python openpyxl 简单使用
1. 加载excel
import openpyxl
from openpyxl.utils import get_column_letter,column_index_from_string
from openpyxl.styles import Font,PatternFill
import os # 加载example.xlsx,参数data_only=False表示如果单元格是公式,则显示公式,而不是公式的计算结果
wb = openpyxl.load_workbook('example.xlsx',data_only=False) # 列出所有sheet名称,返回一个list
sheets = wb.sheetnames
print('Sheets:',sheets) # sheet对象,获取激活的sheet
activesheet = wb.active
# 打开特定的sheet
ws = wb['sheetName']
# 获取sheet的名称
print(activesheet.title) # 获取单元格对象
a1 = activesheet['A1'] # 单元格的值
print(a1.value) # 获取单元格对象的行列,以及单元格名称,coordinate返回单元格的名称。
print(a1.row,a1.column,a1.coordinate,sep=',') # 根据 行列 来定位一个单元格
a2 = activesheet.cell(row=2,column=2)
print('A2 value:',a2.value) # 获取表中的最大行数和列数
highest = activesheet.max_row
wid = activesheet.max_column
print('MaxRow,MaxCol:',highest,wid) # 转换列名和数字
print(get_column_letter(77),column_index_from_string('AA')) # 使用切片来获取一个区域,返回元组形式
field = activesheet['A1':'C3']
print('Field:',field) for x in activesheet['A1':'C3']: # 先获取元组的元素:一行的所有单元格(元组格式)
for y in x: # 再获取元组的每一个元素:单元格
print(y.coordinate,y.value) wb.save('new.xlsx') # 保存文件
2. 创建新的excel文件
import openpyxl
from openpyxl.utils import get_column_letter,column_index_from_string
from openpyxl.styles import Font,PatternFill
import os # 创建写入excel
if os.path.exists('new.xlsx'):
os.unlink('new.xlsx') # 如果存在 new.xlsx ,先删除 # 创建工作簿对象
wb = openpyxl.Workbook() # 获取激活的表单
active = wb.active # 获取sheet名称
print(active.title) # 给sheet重命名
active.title = 'Abc' # 创建带索引的sheet,也就是sheet表单的顺序,索引为1代表放在第一个
wb.create_sheet(index=1,title='New_sheet')
wb.create_sheet(index=2,title='New_sheet2') # 获取所有sheet名
sheets = wb.get_sheet_names
print(sheets) # 删除一个工作表
wb.remove(wb['New_sheet2'])
for x in range(1,100): # 写入excel
active.cell(row=x,column=1,value=x) # 设置单元格样式
active.row_dimensions[1].height = 30 # 设置行高
active.column_dimensions['A'].width = 30 #设置列宽 # 合并单元格并赋值
active.merge_cells('A1:C1')
active['A1'] = 'hebkdjyrge' #拆分单元格
active.unmerge_cells('A1:C1') # 冻结 A3 以前的单元格,即 A1 和 A2 冻结
active.freeze_panes = 'A3' # 设置字体
geui = Font(size=15,name='Arial',bold=True,italic=False,color='FFFFFF')
colorr = PatternFill('solid',bgColor='4F4F4F')
active['A1'].fill = colorr
active['A1'].font = geui # 创建图表,没搞明白
for i in range(1,11):
active['A'+str(i)] = i
refObj = openpyxl.chart.Reference(active, min_row=1, min_col=1, max_row=10, max_col=1)
seriesObj = openpyxl.chart.Series(refObj, title='First series')
chartObj = openpyxl.chart.BarChart()
chartObj.title = 'My Chart'
chartObj.append(seriesObj) active.add_chart(chartObj, 'C5') # C5表示图标开始位置 wb.save('new.xlsx') # 保存文件
3. 读取Excel的某import openpyxl
import shutil
import sys def read_Excel(file,row=2,*col):
'''
file: excel的文件名
row:默认从第几行开始,比如第一行是title,则可以从第二行开始
*col: 列名,获取哪些列的数据
'''
case_list = {}
workbook = openpyxl.load_workbook(file)
sheet0 = workbook.active # 获取当前激活的工作表
highest = sheet0.max_row # 获取表单有数据的最大行数
first_col = col[0] # 第一个列参数
for i in range(row,highest+1):
value_list = []
v1 = sheet0[first_col+str(i)].value
# 除去第一列的其他列
for j in range(1,len(col)):
v2 = sheet0[col[j]+str(i)].value
value_list.append(v2)
case_list[v1] = value_list
print(case_list)
return case_list read_Excel('结果.xlsx',2,'a','b','c')
待处理数据:
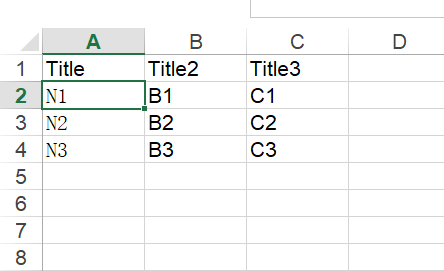
结果:
{'N1': ['B1', 'C1'], 'N2': ['B2', 'C2'], 'N3': ['B3', 'C3']}
python openpyxl 简单使用的更多相关文章
- python制作简单excel统计报表2之操作excel的模块openpyxl简单用法
python制作简单excel统计报表2之操作excel的模块openpyxl简单用法 # coding=utf-8 from openpyxl import Workbook, load_workb ...
