Types of CQRS
Types of CQRS
By Vladimir Khorikov
CQRS is a pretty defined concept. Often, people say that you either follow CQRS or not, meaning that it is some kind of a binary choice. In this article, I’d like to show that there is some wriggle room in this notion and how different types of CQRS can look like.
Type 0: no CQRS
With this type, you don’t have any CQRS whatsoever. That means you have a domain model and you use your domain classes for both serving commands and executing queries.
Let’s say you have a Customer class:
public class Customer
{
public int Id { get; private set; }
public string Name { get; private set; }
public IReadOnlyList<Order> Orders { get; private set; }
public void AddOrder(Order order)
{
/* … */
}
/* Other methods */
}
With the type 0 of CQRS you end up with CustomerRepository class looking like this:
public class CustomerRepository
{
public void Save(Customer customer) { /* … */ }
public Customer GetById(int id) { /* … */ }
public IReadOnlyList<Customer> Search(string name) { /* … */ }
}
Search method here is a query. It is used for fetching customers’ data from database and returning it to a client (a UI layer or a separate application accessing your server through some API). Note that this method returns a list of domain objects.
The advantage of such approach is obvious: it has no code overhead. In other words, you have a single model that you use for both commands and queries and don’t have to duplicate the code at all.
The disadvantage here is that this single model is not optimized for read operations. If you need to show a list of customers in UI, you usually don’t want to display their orders. Instead, you most likely prefer to show only a brief information such as id, name and the number of orders.
The use of a domain class for transferring customers’ data from the database to UI leads to loading all their orders into memory and thus introduces a heavy overhead because UI needs the order count field only, not the orders themselves.
This type of CQRS is good for small applications with little or no performance requirements. For other types of applications, we need to move further.
Type 1: separated class structure
With this type of CQRS, you have your class structure separated for read and write operations. That means you create a set of DTOs to transfer the data you fetch from the database.
The DTO for Customer can look like this:
public class CustomerDto
{
public int Id { get; set; }
public string Name { get; set; }
public int OrderCount { get; set; }
}
The Search method now returns a list of DTOs instead of a list of domain objects:
public class CustomerRepository
{
public void Save(Customer customer) { /* … */ }
public Customer GetById(int id) { /* … */ }
public IReadOnlyList<CustomerDto> Search(string name) { /* … */ }
}
The Search method can use either an ORM or plain ADO.NET to get the data needed. This should be determined by performance requirements in each particular case. There’s no need to fall back to ADO.NET if a method’s performance is good enough.
DTOs introduce some duplication as we need to come up with the same concept twice: once for commands in a form of a domain class and once more for queries in a form of a DTO. But at the same time, they allow us to create clean and explicit data structures that perfectly align with our needs for read operations as they only contain data clients need to display. And the more explicit we are with our code, the better.
I would say that this type of CQRS is sufficient for most of enterprise applications as it gives a pretty good balance between code complexity and performance. Also, with this approach, we have some flexibility in terms of what tool to use for queries. If the performance of a method is not critical, we can use ORM and save developers’ time; otherwise, we may fall back to ADO.NET (or some lightweight ORM like Dapper) and write complex and optimized queries on our own.
If we want to continue separating our read and write models, we need to move further.
Type 2: separated model
This type of CQRS proposes using separated models and sets of API for serving read and write requests.
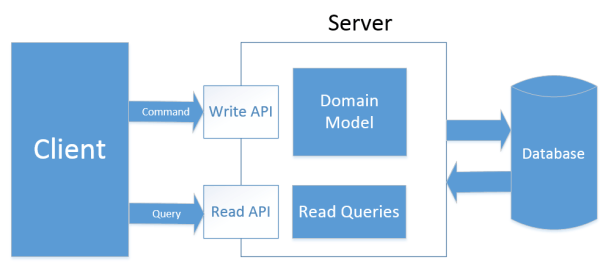
Type 2 of CQRS
That means that, in addition to DTOs, we extract all the read logic out of our model. Repository now contains only methods that regard to commands:
public class CustomerRepository
{
public void Save(Customer customer) { /* … */ }
public Customer GetById(int id) { /* … */ }
}
And the search logic resides in a separate class:
public class SearchCustomerQueryHandler
{
public IReadOnlyList<CustomerDto> Execute(SearchCustomerQuery query)
{
/* … */
}
}
This approach introduces more overhead comparing to the previous one in terms of code required to handle the complexity, but it is a good solution if you have a heavy read workload.
