【JVM故障问题排查心得】「内存诊断系列」Docker容器经常被kill掉,k8s中该节点的pod也被驱赶,怎么分析?
背景介绍
最近的docker容器经常被kill掉,k8s中该节点的pod也被驱赶。
我有一个在主机中运行的Docker容器(也有在同一主机中运行的其他容器)。该Docker容器中的应用程序将会计算数据和流式处理,这可能会消耗大量内存。
该容器会不时退出。我怀疑这是由于内存不足,但不是很确定。我需要找到根本原因的方法。那么有什么方法可以知道这个集装箱的死亡发生了什么?
容器层级判断检测
提到docker logs $container_id查看该应用程序的输出。这永远是我要检查的第一件事。接下来,您可以运行docker inspect $container_id以查看状态的详细信息,例如:
"State": {
"Status": "exited",
"Running": false,
"Paused": false,
"Restarting": false,
"OOMKilled": false,
"Dead": false,
"Pid": 0,
"ExitCode": 2,
"Error": "",
"StartedAt": "2016-06-28T21:26:53.477229071Z",
"FinishedAt": "2016-06-28T21:26:53.478066987Z"
}
重要的一行是“ OOMKilled”,如果您超出了容器的内存限制,并且Docker杀死了您的应用程序,则该行将为true。您可能还需要查找退出代码,以查看其是否标识出您的应用退出的原因。
Docker内部,这仅表示docker本身是否会杀死您的进程,并要求您在容器上设置内存限制。
Docker外部,如果主机本身内存不足,Linux内核可以销毁进程。发生这种情况时,Linux通常会在/ var / log中写入日志。使用Windows和Mac上的Docker Desktop,您可以在docker设置中调整分配给嵌入式Linux VM的内存。
- 可以通过阅读日志来了解容器内的进程是否被OOM杀死。OOMkill是由内核启动的,因此每次发生时,都会在中包含很多行/var/log/kern.log,例如:
python invoked oom-killer: gfp_mask=0x14000c0(GFP_KERNEL), nodemask=(null), order=0, oom_score_adj=995
oom_kill_process+0x22e/0x450
Memory cgroup out of memory: Kill process 31204 (python) score 1994 or sacrifice child
Killed process 31204 (python) total-vm:7350860kB, anon-rss:4182920kB, file-rss:2356kB, shmem-rss:0kB
Linux操作系统的进程服务发生被killed的原因是什么
在Linux中,经常会遇到一些重要的进程无缘无故就被killed,而大多数的经验之谈就是系统资源不足或内存不足所导致的。
当Linux系统资源不足时,Linux内核可以决定终止一个或多个进程,内存不足时会在系统的物理内存耗尽时触发OOM killed,可以利用“dmesg | tail -N”命令来查看killed的近N行日志。

常规的宕机监控之类
在服务宕机或者重启之前我们的常规操作就是采用ps指令判定服务的增长趋势以及展示真实使用的资源的大小的前几位排名。
- Linux下显示系统进程的命令ps,最常用的有ps -ef 和ps aux。这两个到底有什么区别呢?
