机器学习实战笔记-11-Apriori与FP-Growth算法
Apriori算法
优点:易编码实现;缺点:大数据集上较慢;适用于:数值型或标称型数据。
关联分析:寻找频繁项集(经常出现在一起的物品的集合)或关联规则(两种物品之间的关联关系)。
概念:支持度:数据集中包含某项集的记录所占的比例P(A);可信度(置信度):对某个关联规则\(A\rightarrow B\),\(\frac{P\left( \text{AB} \right)}{P(A)}\)表示。
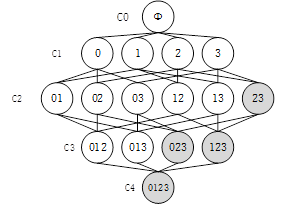
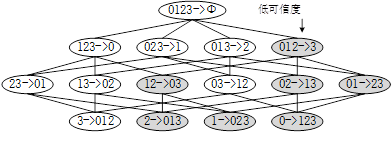
Apriori原理:频繁项集的子集一定是频繁项集,非频繁项集的超集一定是非频繁项集。
Apriori算法(目的:发现频繁项集),辅助函数”检查是否频繁项集”伪代码:
对数据集中每条交易记录transaction:
对每个候选项集can:
检查can是否是tran的子集:
如果是,则增加can项集的计数值
对每个候选项集can:
如果支持度不低于最小值(参数),则保留该项集
返回所有频繁项集列表,支持度词典
Apriori算法(目的:发现频繁项集),伪代码:
生成C1项集(只有1个元素的项集)
利用辅助函数过滤掉C1的非频繁项集
当项集列表$C_{k - 1}$中项集的个数大于0时:
构建候选项集的列表$C_{k}$(用$C_{k - 1}$构建$C_{k}$:$C_{k -1}$中项集两两比较,如果前$k -2$个元素均一样,则可以合并为一个大小为$k$的项集)
检查数据集以确认每个$C_{k}$的项集均为频繁的
保存该频繁项集列表$C_{k}$
K++
FP-growth算法(Frequency
Pattern-Growth):较Apriori更快,但实现较之困难,适用于标称型。第一次遍历数据集统计每个元素项的频率>>去掉小于最小支持度的元素项>>按频率(从大到小)对元素项进行排序>>按该顺序对数据集中各条数据进行排序>>|构建FP树|读入每个项集并将其添加到一条已存在的路径中,如果该路径不存在,则创建一条新路径>>抽取条件模式基(以所查元素为结尾的路径的集合)>>以条件模式基为每一个元素项创建一个条件FP树(每步进行最小支持度的检查)>>在该条件FP树中的两两组合项集挖掘条件FP树,即重复以上两步直到条件树没有元素为止。
机器学习实战笔记-11-Apriori与FP-Growth算法的更多相关文章
- 机器学习(十五)— Apriori算法、FP Growth算法
1.Apriori算法 Apriori算法是常用的用于挖掘出数据关联规则的算法,它用来找出数据值中频繁出现的数据集合,找出这些集合的模式有助于我们做一些决策. Apriori算法采用了迭代的方法,先搜 ...
- 机器学习实战笔记-k-近邻算法
机器学习实战笔记-k-近邻算法 目录 1. k-近邻算法概述 2. 示例:使用k-近邻算法改进约会网站的配对效果 3. 示例:手写识别系统 4. 小结 本章介绍了<机器学习实战>这本书中的 ...
- FP—Growth算法
FP_growth算法是韩家炜老师在2000年提出的关联分析算法,该算法和Apriori算法最大的不同有两点: 第一,不产生候选集,第二,只需要两次遍历数据库,大大提高了效率,用31646条测试记录, ...
- Frequent Pattern 挖掘之二(FP Growth算法)(转)
FP树构造 FP Growth算法利用了巧妙的数据结构,大大降低了Aproir挖掘算法的代价,他不需要不断得生成候选项目队列和不断得扫描整个数据库进行比对.为了达到这样的效果,它采用了一种简洁的数据结 ...