In addition to the ability to write optimized queries, type 2 of CQRS allows us to easily wrap read portion of API with some caching mechanism or even move read API to another server and setup a load-balancer/failover cluster. It works great if you have a massive disparity between the workload of writes and reads in your system as it allows you to scale the read part of it drastically.
If you need even more performance of read operations, you need to move to type 3 of CQRS.
Type 3: separated storage
That is the type that considered to be the true CQRS by many. To scale read operations even further, we can create a separate data storage optimized specifically for queries we have in our system. Often, such storage might be a NoSQL database like MongoDB or a replica set with several instances of it:

Type 3 of CQRS
The synchronization goes in background mode and can take some time. Such data storages are considered to be eventually consistent.
A good example here could be indexing of customers’ data with Elastic Search. Often we don’t want to use full-text search capabilities built into SQL Server as they don’t scale much. Instead, we could use non-relational data storage optimized specifically for searching customers.
Along with the best scalability for read operations, this type of CQRS brings the highest overhead. Not only should we segregate our read and write model logically, i.e. use different classes and even assemblies for it, but we also need to introduce database-level separation.
Summary
There are different types of CQRS you can leverage in your software; there’s nothing wrong with sticking to the type #1 and not moving further to the types 2 or 3 as long as the type #1 meets your application’s requirements.
I’d like to emphasize this once more: CQRS is not a binary choice. There are some different variations between not separating reads and writes at all (type 0) and separating them completely (type 3).
There should be a balance between the degree of segregation and complexity overhead it introduces. The balance itself should be found in each concrete software application apart, often after several iterations. I strongly believe that CQRS itself should not be implemented “just because we can”; it should only be brought to the table to meet concrete requirements, namely, to scale read operations of the application.
http://enterprisecraftsmanship.com/2015/04/20/types-of-cqrs/
Types of CQRS的更多相关文章
- CQRS FAQ (翻译)
我从接触ddd到学习cqrs有6年多了, 其中也遇到了不少疑问, 也向很多的前辈牛人请教得到了很多宝贵的意见和建议. 偶尔的机会看到国外有个站点专门罗列了ddd, cqrs和事件溯源的常见问题. 其中 ...
- 手撸一套纯粹的CQRS实现
关于CQRS,在实现上有很多差异,这是因为CQRS本身很简单,但是它犹如潘多拉魔盒的钥匙,有了它,读写分离.事件溯源.消息传递.最终一致性等都被引入了框架,从而导致CQRS背负了太多的混淆.本文旨在提 ...
- OnionArch - 采用DDD+CQRS+.Net 7.0实现的洋葱架构
博主最近失业在家,找工作之余,看了一些关于洋葱(整洁)架构的资料和项目,有感而发,自己动手写了个洋葱架构解决方案,起名叫OnionArch.基于最新的.Net 7.0 RC1, 数据库采用Postgr ...
- DDD CQRS架构和传统架构的优缺点比较
明天就是大年三十了,今天在家有空,想集中整理一下CQRS架构的特点以及相比传统架构的优缺点分析.先提前祝大家猴年新春快乐.万事如意.身体健康! 最近几年,在DDD的领域,我们经常会看到CQRS架构的概 ...
- 谈一下关于CQRS架构如何实现高性能
CQRS架构简介 前不久,看到博客园一位园友写了一篇文章,其中的观点是,要想高性能,需要尽量:避开网络开销(IO),避开海量数据,避开资源争夺.对于这3点,我觉得很有道理.所以也想谈一下,CQRS架构 ...
