Scrapy学习(一)、Scrapy框架和数据流
Scrapy是用python写的爬虫框架,架构图如下:
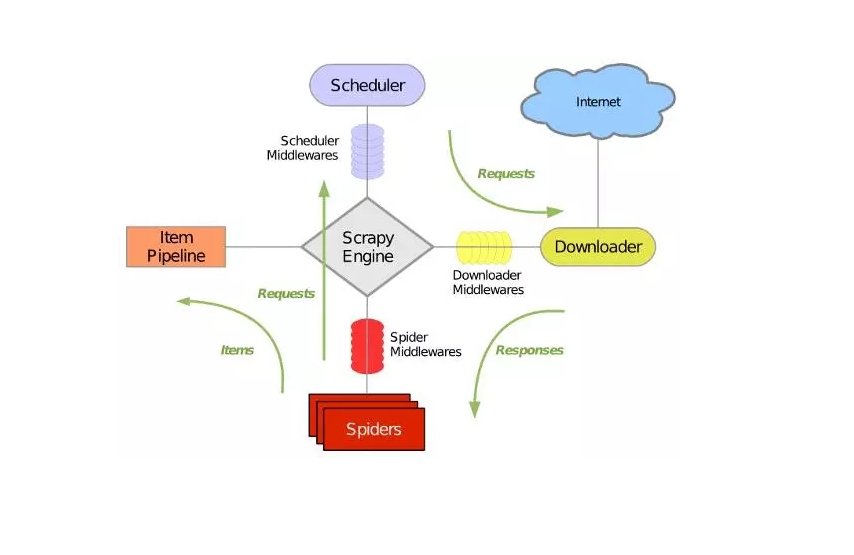
它可以分为如下七个部分:
1、Scrapy Engine:引擎,负责控制数据流在系统的所有组件中流动,并在相应动作发生时触发时间。
2、Scheduler:调度器,从引擎接收Request并将它们入队,以便引擎再次请求Request时提供给引擎。
3、Downloader:下载器,负责获取页面数据并提供给引擎,而后提供给Spiders。
4、Spider:爬虫,定义爬虫逻辑和解析规则,主要负责解析Response并生成提取结果(item)和新的请求(Request)。
5、Item Pipeline:管道,负责处理右Spider提取出来的结果(item)。主要任务是清洗,验证和存储数据。
6、Downloader middlewares:下载器中间件,位于引擎和下载器之间的特定钩子,处理引擎传给下载器的Request以及下载器传给引擎的Response。
7、Spider middlewares:爬虫中间件,位于引擎和爬虫之间的特定钩子,主要处理爬虫的输入(Response)和输出(Item和Request)
具体数据流如下:
1、引擎(Scrapy Engine)打开一个网站,找到处理该网站的Spider,并向该Spider请求第一个要爬取的URL
2、引擎(Scrapy Engine)从Spider中获取到第一个要爬取的URL后,通过调度器(Scheduler)以Request的形式调度
3、引擎(Scrapy Engine)向调度器(Scheduler)请求下一个要爬取的URL
4、调度器(Scheduler)返回下一个要爬取的URL给引擎(Scrapy Engine),引擎将该URL通过下载中间件(Downloader middlewares)转发给下载器(Downloader)
5、下载器(Downloader)下载页面,一旦页面下载完毕,下载器生成一个该页面的Response,并将其通过下载中间件(Downloader middlewares)发送给引擎
6、引擎(Scrapy Engine)从下载中间件(Downloader middlewares)接收Response,并将其通过爬虫中间件(Spider middlewares)发送给爬虫(Spider)处理
7、爬虫(Spider)处理Response,并返回处理的Item及新的Request给引擎
8、引擎(Scrapy Engine)将爬虫(Spider)返回的Item给管道(Item Pipeline),将新的Request给调度器(Scheduler)
9、重复第2步到第8步,直到调度器(Scheduler)中没有更多的Request,引擎(Scrapy Engine)关闭该网站,爬虫结束
Scrapy学习(一)、Scrapy框架和数据流的更多相关文章
- python爬虫学习之Scrapy框架的工作原理
一.Scrapy简介 Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中. 其最初是为了 页面抓取 (更确切来说, 网 ...
