Python网页信息采集:使用PhantomJS采集淘宝天猫商品内容

1,引言
最近一直在看Scrapy 爬虫框架,并尝试使用Scrapy框架写一个可以实现网页信息采集的简单的小程序。尝试过程中遇到了很多小问题,希望大家多多指教。
本文主要介绍如何使用Scrapy结合PhantomJS采集天猫商品内容,文中自定义了一个DOWNLOADER_MIDDLEWARES,用来采集需要加载js的动态网页内容。看了很多介绍DOWNLOADER_MIDDLEWARES资料,总结来说就是使用简单,但会阻塞框架,所以性能方面不佳。一些资料中提到了自定义DOWNLOADER_HANDLER或使用scrapyjs可以解决阻塞框架的问题,有兴趣的小伙伴可以去研究一下,这里就不多说了。
2,具体实现
2.1,环境需求
需要执行以下步骤,准备Python开发和运行环境:
- Python--官网下载安装并部署好环境变量 (本文使用Python版本为3.5.1)
- lxml-- 官网库下载对应版本的.whl文件,然后命令行界面执行 "pip install .whl文件路径"
- Scrapy--命令行界面执行 "pip install Scrapy",详细请参考《Scrapy的第一次运行测试》
- selenium--命令行界面执行 "pip install selenium"
- PhantomJS -- 官网下载
上述步骤展示了两种安装:1,安装下载到本地的wheel包;2,用Python安装管理器执行远程下载和安装。注:包的版本需要和python版本配套
2.2,开发和测试过程
首先找到需要采集的网页,这里简单找了一个天猫商品,网址https://world.tmall.com/item/526449276263.htm, 页面如下:
然后开始编写代码,以下代码默认都是在命令行界面执行
1),创建scrapy爬虫项目tmSpider
E:\python-3.5.1>scrapy startproject tmSpider
2),修改settings.py配置
- 更改ROBOTSTXT_OBEY的值为False;
- 关闭scrapy默认的下载器中间件;
- 加入自定义DOWNLOADER_MIDDLEWARES。
配置如下:
DOWNLOADER_MIDDLEWARES = {
'tmSpider.middlewares.middleware.CustomMiddlewares': 543,
'scrapy.contrib.downloadermiddleware.useragent.UserAgentMiddleware': None
}
3),在项目目录下创建middlewares文件夹,然后在文件夹下创建middleware.py文件,代码如下:
# -*- coding: utf-8 -*- from scrapy.exceptions import IgnoreRequest
from scrapy.http import HtmlResponse, Response import tmSpider.middlewares.downloader as downloader class CustomMiddlewares(object):
def process_request(self, request, spider):
url = str(request.url)
dl = downloader.CustomDownloader()
content = dl.VisitPersonPage(url)
return HtmlResponse(url, status = 200, body = content) def process_response(self, request, response, spider):
if len(response.body) == 100:
return IgnoreRequest("body length == 100")
else:
return response
4),使用selenium和PhantomJS写一个网页内容下载器,同样在上一步创建好的middlewares文件夹中创建downloader.py文件,代码如下:
# -*- coding: utf-8 -*-
import time
from scrapy.exceptions import IgnoreRequest
from scrapy.http import HtmlResponse, Response
from selenium import webdriver
import selenium.webdriver.support.ui as ui class CustomDownloader(object):
def __init__(self):
# use any browser you wish
cap = webdriver.DesiredCapabilities.PHANTOMJS
cap["phantomjs.page.settings.resourceTimeout"] = 1000
cap["phantomjs.page.settings.loadImages"] = True
cap["phantomjs.page.settings.disk-cache"] = True
cap["phantomjs.page.customHeaders.Cookie"] = 'SINAGLOBAL=3955422793326.2764.1451802953297; '
self.driver = webdriver.PhantomJS(executable_path='F:/phantomjs/bin/phantomjs.exe', desired_capabilities=cap)
wait = ui.WebDriverWait(self.driver,10) def VisitPersonPage(self, url):
print('正在加载网站.....')
self.driver.get(url)
time.sleep(1)
# 翻到底,详情加载
js="var q=document.documentElement.scrollTop=10000"
self.driver.execute_script(js)
time.sleep(5)
content = self.driver.page_source.encode('gbk', 'ignore')
print('网页加载完毕.....')