- AutoMapper:Unmapped members were found. Review the types and members below. Add a custom mapping expression, ignore, add a custom resolver, or modify the source/destination type
异常处理汇总-后端系列 http://www.cnblogs.com/dunitian/p/4523006.html 应用场景:ViewModel==>Mode映射的时候出错 AutoMappe ...
- 分享一个CQRS/ES架构中基于写文件的EventStore的设计思路
最近打算用C#实现一个基于文件的EventStore. 什么是EventStore 关于什么是EventStore,如果还不清楚的朋友可以去了解下CQRS/Event Sourcing这种架构,我博客 ...
- 一种简单的CQRS架构设计及其实现
一.为什么要实践领域驱动? 近一年时间我一直在思考一个问题:"如何设计一个松耦合.高伸缩性.易于维护的架构?".之所以有这样的想法是因为我接触的不少项目都是以数据库脚本来实现业务逻 ...
- 浅谈命令查询职责分离(CQRS)模式
在常用的三层架构中,通常都是通过数据访问层来修改或者查询数据,一般修改和查询使用的是相同的实体.在一些业务逻辑简单的系统中可能没有什么问题,但是随着系统逻辑变得复杂,用户增多,这种设计就会出现一些性能 ...
随机推荐
- iis 使用 LocalDB 报错:provider: SQL Network Interfaces, error: 50
在使用asp.net core读取localdb数据库时,报以下错误: 在与 SQL Server 建立连接时出现与网络相关的或特定于实例的错误.未找到或无法访问服务器.请验证实例名称是否正确并且 S ...
- ZigZag Conversion leetcode java
题目: The string "PAYPALISHIRING" is written in a zigzag pattern on a given number of rows l ...
- mvc自定义全局异常处理
异常信息处理是任何网站必不可少的一个环节,怎么有效显示,记录,传递异常信息又成为重中之重的问题.本篇将基于上篇介绍的html2cancas截图功能,实现mvc自定义全局异常处理.先看一下最终实现效果: ...
- C#系列——记一次业务需求:对象的深拷贝
这篇随笔着实在意料之外,主要是源于上周开发BS的一个业务,需要用到对象的深拷贝.说的直白一点,就是将对象内存分配区和引用完全拷贝一份新的.这种需求以前就遇到过,怎么解决的已经记不清了.这次趁着这个机会 ...
- 【UOJ #14】【UER #1】DZY Loves Graph
http://uoj.ac/problem/14 题解很好的~ 不带路径压缩的并查集能保留树的原本形态. 按秩合并并查集可以不用路径压缩,但是因为此题要删除,如果把深度当为秩的话不好更新秩的值,所以把 ...
- Asp.Net MVC<六>:Controller、Action 待续
控制器 抽象类Controller Visual Studio的向导创建的Controller类型继承自抽象类Controller. 它是ControllerBase的子类. 实现了IControll ...
- Asp.Net MVC<四>:路由器
路由的核心类型基本定义于System.Web.dll中,路由机制同样可应用与Web Forms,实现请求地址和物理文件的分离. web form中使用路由器的示例 路由配置 protected voi ...
- VS 团队资源管理 强制解锁锁定文件
故事是这样发生的: 以前有台电脑,在团队资源里看程序,可能冥冥中不小心按了个空格,so,文件被锁定 而我却没有发现 如果再给我一个机会,我只想说记得签入 然后,高潮来了 重装电脑 欣喜的装好新机子打开 ...
- BZOJ 3224: Tyvj 1728 普通平衡树
3224: Tyvj 1728 普通平衡树 Time Limit: 10 Sec Memory Limit: 128 MBSubmit: 9629 Solved: 4091[Submit][Sta ...
- ubuntu16.04装MatConvNet
按matconvnet官网上的步骤来,编译代码的时候会发现编译失败. 参考这条issues 以下是我的解决方案: I use ubuntu16.04 with x64 architecture. I ...