推荐系统之矩阵分解(MF)
一、矩阵分解
1.案例
我们都熟知在一些软件中常常有评分系统,但并不是所有的用户user人都会对项目item进行评分,因此评分系统所收集到的用户评分信息必然是不完整的矩阵。那如何跟据这个不完整矩阵中已有的评分来预测未知评分呢。使用矩阵分解的思想很好地解决了这一问题。
假如我们现在有一个用户-项目的评分矩阵R(n,m)是n行m列的矩阵,n表示user个数,m行表示item的个数

那么,如何根据目前的矩阵R(5,4)如何对未打分的商品进行评分的预测(如何得到分值为0的用户的打分值)?
——矩阵分解的思想可以解决这个问题,其实这种思想可以看作是有监督的机器学习问题(回归问题)。
矩阵分解的过程中,,矩阵R可以近似表示为矩阵P与矩阵Q的乘积:
矩阵P(n,k)表示n个user和k个特征之间的关系矩阵,这k个特征是一个中间变量,矩阵Q(k,m)的转置是矩阵Q(m,k),矩阵Q(m,k)表示m个item和K个特征之间的关系矩阵,这里的k值是自己控制的,可以使用交叉验证的方法获得最佳的k值。为了得到近似的R(n,m),必须求出矩阵P和Q,如何求它们呢?
2.推导步骤
1.首先令:
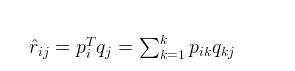
2。对于式子1的左边项,表示的是r^ 第i行,第j列的元素值,对于如何衡量,我们分解的好坏呢,式子2,给出了衡量标准,也就是损失函数,平方项损失,最后的目标,就是每一个元素(非缺失值)的e(i,j)的总和最小值
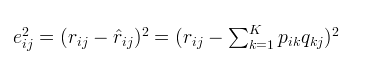
3.使用梯度下降法获得修正的p和q分量:
- 求解损失函数的负梯度
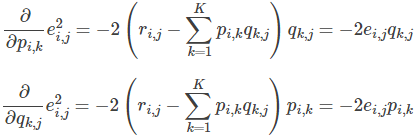
- 根据负梯度的方向更新变量:
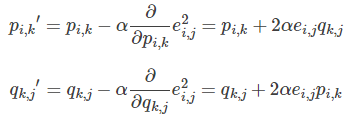
4.不停迭代直到算法最终收敛(直到sum(e^2) <=阈值,即梯度下降结束条件:f(x)的真实值和预测值小于自己设定的阈值)
5.为了防止过拟合,增加正则化项
3.加入正则项的损失函数求解
1.通常在求解的过程中,为了能够有较好的泛化能力,会在损失函数中加入正则项,以对参数进行约束,加入正则L2范数的损失函数为:

对正则化不清楚的,公式可化为:
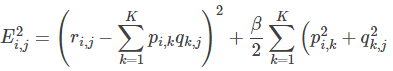
2.使用梯度下降法获得修正的p和q分量:
- 求解损失函数的负梯度:
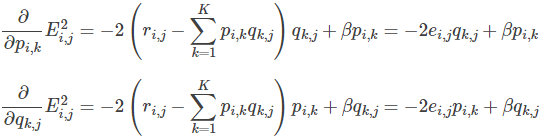
- 根据负梯度的方向更新变量:
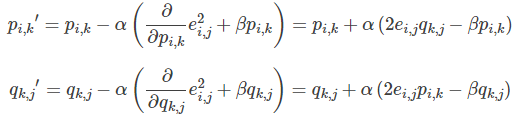
4.预测
预测利用上述的过程,我们可以得到矩阵和,这样便可以为用户 i 对商品 j 进行打分:

二、代码实现
import numpy as np
import matplotlib.pyplot as plt
def matrix(R, P, Q, K, alpha, beta):
result=[]
steps = 1
while 1 :
#使用梯度下降的一步步的更新P,Q矩阵直至得到最终收敛值
steps = steps + 1
eR = np.dot(P,Q)
e=0
for i in range(len(R)):
for j in range(len(R[i])):
if R[i][j]>0:
# .dot(P,Q) 表示矩阵内积,即Pik和Qkj k由1到k的和eij为真实值和预测值的之间的误差,
eij=R[i][j]-np.dot(P[i,:],Q[:,j])
#求误差函数值,我们在下面更新p和q矩阵的时候我们使用的是化简得到的最简式,较为简便,
#但下面我们仍久求误差函数值这里e求的是每次迭代的误差函数值,用于绘制误差函数变化图
e=e+pow(R[i][j] - np.dot(P[i,:],Q[:,j]),2)
for k in range(K):
#在上面的误差函数中加入正则化项防止过拟合
