Scrapy学习(一)、Scrapy框架和数据流
Scrapy是用python写的爬虫框架,架构图如下:
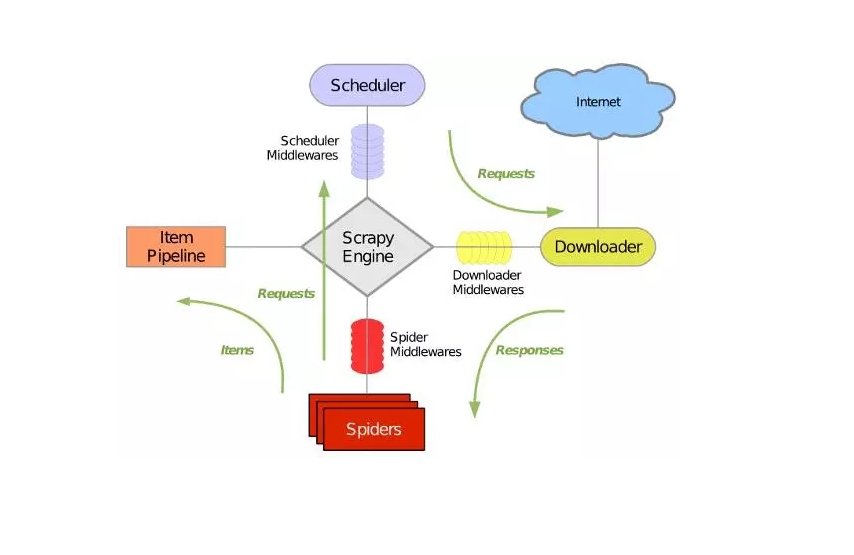
它可以分为如下七个部分:
1、Scrapy Engine:引擎,负责控制数据流在系统的所有组件中流动,并在相应动作发生时触发时间。
2、Scheduler:调度器,从引擎接收Request并将它们入队,以便引擎再次请求Request时提供给引擎。
3、Downloader:下载器,负责获取页面数据并提供给引擎,而后提供给Spiders。
4、Spider:爬虫,定义爬虫逻辑和解析规则,主要负责解析Response并生成提取结果(item)和新的请求(Request)。
5、Item Pipeline:管道,负责处理右Spider提取出来的结果(item)。主要任务是清洗,验证和存储数据。
6、Downloader middlewares:下载器中间件,位于引擎和下载器之间的特定钩子,处理引擎传给下载器的Request以及下载器传给引擎的Response。
7、Spider middlewares:爬虫中间件,位于引擎和爬虫之间的特定钩子,主要处理爬虫的输入(Response)和输出(Item和Request)
具体数据流如下:
1、引擎(Scrapy Engine)打开一个网站,找到处理该网站的Spider,并向该Spider请求第一个要爬取的URL
2、引擎(Scrapy Engine)从Spider中获取到第一个要爬取的URL后,通过调度器(Scheduler)以Request的形式调度
3、引擎(Scrapy Engine)向调度器(Scheduler)请求下一个要爬取的URL
4、调度器(Scheduler)返回下一个要爬取的URL给引擎(Scrapy Engine),引擎将该URL通过下载中间件(Downloader middlewares)转发给下载器(Downloader)
5、下载器(Downloader)下载页面,一旦页面下载完毕,下载器生成一个该页面的Response,并将其通过下载中间件(Downloader middlewares)发送给引擎
6、引擎(Scrapy Engine)从下载中间件(Downloader middlewares)接收Response,并将其通过爬虫中间件(Spider middlewares)发送给爬虫(Spider)处理
7、爬虫(Spider)处理Response,并返回处理的Item及新的Request给引擎
8、引擎(Scrapy Engine)将爬虫(Spider)返回的Item给管道(Item Pipeline),将新的Request给调度器(Scheduler)
9、重复第2步到第8步,直到调度器(Scheduler)中没有更多的Request,引擎(Scrapy Engine)关闭该网站,爬虫结束
Scrapy学习(一)、Scrapy框架和数据流的更多相关文章
- python爬虫学习之Scrapy框架的工作原理
一.Scrapy简介 Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中. 其最初是为了 页面抓取 (更确切来说, 网 ...
- Python爬虫框架Scrapy学习笔记原创
字号 scrapy [TOC] 开始 scrapy安装 首先手动安装windows版本的Twisted https://www.lfd.uci.edu/~gohlke/pythonlibs/#twi ...