- Python爬虫框架Scrapy学习笔记原创
字号 scrapy [TOC] 开始 scrapy安装 首先手动安装windows版本的Twisted https://www.lfd.uci.edu/~gohlke/pythonlibs/#twi ...
- python爬虫之Scrapy学习
在爬虫的路上,学习scrapy是一个必不可少的环节.也许有好多朋友此时此刻也正在接触并学习scrapy,那么很好,我们一起学习.开始接触scrapy的朋友可能会有些疑惑,毕竟是一个框架,上来不知从何学 ...
- 爬虫系列---scrapy post请求、框架组件和下载中间件+boss直聘爬取
一 Post 请求 在爬虫文件中重写父类的start_requests(self)方法 父类方法源码(Request): def start_requests(self): for url in se ...
- Scrapy学习篇(十)之下载器中间件(Downloader Middleware)
下载器中间件是介于Scrapy的request/response处理的钩子框架,是用于全局修改Scrapy request和response的一个轻量.底层的系统. 激活Downloader Midd ...
- scrapy 学习笔记1
最近一段时间开始研究爬虫,后续陆续更新学习笔记 爬虫,说白了就是获取一个网页的html页面,然后从里面获取你想要的东西,复杂一点的还有: 反爬技术(人家网页不让你爬,爬虫对服务器负载很大) 爬虫框架( ...
- scrapy学习(完全版)
scrapy1.6中文文档 scrapy1.6中文文档 scrapy中文文档 Scrapy框架 下载页面 解析页面 并发 深度 安装 scrapy学习教程 如果安装了anconda,可以在anacon ...
- scrapy学习笔记(二)框架结构工作原理
scrapy结构图: scrapy组件: ENGINE:引擎,框架的核心,其它所有组件在其控制下协同工作. SCHEDULER:调度器,负责对SPIDER提交的下载请求进行调度. DOWNLOADER ...
- Scrapy (网络爬虫框架)入门
一.Scrapy 简介: Scrapy是用纯Python实现一个为了爬取网站数据.提取结构性数据而编写的应用框架,Scrapy 使用了 Twisted['twɪstɪd](其主要对手是Tornado) ...
随机推荐
- 【经典问题】maximum subset sum of vectors
AtCoder Beginner Contest 139 Task F Engines 题目大意 给定 $n$ 个二维向量,从中选出若干个,使得它们的和的模最大. 分析 这是一个经典问题,还有一种提法 ...
- 基于 Vue.js 2.0 酷炫自适应背景视频登录页面的设计『转』
本文讲述如何实现拥有酷炫背景视频的登录页面,浏览器窗口随意拉伸,背景视频及前景登录组件均能完美适配,背景视频可始终铺满窗口,前景组件始终居中,视频的内容始终得到最大限度的保留,可以得到最好的视觉效果. ...
- vue-router和webpack懒加载,页面性能优化篇
在vue单页应用中,当项目不断完善丰富时,即使使用webpack打包,文件依然是非常大的,影响页面的加载.如果我们能把不同路由对应的组件分割成不同的代码块,当路由被访问时才加载对应的组件(也就是按需加 ...
- 网络信息统计netstat|ss|ip
1:netstate[弃用] netstat的作用: 需求 原命令 新命令 1:网络连接 netstat -a ss 2:路由表 netstat -r ip route 3:统计接口 netstat ...
- golang 多线程查找文件内容
package main import ( "fmt" "io/ioutil" "os" "path/filepath" ...
- java中内部类
package com.xt.instanceoftest; import com.xt.instanceoftest.Body.Heart; public class StaticInnerClas ...
- 如何同步多个 git 远程仓库
请看 -> 如何同步多个 git 远程仓库
- Charles学习(四)之使用Map local代理本地静态资源以及配置移动端代理在真机上调试iOS和Android客户端
前言 问题一:我们在App内嵌H5开发的过程中,肯定会遇到一个问题就是我不想在chrome的控制台中调试也不想在模拟器中调试,我想要在真机上调试,那么如何解决这个问题呢? 问题二:我们期待调试时达到的 ...
- Uncaught SyntaxError: Unexpected identifier
$.ajax({ //请求头 type:"POST", contentType:"application/x-www-form-urlencoded", url ...
- 从FBV到CBV三(权限)
丛FBC到CBV三(权限) span::selection, .CodeMirror-line > span > span::selection { background: #d7d4f0 ...