ps -ef指令代表着'SystemV风格',而ps aux代表着’BSD风格‘。

由上图所示,可以分析出对应的数据结构模型。
USER //用户名
%CPU //进程占用的CPU百分比
%MEM //占用内存的百分比
VSZ //该进程使用的虚拟內存量(KB)
RSS //该进程占用的固定內存量(KB)resident set size
STAT //进程的状态
START //该进程被触发启动时间
TIME //该进程实际使用CPU运行的时间
其中CPU算是第3个位置、内存MEM算是第4个位置,虚拟内存VSZ是第5个位置,记住这个后面我们会使用这个方式进行排序。
查看当前系统内CPU占用最多的前10个进程(栏位属于第3个)
ps auxw | sort -rn -k3 | head -10
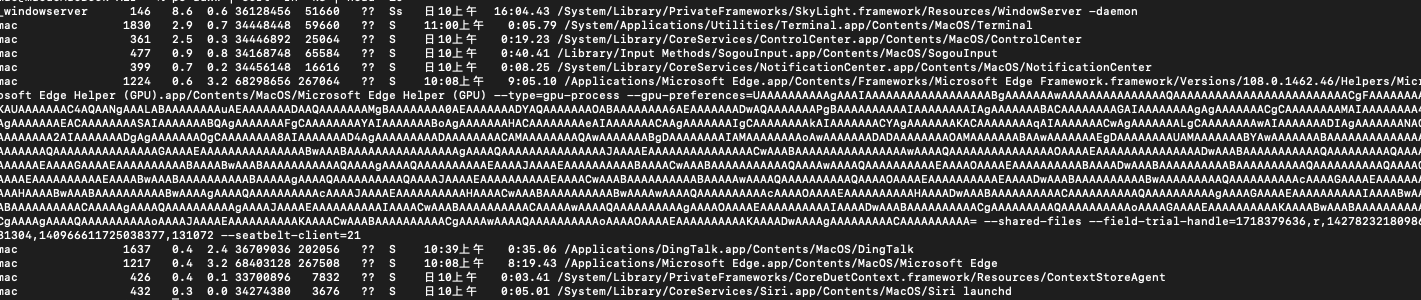
ps auxw指令(BSD风格)
- u:以用户为主的格式来显示程序状况
- x:显示所有程序,不以终端机来区分
- w:采用宽阔的格式来显示程序状况
sort排序指令
sort -rn -k5
-n是按照数字大小排序(-n 这代表着排除n行的操作处理),-r是以相反顺序,-k是指定需要排序的栏位
ps auxw | head -1
内存消耗最多的前10个进程(栏位属于第4个)
ps auxw | head -1;ps auxw|sort -rn -k4|head -10
虚拟内存使用最多的前10个进程(栏位属于第5个)
ps auxw|head -1;ps auxw|sort -rn -k5|head -10
去掉x参数的结果
ps auw | head -1; ps auw|sort -rn -k4 | head -10
stat取值含义

D //无法中断的休眠状态(通常 IO 的进程);
R //正在运行可中在队列中可过行的;
S //处于休眠状态;
T //停止或被追踪;
W //进入内存交换 (从内核2.6开始无效);
X //死掉的进程 (基本很少见);
Z //僵尸进程;
< //优先级高的进程
N //优先级较低的进程
L //有些页被锁进内存;
s //进程的领导者(在它之下有子进程);
l //多线程,克隆线程(使用 CLONE_THREAD, 类似 NPTL pthreads);
+ //位于后台的进程组;
dmesg的命令分析
有几个工具/脚本/命令 可以更轻松地从该虚拟设备读取数据,其中最常见的是 dmesg 和 journalctl。
输入dmesg指令进行egrep正则表达式匹配killed的进程信息,将输出对应的进程信息。
dmesg | egrep -i -B100 'killed process'
或
dmesg | grep -i -B100 'killed process'
以上的指令就可以输出最近killed的信息,其中-B100,表示 'killed process’之前的100行内容,与head的指令非常的相似。

如果我们看到了oom-kill的字样之后,就可以判断它是被内存不足所导致的kill,oom-kill之后,就是描述那个被killed的程序的pid和uid。
Out of memory: Killed process 1138439 (python3) total-vm:8117956kB, anon-rss:5649844kB,内存不够
total_vm和rss的指标值

total_vm:总共使用的虚拟内存 Virtual memory use (in 4 kB pages),8117956/1024(得到MB)/1024(得到GB)=7.741GB
rss:常驻内存使用Resident memory use (in 4 kB pages) 5649844/1024/1024=5.388GB
案例1:查看到pod被驱赶的原因
[3899860.525793] Out of memory: Kill process 64058 (nvidia-device-p) score 999 or sacrifice child
[3899860.526961] Killed process 64058 (nvidia-device-p) total-vm:126548kB, anon-rss:2080kB, file-rss:0kB, shmem-rss:0kB
案例2:查看到docker容器被kill 的原因
[3899859.737598] Out of memory: Kill process 27562 (jupyter-noteboo) score 1000 or sacrifice child