e=e+(beta/2)*(pow(P[i][k],2)+pow(Q[k][j],2))
for k in range(K):
#在更新p,q时我们使用化简得到了最简公式
P[i][k]=P[i][k]+alpha*(2*eij*Q[k][j]-beta*P[i][k])
Q[k][j]=Q[k][j]+alpha*(2*eij*P[i][k]-beta*Q[k][j])
print('迭代轮次:', steps, ' e:', e)
result.append(e)#将每一轮更新的损失函数值添加到数组result末尾
#当损失函数小于一定值时,迭代结束
if eij<0.00001:
break
return P,Q,result
R=[
[5,3,1,1,4],
[4,0,0,1,4],
[1,0,0,5,5],
[1,3,0,5,0],
[0,1,5,4,1],
[1,2,3,5,4]
]
R=np.array(R)
alpha = 0.0001 #学习率
beta = 0.002
N = len(R) #表示行数
M = len(R[0]) #表示列数
K = 3 #3个因子
p = np.random.rand(N, K) #随机生成一个 N行 K列的矩阵
q = np.random.rand(K, M) #随机生成一个 M行 K列的矩阵
P, Q, result=matrix(R, p, q, K, alpha, beta)
print("矩阵Q为:\n",Q)
print("矩阵P为:\n",P)
print("矩阵R为:\n",R)
MF = np.dot(P,Q)
print("预测矩阵:\n",MF)
#下面代码可以绘制损失函数的收敛曲线图
n=len(result)
x=range(n)
plt.plot(x, result,color='b',linewidth=3)
plt.xlabel("generation")
plt.ylabel("loss")
plt.show()
推荐系统之矩阵分解(MF)的更多相关文章
- 推荐系统之矩阵分解及C++实现
1.引言 矩阵分解(Matrix Factorization, MF)是传统推荐系统最为经典的算法,思想来源于数学中的奇异值分解(SVD), 但是与SVD 还是有些不同,形式就可以看出SVD将原始的评 ...
- 推荐系统之矩阵分解及其Python代码实现
有如下R(5,4)的打分矩阵:(“-”表示用户没有打分) 其中打分矩阵R(n,m)是n行和m列,n表示user个数,m行表示item个数 那么,如何根据目前的矩阵R(5,4)如何对未打分的商品进行评分 ...
- 【RS】Matrix Factorization Techniques for Recommender Systems - 推荐系统的矩阵分解技术
[论文标题]Matrix Factorization Techniques for Recommender Systems(2009,Published by the IEEE Computer So ...
- 【RS】List-wise learning to rank with matrix factorization for collaborative filtering - 结合列表启发排序和矩阵分解的协同过滤
[论文标题]List-wise learning to rank with matrix factorization for collaborative filtering (RecSys '10 ...
- SVD++:推荐系统的基于矩阵分解的协同过滤算法的提高
1.背景知识 在讲SVD++之前,我还是想先回到基于物品相似的协同过滤算法.这个算法基本思想是找出一个用户有过正反馈的物品的相似的物品来给其作为推荐.其公式为:
- 推荐系统实践 0x0b 矩阵分解
前言 推荐系统实践那本书基本上就更新到上一篇了,之后的内容会把各个算法拿来当专题进行讲解.在这一篇,我们将会介绍矩阵分解这一方法.一般来说,协同过滤算法(基于用户.基于物品)会有一个比较严重的问题,那 ...