return content def __del__(self):
self.driver.quit()
5) 创建爬虫模块
在项目目录E:\python-3.5.1\tmSpider,执行如下代码:
E:\python-3.5.1\tmSpider>scrapy genspider tmall 'tmall.com'
执行后,项目目录E:\python-3.5.1\tmSpider\tmSpider\spiders下会自动生成tmall.py程序文件。该程序中parse函数处理scrapy下载器返回的网页内容,采集网页信息的方法可以是:
- 使用xpath或正则方式从response.body中采集所需字段,
- 通过gooseeker api获取的内容提取器实现一站转换所有字段,而且不用手工编写转换用的xpath(如何获取内容提取器请参考python使用xslt提取网页数据),代码如下:
# -*- coding: utf-8 -*-
import time
import scrapy import tmSpider.gooseeker.gsextractor as gsextractor class TmallSpider(scrapy.Spider):
name = "tmall"
allowed_domains = ["tmall.com"]
start_urls = (
'https://world.tmall.com/item/526449276263.htm',
) # 获得当前时间戳
def getTime(self):
current_time = str(time.time())
m = current_time.find('.')
current_time = current_time[0:m]
return current_time def parse(self, response):
html = response.body
print("----------------------------------------------------------------------------")
extra=gsextractor.GsExtractor()
extra.setXsltFromAPI("31d24931e043e2d5364d03b8ff9cc77e", "淘宝天猫_商品详情30474","tmall","list") result = extra.extract(html)
print(str(result).encode('gbk', 'ignore').decode('gbk'))
#file_name = 'F:/temp/淘宝天猫_商品详情30474_' + self.getTime() + '.xml'
#open(file_name,"wb").write(result)
6),启动爬虫
在E:\python-3.5.1\tmSpider项目目录下执行命令
E:\python-3.5.1\simpleSpider>scrapy crawl tmall