- python制作简单excel统计报表3之将mysql数据库中的数据导入excel模板并生成统计图
python制作简单excel统计报表3之将mysql数据库中的数据导入excel模板并生成统计图 # coding=utf-8 from openpyxl import load_workbook ...
- Python爬虫简单实现CSDN博客文章标题列表
Python爬虫简单实现CSDN博客文章标题列表 操作步骤: 分析接口,怎么获取数据? 模拟接口,尝试提取数据 封装接口函数,实现函数调用. 1.分析接口 打开Chrome浏览器,开启开发者工具(F1 ...
- Python 实现简单的 Web
简单的学了下Python, 然后用Python实现简单的Web. 因为正在学习计算机网络,所以通过编程来加强自己对于Http协议和Web服务器的理解,也理解下如何实现Web服务请求.响应.错误处理以及 ...
- 用 python实现简单EXCEL数据统计
任务: 用python时间简单的统计任务-统计男性和女性分别有多少人. 用到的物料:xlrd 它的作用-读取excel表数据 代码: import xlrd workbook = xlrd.open_ ...
- python开启简单webserver
python开启简单webserver linux下面使用 python -m SimpleHTTPServer 8000 windows下面使用上面的命令会报错,Python.Exe: No Mod ...
- Python开发简单爬虫 - 慕课网
课程链接:Python开发简单爬虫 环境搭建: Eclipse+PyDev配置搭建Python开发环境 Python入门基础教程 用Eclipse编写Python程序 课程目录 第1章 课程介绍 ...
- python使用简单http协议来传送文件
python使用简单http协议来传送文件!在ubuntu环境下,局域网内可以使用nc来传送文件,也可以使用基于Http协议的方式来下载文件我们可以使用python -m SimpleHTTPServ ...
- Python超简单的HTTP服务器
Python超简单的HTTP服务器 安装了python就可以 python -m SimpleHTTPServer 执行这一个命令即可实现一个HTTP服务器,将当前目录设为HTTP服务目录,可以通过h ...
随机推荐
- IFB
本文翻译自Linux官方IFB文档 IFB(中介功能块设备)是IMQ(中介队列设备)的继任者,IMQ从来没有被集成过,IFB拥有IMQ的优点,在SMP上更加清晰明了,并且代码量缩减了非常多,旧的中介设 ...
- Tensorflow所遇坑
TensorFlow问题: 1.FLAGS._parse_flags()报错AttributeError:_parse_flags 解决: 因为TensorFlow的版本问题了,TensorFlow版 ...
- 使用zipkin2在SpringCloud2.0环境下追踪服务调用情况
1.目的: 使用zipkin2.0在Spring Cloud 2.0环境下,追踪服务调用情况. 2.所需组件: zipkin2.0,Spring Cloud 2.0,Eureka Server,Eur ...
- 如何在Ubuntu / CentOS 6.x上安装Bugzilla 4.4
这里,我们将展示如何在一台Ubuntu 14.04或CentOS 6.5/7上安装Bugzilla.Bugzilla是一款基于web,用来记录跟踪缺陷数据库的bug跟踪软件,它同时是一款免费及开源软件 ...
- PHP LDA off 解决
搭建完zabbix初始登录zabbix显示 PHP LDAP off 解决 不需要重新编译php 就可以增加 LDAP 模块 .首先进入自己的 PHP 安装目录中找到 ldap 文件夹 [root@b ...
- 【HANA系列】【第八篇】SAP HANA XS使用Data Services查询CDS实体【二】
公众号:SAP Technical 本文作者:matinal 原文出处:http://www.cnblogs.com/SAPmatinal/ 原文链接:[HANA系列][第八篇]SAP HANA XS ...
- DateTime相关
1.string数据转成datetime DateTimeFormatter forPattern = DateTimeFormat.forPattern("yyyyMMddHH" ...
- linux 使用timedatectl 修改时区和时间
使用timedatectl可以进行如下常见操作 1.查看当前时间/日期/时区:timedatectl或者timedatectl status 2.查看所有可用时区:timedatectl list-t ...
- 【转】WEB技术发展简史
[转]WEB技术发展简史 一.Web技术发展的第一阶段——静态文档 第一阶段的Web,主要是用于静态Web页面的浏览.用户使用客户机端的Web浏览器,可以访问Internet上各个Web站点,在每一个 ...
- mnist数据集下载——mnist数据集提供百度网盘下载地址
mnist数据集是由深度学习大神 LeCun等人制作完成的数据集,mnist数据集也常认为是深度学习的“ Hello World!”. 官网:http://yann.lecun.com/exdb/mn ...