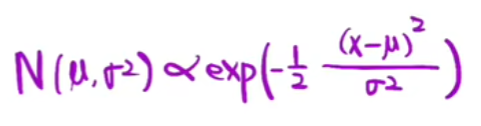
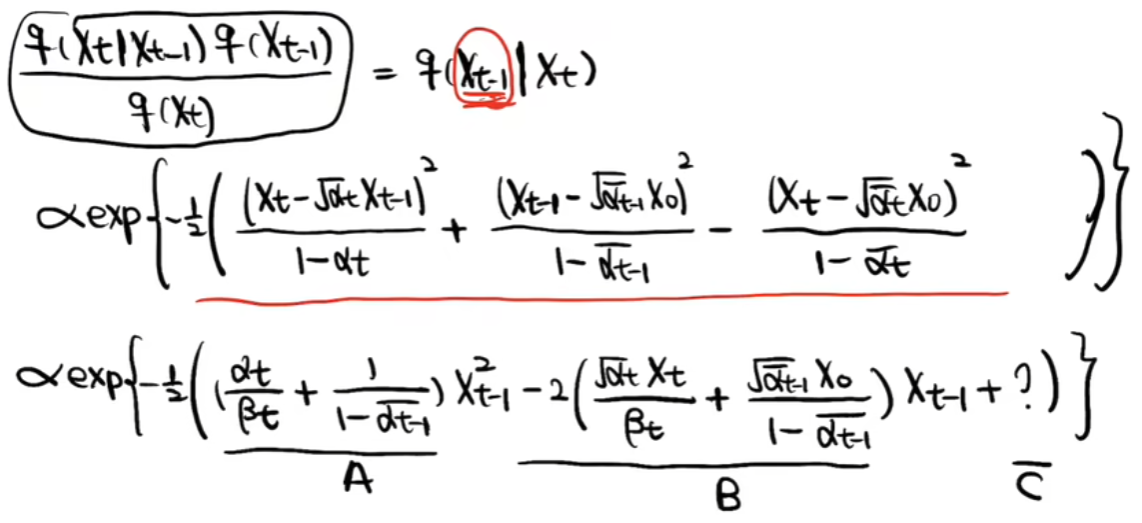
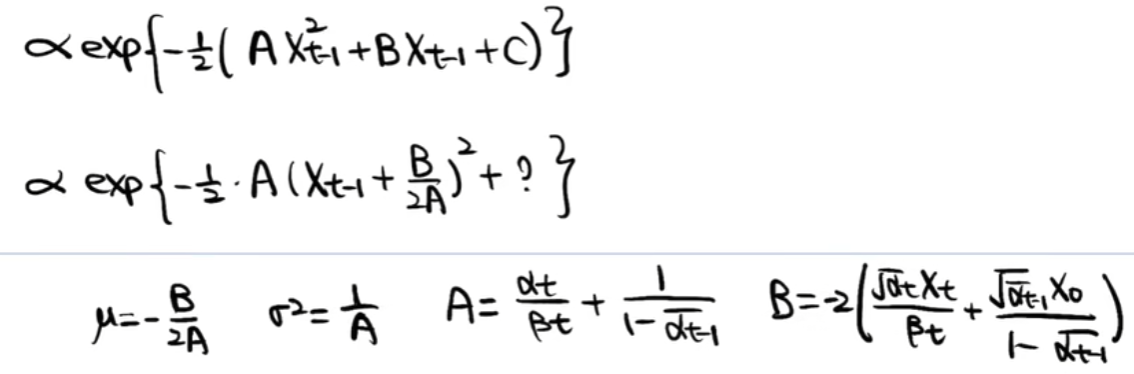

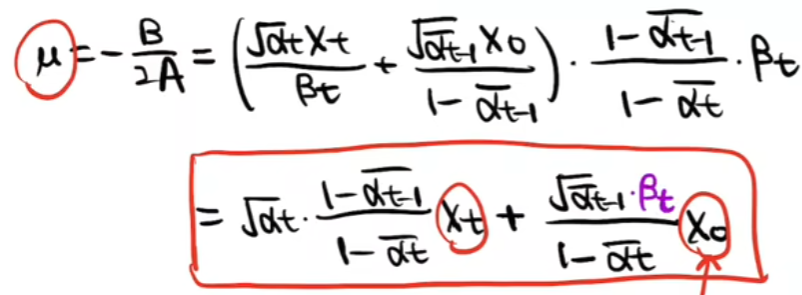


最终得出XT到XT-1的表达式

如上,便完成了一次使用U-Net预测出的噪声对随机采样的噪声去噪,接下来就是从XT一直去噪到X0的过程
4. 论文算法
4.1 Training
实际的训练过程中,没有如上所描述的那样繁琐,总的来说如下:
repeat
在均匀分布T里随机采一个t
随机采样一个标准分布的噪声ε
使用t和ε计算出Xt
将Xt和t放入U-Net预测出噪声(εθ(Xt,t)即为U-Net)
计算εθ和ε损失
until 收敛