输出结果:
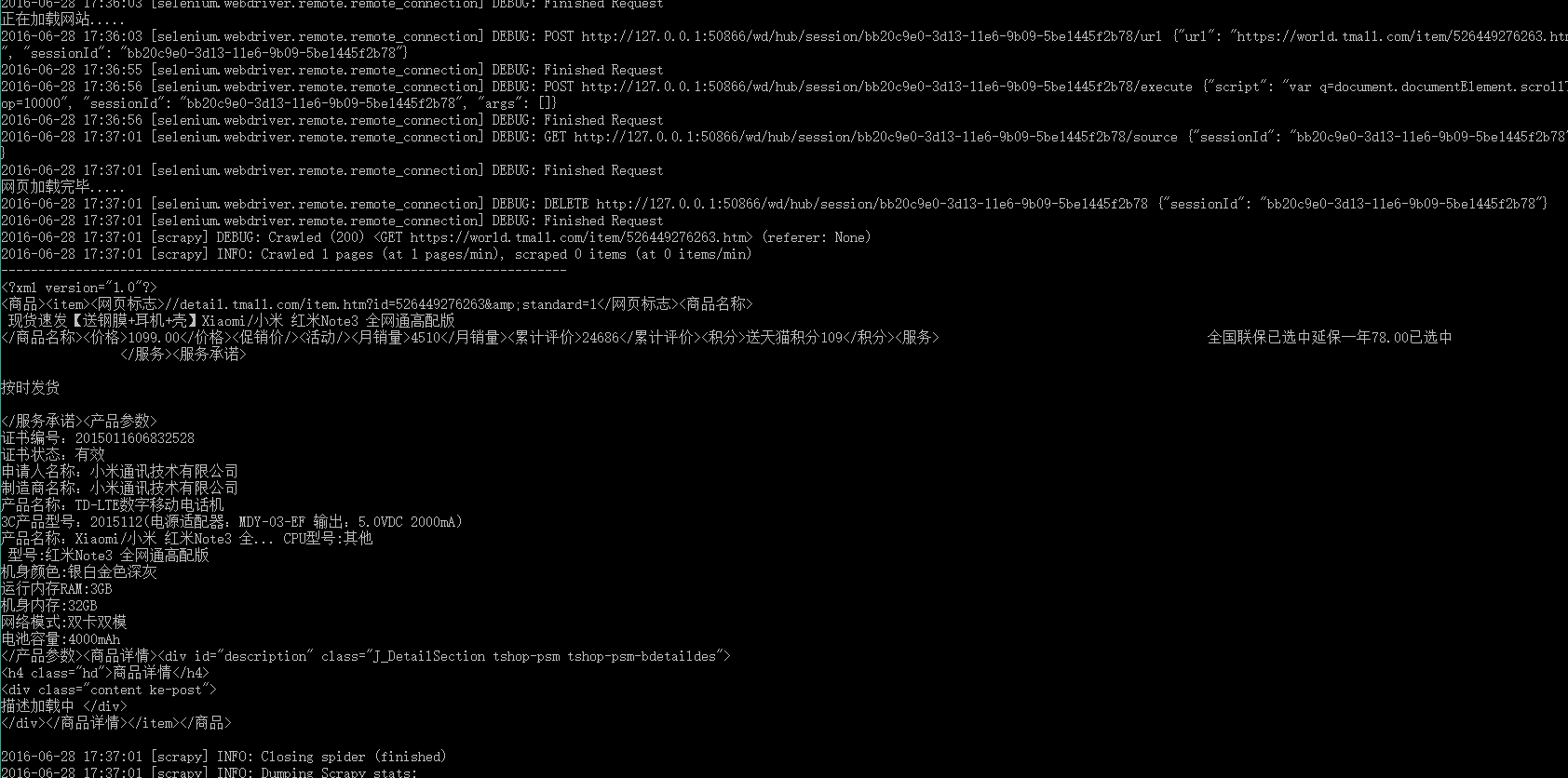
提一下,上述命令只能一次启动一个爬虫,如果想同时启动多个呢?那就需要自定义一个爬虫启动模块了,在spiders下创建模块文件runcrawl.py,代码如下
# -*- coding: utf-8 -*- import scrapy
from twisted.internet import reactor
from scrapy.crawler import CrawlerRunner from tmall import TmallSpider
...
spider = TmallSpider(domain='tmall.com')
runner = CrawlerRunner()
runner.crawl(spider)
...
d = runner.join()
d.addBoth(lambda _: reactor.stop())
reactor.run()
执行runcrawl.py文件,输出结果:

3,展望
以自定义DOWNLOADER_MIDDLEWARES调用PhantomJs的方式实现爬虫后,在阻塞框架的问题上纠结了很长的时间,一直在想解决的方式。后续会研究一下scrapyjs,splash等其他调用浏览器的方式看是否能有效的解决这个问题。
4,相关文档
5,集搜客GooSeeker开源代码下载源
1, GooSeeker开源Python网络爬虫GitHub源
6,文档修改历史
1,2016-07-06:V1.0
Python网页信息采集:使用PhantomJS采集淘宝天猫商品内容的更多相关文章
- 简单的抓取淘宝关键字信息、图片的Python爬虫|Python3中级玩家:淘宝天猫商品搜索爬虫自动化工具(第一篇)
Python3中级玩家:淘宝天猫商品搜索爬虫自动化工具(第一篇) 淘宝改字段,Bugfix,查看https://github.com/hunterhug/taobaoscrapy.git 由于Gith ...
- 利用nodejs+phantomjs+casperjs采集淘宝商品的价格
因为一些业务需求需要采集淘宝店铺商品的销售价格,但是淘宝详情页面的价格显示是通过js动态调用显示的.所以就没法通过普通的获取页面html然后通过正则或者xpath的方式获取到想到的信息了. 所幸我们现 ...
- Linux C程序操作Mysql 调用PHP采集淘宝商品 (转)
还是继续这个项目. 在上一篇Linux下利用Shell使PHP并发采集淘宝产品中,采用shell将对PHP的调用推到后台执行,模拟多线程. 此方法有一致命缺点,只能人工预判每个程序执行时间.如果判断时 ...
- Linux下利用Shell使PHP并发采集淘宝产品
上次项目中用到<<PHP采集淘宝商品>> 此方法有一个缺点,就是执行效率问题.一个商品采集平均需要0.8秒.那10000个商品采集完需要2个半小时. 首先想到的解决办法是并发. ...