[3899859.738640] Killed process 27562 (jupyter-noteboo) total-vm:215864kB, anon-rss:45928kB, file-rss:0kB, shmem-rss:0kB
journalctl命令 – 查看指定的日志信息
当内存不足时,内核会将相关信息记录到内核日志缓冲区中,该缓冲区可通过 /dev/kmsg 获得。除了上面的dmesg之外,还有一个journalctl。
语法格式: journalctl [参数]
常用参数:
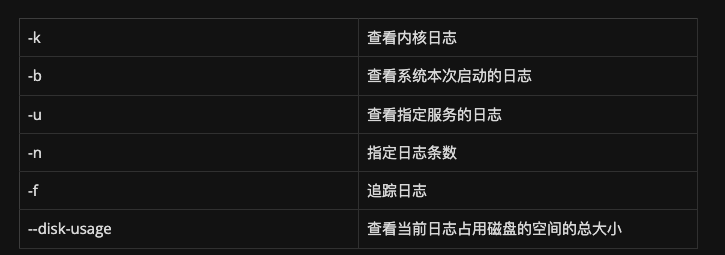
查看Killed日志
使用sudo dmesg | tail -7命令(任意目录下,不需要进入log目录,这应该是最简单的一种)而journalctl命令来自于英文词组“journal control”的缩写,其功能是用于查看指定的日志信息。
journalctl指令介绍
在RHEL7/CentOS7及以后版本的Linux系统中,Systemd服务统一管理了所有服务的启动日志,带来的好处就是可以只用journalctl一个命令,查看到全部的日志信息了。
查看所有日志(默认情况下 ,只保存本次启动的日志)
journalctl
查看内核日志(不显示应用日志)
journalctl -k
查看系统本次启动的日志
journalctl -b
journalctl -b -0
查看上一次启动的日志(需更改设置)
journalctl -b -1
查看指定时间的日志
journalctl --since=“2021-09-16 14:22:02”
journalctl --since “30 min ago”
journalctl --since yesterday
journalctl --since “2021-01-01” --until “2021-09-16 13:40”
journalctl --since 07:30 --until “2 hour ago”
显示尾部的最新10行日志
journalctl -n
显示尾部指定行数的日志
journalctl -n 15
实时滚动显示最新日志
journalctl -f
查看指定服务的日志
journalctl /usr/lib/systemd/systemd
比如查看docker服务的日志
systemctl status docker
查看某个 Unit 的日志
journalctl -u nginx.service
journalctl -u nginx.service --since today
实时滚动显示某个 Unit 的最新日志
journalctl -u nginx.service -f
合并显示多个 Unit 的日志
$ journalctl -u nginx.service -u php-fpm.service --since today
【JVM故障问题排查心得】「内存诊断系列」Docker容器经常被kill掉,k8s中该节点的pod也被驱赶,怎么分析?的更多相关文章
- 「美团面试系列」面试加分项,这样说你会JVM,面试官还能问什么
Java性能调优都是老生常谈的问题,特别当“糙快猛”的开发模式大行其道时,随着系统访问量的增加.代码的臃肿,各种性能问题便会层出不穷. 比如,下面这些典型的性能问题,你肯定或多或少都遇到过: 在进行性 ...
- ☕【Java深层系列】「并发编程系列」深入分析和研究MappedByteBuffer的实现原理和开发指南
前言介绍 在Java编程语言中,操作文件IO的时候,通常采用BufferedReader,BufferedInputStream等带缓冲的IO类处理大文件,不过java nio中引入了一种基于Mapp ...
- 【Java技术专题】「性能优化系列」针对Java对象压缩及序列化技术的探索之路
序列化和反序列化 序列化就是指把对象转换为字节码: 对象传递和保存时,保证对象的完整性和可传递性.把对象转换为有字节码,以便在网络上传输或保存在本地文件中: 反序列化就是指把字节码恢复为对象: 根据字 ...
- ☕【难点攻克技术系列】「海量数据计算系列」如何使用BitMap在海量数据中对相应的进行去重、查找和排序
BitMap(位图)的介绍 BitMap从字面的意思,很多人认为是位图,其实准确的来说,翻译成基于位的映射,其中数据库中有一种索引就叫做位图索引. 在具有性能优化的数据结构中,大家使用最多的就是has ...
- python爬虫30 | scrapy后续,把「糗事百科」的段子爬下来然后存到数据库中
上回我们说到 python爬虫29 | 使用scrapy爬取糗事百科的例子,告诉你它有多厉害! WOW!! scrapy awesome!! 怎么会有这么牛逼的框架 wow!! awesome!! 用 ...