- python爬虫之Scrapy学习
在爬虫的路上,学习scrapy是一个必不可少的环节.也许有好多朋友此时此刻也正在接触并学习scrapy,那么很好,我们一起学习.开始接触scrapy的朋友可能会有些疑惑,毕竟是一个框架,上来不知从何学 ...
- 爬虫系列---scrapy post请求、框架组件和下载中间件+boss直聘爬取
一 Post 请求 在爬虫文件中重写父类的start_requests(self)方法 父类方法源码(Request): def start_requests(self): for url in se ...
- Scrapy学习篇(十)之下载器中间件(Downloader Middleware)
下载器中间件是介于Scrapy的request/response处理的钩子框架,是用于全局修改Scrapy request和response的一个轻量.底层的系统. 激活Downloader Midd ...
- scrapy 学习笔记1
最近一段时间开始研究爬虫,后续陆续更新学习笔记 爬虫,说白了就是获取一个网页的html页面,然后从里面获取你想要的东西,复杂一点的还有: 反爬技术(人家网页不让你爬,爬虫对服务器负载很大) 爬虫框架( ...
- scrapy学习(完全版)
scrapy1.6中文文档 scrapy1.6中文文档 scrapy中文文档 Scrapy框架 下载页面 解析页面 并发 深度 安装 scrapy学习教程 如果安装了anconda,可以在anacon ...
- scrapy学习笔记(二)框架结构工作原理
scrapy结构图: scrapy组件: ENGINE:引擎,框架的核心,其它所有组件在其控制下协同工作. SCHEDULER:调度器,负责对SPIDER提交的下载请求进行调度. DOWNLOADER ...
- Scrapy (网络爬虫框架)入门
一.Scrapy 简介: Scrapy是用纯Python实现一个为了爬取网站数据.提取结构性数据而编写的应用框架,Scrapy 使用了 Twisted['twɪstɪd](其主要对手是Tornado) ...
随机推荐
- 入职一个月快速熟悉大型Vue项目经验感想
来到和睦的公司家庭已经一个月出头了,从技术层面来说,公司项目PC端是我目前来说接触的最大最复杂的项目了,德老师也说这个不断开发更新迭代的项目的代码量相对于全国的web来说是蛮多的,对于快速熟悉这样的大 ...
- 多个div排列在同一行而不换行
有时候,我们可能会产生多个div标签横向排列而不换行的需求,具体有以下几种实现方法: 1. 同级div设置display:inline-block,父级div强制不换行例如: <html> ...
- LCT做题笔记
最近几天打算认真复习LCT,毕竟以前只会板子.正好也可以学点新的用法,这里就用来写做题笔记吧.这个分类比较混乱,主要看感觉,不一定对: 维护森林的LCT 就是最普通,最一般那种的LCT啦.这类题目往往 ...
- windows下php配置环境变量
这样重启终端后,通过php -v可查看新使用的php版本信息. 注:在path配置在上方的先生效
- SpringDataJpa实体类常用注解
最近公司在使用SpringDataJpa时,需要创建实体类,通过实体类来创建数据库表结构,生成数据库表. 下面我们就来看下在创建实体类时一些常用的注解吧!!! 1.实体类常用注解 @Entity 标识 ...
- 分布式的几件小事(二)dubbo的工作原理
1.dubbo的工作原理 ①整体设计 图例说明: 图中左边淡蓝背景的为服务消费方使用的接口,右边淡绿色背景的为服务提供方使用的接口,位于中轴线上的为双方都用到的接口. 图中从下至上分为十层,各层均为单 ...
- 如何在万亿级别规模的数据量上使用Spark
一.前言 Spark作为大数据计算引擎,凭借其快速.稳定.简易等特点,快速的占领了大数据计算的领域.本文主要为作者在搭建使用计算平台的过程中,对于Spark的理解,希望能给读者一些学习的思路.文章内容 ...
- CentOS下安装DockerCE
title: CentOS下安装DockerCE comments: false date: 2019-09-04 09:47:58 description: 在CentOS下安装社区版Docker ...
- JVM--对象访问和OutOfMemoryError异常
对象访问: 使用句柄访问方式: 使用直接指针访问方式: OutOfMemoryError异常: 设置堆的最小最大容量:-Xms20m -Xmx20m 设置一样推不可自动扩展. 设置出现内存溢出 ...
- Caffe常用算子GPU和CPU对比
通过整理LeNet.AlexNet.VGG16.googLeNet.ResNet.MLP统计出的常用算子(不包括ReLU),表格是对比. Prelu Cpu版 Gpu版 for (int i = 0; ...