- PHP采集淘宝商品
项目需求: 1.通过PHP程序更新所采集淘宝商品的价格以及是否停售 数据表: CREATE TABLE `goods` ( `id` ) NOT NULL AUTO_INCREMENT , `type ...
- Linux C程序操作Mysql 调用PHP采集淘宝商品
还是继续这个项目. 在上一篇Linux下利用Shell使PHP并发采集淘宝产品中,采用shell将对PHP的调用推到后台执行,模拟多线程. 此方法有一致命缺点,只能人工预判每个程序执行时间.如果判断时 ...
- selenium+PhantomJS 抓取淘宝搜索商品
最近项目有些需求,抓取淘宝的搜索商品,抓取的品类还多.直接用selenium+PhantomJS 抓取淘宝搜索商品,快速完成. #-*- coding:utf-8 -*-__author__ =''i ...
- 淘宝天猫关键词SEO优化
淘宝天猫的网站完全像是一个成熟的搜索引擎,只是从google.bing.baidu改成了淘宝天猫而已,普通搜索引擎有品专,有皇冠,有PC,有无线:淘宝天猫里面有钻展,有直通车,也有PC,无线.搜索引擎 ...
- 手把手教你写电商爬虫-第四课 淘宝网商品爬虫自动JS渲染
版权声明:本文为博主原创文章,未经博主允许不得转载. 系列教程: 手把手教你写电商爬虫-第一课 找个软柿子捏捏 手把手教你写电商爬虫-第二课 实战尚妆网分页商品采集爬虫 手把手教你写电商爬虫-第三课 ...
随机推荐
- HTML5 canvas 在线画笔绘图工具(一)
HTML5 canvas 在线画笔绘图工具(一) 功能介绍 这是我用Javascript写的第一个程序,在写的过程中走了很多弯路,所以写完之后想分享出来,给与我一样的初学者做为学习的参考,同时在编写这 ...
- python 连接操作数据库(一)
一.下面我们所说的就是连接mysql的应用: 1.其实在python中连接操作mysql的模块有多个,在这里我只给大家演示pymysql这一个模块(其实我是感觉它比较好用而已): pymysql是第三 ...
- 异常处理与调试6 - 零基础入门学习Delphi55(完)
调试(Debug) 让编程改变世界 Change the world by program 使用调试窗口 为方便调式程序,Delphi中提供了许多调试窗口,给开发人员的调试工作带来了极大的便利. 断点 ...
- Light OJ 1067 Combinations (乘法逆元)
Description Given n different objects, you want to take k of them. How many ways to can do it? For e ...
- hdu 4501 小明系列故事——买年货_二维背包
题目:你可以有v1元,v2代金券,v3个物品免单,现在有n个商品,商品能用纸币或者代金券购买,当然你可以买v3个商品免费.问怎么最大能买多少价值 题意: 思路二维背包,dp[v1][v2][v3]=M ...
- rnqoj-49-加分二叉树-(区域动归+记忆化)
区域动归的问题 #include<stdio.h> #include<string.h> #include<iostream> #include<algori ...
- 怎样使用LaTeX输入葡萄牙语等语言中的特殊字符
论文中引用了大名鼎鼎ER random graph model,但是这两位的名字不太好打,发现Google Scholar中直接下载的bib文件中也是错的.找了一会,发现转义字符已经定义得很好了.只是 ...
- ※数据结构※→☆非线性结构(tree)☆============二叉树 顺序存储结构(tree binary sequence)(十九)
二叉树 在计算机科学中,二叉树是每个结点最多有两个子树的有序树.通常子树的根被称作“左子树”(left subtree)和“右子树”(right subtree).二叉树常被用作二叉查找树和二叉堆或是 ...
- Struts2实现单文件上传
首先配置一下web.xml <?xml version="1.0" encoding="UTF-8"?> <web-app xmlns:xsi ...
- 在Eclipse中用SWT设计界面
摘自http://www.tulaoshi.com/n/20160129/1488574.html 在Eclipse中用SWT设计界面 1. 为什么要使用SWT? SWT是一个IBM开发的跨平台GU ...