- 「数据挖掘入门系列」Python快速入门
Python环境搭建 本次入门系列将使用Python作为开发语言.要使用Python语言,我们先来搭建Python开发平台.我们将基于Python 2.7版本.以及Python的开发发行版本Anaco ...
- 🏆(不要错过!)【CI/CD技术专题】「Jenkins实战系列」(3)Jenkinsfile+DockerFile实现自动部署
每日一句 没有人会因学问而成为智者.学问或许能由勤奋得来,而机智与智慧却有懒于天赋. 前提概要 Jenkins下用DockerFile自动部署Java项目,项目的部署放心推向容器化时代机制. 本节需要 ...
- 【分布式技术专题】「OSS中间件系列」Minio的文件服务的存储模型及整合Java客户端访问的实战指南
Minio的元数据 数据存储 MinIO对象存储系统没有元数据数据库,所有的操作都是对象级别的粒度的,这种做法的优势是: 个别对象的失效,不会溢出为更大级别的系统失效. 便于实现"强一致性& ...
- 【SpringCloud技术专题】「Gateway网关系列」(3)微服务网关服务的Gateway全流程开发实践指南(2.2.X)
开发指南须知 本次实践主要在版本:2.2.0.BUILD-SNAPSHOT上进行构建,这个项目提供了构建在Spring生态系统之上API网关. Spring Cloud Gateway的介绍 Spri ...
- ☕【Java深层系列】「并发编程系列」让我们一起探索一下CyclicBarrier的技术原理和源码分析
CyclicBarrier和CountDownLatch CyclicBarrier和CountDownLatch 都位于java.util.concurrent这个包下,其工作原理的核心要点: Cy ...
随机推荐
- Beats:使用 Elastic Stack 记录 Python 应用日志
文章转载自:https://elasticstack.blog.csdn.net/article/details/112259500 日志记录实际上是每个应用程序都必须具备的功能.无论你选择基于哪种技 ...
- Elasticsearch 开发入门 - Python
文章转载自:https://elasticstack.blog.csdn.net/article/details/111573923 前提条件 你需要在你的电脑上安装 python3 你需要安装 do ...
- prometheus设置使用密码nginx反向代理访问
注意: 1.设置访问密码的方式 2.ngixn反向代理的配置 # 安装 Apache工具包 apt install apache2-utils htpasswd -bc /etc/nginx/.pro ...
- python之流程控制上-if、while
流程控制 编写程序,是将自己的逻辑思想记录下来,使得计算机能够执行的过程. 而流程控制,则是逻辑结构中十分重要的一环. 在程序中,基础的流程结构分为顺序结构.分支结构.顺序结构 顺序结构自不必多说,上 ...
- Can not set int field xxx to java.lang.Long 错误
Can not set int field xxx to java.lang.Long 错误 这个错误其实是因为Java程序和MySQL表中字段的属性匹配不一致 我的报错是Can not set ja ...
- 使用dotnet-monitor sidecar模式 dump docker运行的dotnet程序.
前情概要 随着容器和云技术的发展, 大量的应用运行在云上的容器中, 它们的好处是毋庸置疑的, 例如极大的提高了我们的研发部署速度, 快速的扩缩容等等, 但是也存在一些小小的问题, 例如难以调试. 基于 ...
- C#中Enum的用法
1.定义枚举类型 public enum Test { 男 = 0, 女 = 1 } 2.获取枚举值 public void EnumsAction() { var s = Test.男;//男 va ...
- MongoDB - 简单了解
什么是 NoSQL NoSQL 是一种非关系型数据库管理系统,不需要固定的架构,可以避免 JOIN 连接,并且易于扩展. NoSQL 常用于具有庞大数据存储需求的分布式数据存储,通常是大数据和实时 W ...
- 云原生之旅 - 10)手把手教你安装 Jenkins on Kubernetes
前言 谈到持续集成工具就离不开众所周知的Jenkins,本文带你了解如何在 Kubernetes 上安装 Jenkins,后续文章会带你深入了解如何使用k8s pod 作为 Jenkins的build ...
- 【题解】UVA10228 A Star not a Tree?
题面传送门 解决思路 本题数据范围较小,可以使用模拟退火算法(随机化). 顾名思义,模拟退火就是一个类似于降温的过程.先设置一个较大的初温,每次随机改变状态,若使答案更优,则采取更优答案,否则根据其与 ...