- 矩阵分解(Matrix Factorization)与推荐系统
转自:http://www.tuicool.com/articles/RV3m6n 对于矩阵分解的梯度下降推导参考如下:
- 推荐系统(recommender systems):预测电影评分--构造推荐系统的一种方法:低秩矩阵分解(low rank matrix factorization)
如上图中的predicted ratings矩阵可以分解成X与ΘT的乘积,这个叫做低秩矩阵分解. 我们先学习出product的特征参数向量,在实际应用中这些学习出来的参数向量可能比较难以理解,也很难可 ...
- 【RS】Sparse Probabilistic Matrix Factorization by Laplace Distribution for Collaborative Filtering - 基于拉普拉斯分布的稀疏概率矩阵分解协同过滤
[论文标题]Sparse Probabilistic Matrix Factorization by Laplace Distribution for Collaborative Filtering ...
随机推荐
- 9.1hadoop 内置计数器、自定义枚举计数器、Streaming计数器
1.1 计数器 计数器的作用是用来统计数量的,用于记录特定事件的次数,分为内置计数器.自定义java枚举计数器.自定义Stream计数器三大类.用于质量分析,或应用级统计.分析计数器的值比分析一堆日 ...
- POJ 2828 线段树活用
题目大意:依次描述了一个N个人的队伍,每个人所站的序号以及他的价值,依次描述每个人的过程中,存在序号相同的人,表示该人插入到了前一个序号相同的人的前面.最后输出整个队伍的值排列情况. 这个题目确实难以 ...
- 吴裕雄--天生自然JAVA线程编程笔记:创建线程
public class ThreadRuning extends Thread{ public ThreadRuning(String name){ //重写构造,可以对线程添加名字 super(n ...
- 【One by one系列】一步步学习TypeScript
TypeScript Quick Start 1.TypeScript是什么? TypeScript是ES6的超集. TS>ES7>ES6>ES5 Vue3.0已经宣布要支持ts,至 ...
- ZJNU 2342 - 夏华献要回家
(夏华献在学校也要做一次梦!) 把5的答案手动算出 会发现从学校开始,兔子的数量呈斐波那契数列(第2项开始)增长 假如现在有n盏路灯 那么睡觉的时间可以得到为 但是n有1e18大,明显使用标准数学公式 ...
- 洛谷 P1113 杂务(vector)
题目传送门 解题思路: 本题说有些杂务是有前提条件的,而有一个特性就是某个杂务的前提一定在这个杂务前面输入,那么,这个题就瞬间沦为了黄题.对于那些有前提条件的杂务,我们只需要找它的前提条件中最晚完成的 ...
- coures包下载和安装 可解决报错ImportError: No module named '_curses'
http://blog.csdn.net/liyaoqing/article/details/54949253 coures curses 库 ( ncurses )提供了控制字符屏幕的独立于终端的方 ...
- windows服务器搭建SVN[多项目设置方法]
https://tortoisesvn.net/downloads.html 根据系统版本进行下载,下载后正常一路正常安装. 第一.设置版本号仓库目录,比如:cdengine 第二.在cdengine ...
- LNMP应用
1.LNMP架构概述 LNMP就是Linux+Nginx+MySQL+PHP Linux作为服务器的操作系统 Nginx作为Web服务器 PHP作为解析动态脚本语言 MySQL即为数据库 Nginx服 ...
- iOS 中UITableView的深理解
例如下图:首先分析一下需求:1.根据模型的不同状态显示不同高度的cell,和cell的UI界面. 2.点击cell的取消按钮时,对应的cell首先要把取消按钮隐藏掉,然后改变cell的高度. 根据需求 ...