4.2 Sampling
去噪的生成过程中,需要注意一点,当逐步去噪到t=1时,不需要再随机采样一个标准正态分布的Z,因为此时求的是X0(最后的干净图片),干净图片再添加一个噪声就变得不干净了。

【Deep Learning】DDPM的更多相关文章
- 【Deep Learning】一、AutoEncoder
Deep Learning 第一战: 完成:UFLDL教程 稀疏自编码器-Exercise:Sparse Autoencoder Code: 学习到的稀疏参数W1: 参考资料: UFLDL教程 稀疏自 ...
- 【Deep Learning】genCNN: A Convolutional Architecture for Word Sequence Prediction
作者:Mingxuan Wang.李航,刘群 单位:华为.中科院 时间:2015 发表于:acl 2015 文章下载:http://pan.baidu.com/s/1bnBBVuJ 主要内容: 用de ...
- 【Deep Learning】林轩田机器学习技法
这节课的题目是Deep learning,个人以为说的跟Deep learning比较浅,跟autoencoder和PCA这块内容比较紧密. 林介绍了deep learning近年来受到了很大的关注: ...
- 【Deep Learning】两层CNN的MATLAB实现
想自己动手写一个CNN很久了,论文和代码之间的差距有一个银河系那么大. 在实现两层的CNN之前,首先实现了UFLDL中与CNN有关的作业.然后参考它的代码搭建了一个一层的CNN.最后实现了一个两层的C ...
- 【Deep Learning】Hinton. Reducing the Dimensionality of Data with Neural Networks Reading Note
2006年,机器学习泰斗.多伦多大学计算机系教授Geoffery Hinton在Science发表文章,提出基于深度信念网络(Deep Belief Networks, DBN)可使用非监督的逐层贪心 ...
- 【deep learning】斯坦福CS231n—深度学习与计算机视觉(资料汇总)
官网 链接:CS231n: Convolutional Neural Networks for Visual Recognition Notes: 链接:http://cs231n.github.io ...
- 【Deep Learning】RNN LSTM 推导
http://blog.csdn.net/Dark_Scope/article/details/47056361 http://blog.csdn.net/hongmaodaxia/article/d ...
- 【Deep Learning】RNN的直觉理解
https://ujjwalkarn.me/2016/08/11/intuitive-explanation-convnets/
- 【Deep learning】NLP
http://www.tuicool.com/articles/EvaQJnJ http://cs224d.stanford.edu/syllabus.html
- 【deep learning学习笔记】注释yusugomori的DA代码 --- dA.h
DA就是“Denoising Autoencoders”的缩写.继续给yusugomori做注释,边注释边学习.看了一些DA的材料,基本上都在前面“转载”了.学习中间总有个疑问:DA和RBM到底啥区别 ...
随机推荐
- Jetlinks物联网基础平台 前端运行项目遇到的问题
电脑中的环境要必备 node.js和yarn(需要将他们都添加到环境变量中,否则会报错) 1.在github上面拉取代码 $ git clone https://github.com/jetlinks ...
- 4组-Alpha冲刺-4/6
一.基本情况 队名:摸鲨鱼小队 组长博客:https://www.cnblogs.com/smallgrape/p/15553653.html 小组人数:8人 二.冲刺概况汇报 组长:许雅萍 过去两天 ...
- LeetCode刷题感想之滑动窗口
发现滑动窗口也是一种经典解题思路,这一篇简单聊一下滑动窗口. 通常在碰到求XX子数组,子字符串,连续XX等题眼,可以考试用滑动窗口的思路来解决问题. 窗口的类型有几种: 1. 固定长度的窗口. 2. ...
- 理解 Shell
理解 Shell shell 的父子关系 用于登录的某个虚拟控制器终端,或在 GUI 中运行终端仿真器时所启动的默认的交互 shell,是一个父 shell.本书到目前为止都是父 shell 提供 C ...
- AirServer 7(专业mac投屏软件)v7.2.6中文版
AirServer Mac是一款好用的投屏工具,它可以将您的Mac变成通用镜像接收器,允许您使用内置的AirPlay或基于Google Cast的屏幕投影功能镜像设备的显示器.您可以通过任何AirPl ...
- WEB应用中配置和使用springIOC容器是成功的
Sring web应用学习(1)https://www.cnblogs.com/xiximayou/p/12172667.html
- spacy
官方文档: https://spacy.io/api Spacy功能简介 可以用于进行分词,命名实体识别,词性识别等等,但是首先需要下载预训练模型 pip install --user spacy p ...
- python,数据类型和变量,数据类型和变量,集合,字符串拼接
可不可变: 可变:列表,字典 不可变:字符串,数字,元祖 访问顺序: 直接访问:数字 顺序访问:字符串,列表,元祖 映射:字典 存放元素个数 容器类型:列表,元祖,字典 原子:数字,字符串 集合 1. ...
- ARM-linux的Windows交叉编译环境搭建
交叉编译Arm Linux平台的QT5库 1.准备交叉编译环境 环境说明:Windows10 64位 此过程需要: (1)Qt库开源代码,我使用的是5.13.0版本: (2)Perl语言环境5.12版 ...
- springboot后端接收不到前端传来的表单值
为啥接收不到 因为传来的字段值太大了,springboot默认启动依赖tomcat,tomcat默认接收表单值最大为2MB,将server.tomcat.max-http-form-post-size ...