- 关联规则算法之FP growth算法
FP树构造 FP Growth算法利用了巧妙的数据结构,大大降低了Aproir挖掘算法的代价,他不需要不断得生成候选项目队列和不断得扫描整个数据库进行比对.为了达到这样的效果,它采用了一种简洁的数据结 ...
- Frequent Pattern (FP Growth算法)
FP树构造 FP Growth算法利用了巧妙的数据结构,大大降低了Aproir挖掘算法的代价,他不需要不断得生成候选项目队列和不断得扫描整个数据库进行比对.为了达 到这样的效果,它采用了一种简洁的数据 ...
- Frequent Pattern 挖掘之二(FP Growth算法)
Frequent Pattern 挖掘之二(FP Growth算法) FP树构造 FP Growth算法利用了巧妙的数据结构,大大降低了Aproir挖掘算法的代价,他不需要不断得生成候选项目队列和不断 ...
- 机器学习实战笔记(Python实现)-00-readme
近期学习机器学习,找到一本不错的教材<机器学习实战>.特此做这份学习笔记,以供日后翻阅. 机器学习算法分为有监督学习和无监督学习.这本书前两部分介绍的是有监督学习,第三部分介绍的是无监督学 ...
- 机器学习实战笔记(Python实现)-08-线性回归
--------------------------------------------------------------------------------------- 本系列文章为<机器 ...
- 机器学习实战笔记(Python实现)-06-AdaBoost
--------------------------------------------------------------------------------------- 本系列文章为<机器 ...
随机推荐
- [BZOI 3994] [SDOI2015]约数个数和(莫比乌斯反演+数论分块)
[BZOI 3994] [SDOI2015]约数个数和 题面 设d(x)为x的约数个数,给定N.M,求\(\sum _{i=1}^n \sum_{i=1}^m d(i \times j)\) T组询问 ...
- LeetCode Lect7 堆及其应用
概述 堆是一颗完全二叉树.分为大根堆(父节点>=所有的子节点)和小根堆(父节点<=所有的子节点). 插入.删除堆顶都是O(logN),查询最值是O(1). 完全二叉树(Complete B ...
- ASP.NET MVC @html帮助类
原文:https://www.cnblogs.com/caofangsheng/p/10462494.html HTML Helpers是用来创建HTML标签进而创建HTML控件的.HTML Help ...
- IOC详解
Ioc--控制反转详解(转载 http://www.cnblogs.com/qinqinmeiren/archive/2011/04/02/2151697.html) 本文转载与百度知道,简单例子让 ...
- 06-JavaScript简介
### 前段三大块 ```HTML css JavaScript``` ### 什么是JavaScript? JavaScript是运行在浏览器端的脚步语言,JavaScript主要解决的是前端与用户 ...
- 利用vsftpd在Linux构建安全的FTP服务
最近在机房搭建Linux环境,需要用到了FTP服务,查看了许多的资料,在这里做一下笔记 一.安装 方法一,使用yum命令安装,需要能够连接外网 # yum install vsftpd 方法二,使用安 ...
- org.springframework.beans.factory.NoSuchBeanDefinitionException: No qualifying bean of type [dx.service.ItemService] found for dependency
在整合ssm框架,测试service层的时候报错 Caused by: org.springframework.beans.factory.NoSuchBeanDefinitionException: ...
- JavaScript中准确的判断数据类型
在 ECMAScript 规范中,共定义了 7 种数据类型,分为基本类型和引用类型两大类. 其中: 基本类型:String.Number.Boolean.Symbol.Undefined.Null ...
- 2018-9-21-dot-net-core-使用-usb
title author date CreateTime categories dot net core 使用 usb lindexi 2018-09-21 19:53:34 +0800 2018-0 ...
- pppd - 点对点协议守护进程
总览 SYNOPSIS pppd [ tty_name ] [ speed ] [ options ] 描述 点对点协议 (PPP) 提供一种在点对点串列线路上传输资料流 (datagrams)的方法 ...