使用torch实现RNN
(本文对https://blog.csdn.net/out_of_memory_error/article/details/81456501的结果进行了复现。)
在实验室的项目遇到了困难,弄不明白LSTM的原理。到网上搜索,发现LSTM是RNN的变种,那就从RNN开始学吧。
带隐藏状态的RNN可以用下面两个公式来表示: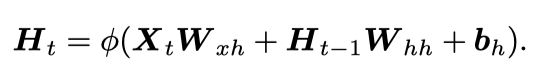
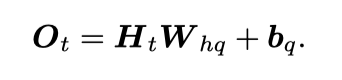
可以看出,一个RNN的参数有W_xh,W_hh,b_h,W_hq,b_q和H(t)。其中H(t)是步数的函数。
参考的文章考虑了这样一个问题,对于x轴上的一列点,有一列sin值,我们想知道它对应的cos值,但是即使sin值相同,cos值也不同,因为输出结果不仅依赖于当前的输入值sinx,还依赖于之前的sin值。这时候可以用RNN来解决问题
用到的核心函数:torch.nn.RNN() 参数如下:
input_size – 输入
x的特征数量。hidden_size – 隐藏层的特征数量。
num_layers – RNN的层数。
nonlinearity – 指定非线性函数使用
tanh还是relu。默认是tanh。bias – 如果是
False,那么RNN层就不会使用偏置权重 $b_ih$和$b_hh$,默认是Truebatch_first – 如果
True的话,那么输入Tensor的shape应该是[batch_size, time_step, feature],输出也是这样。dropout – 如果值非零,那么除了最后一层外,其它层的输出都会套上一个
dropout层。bidirectional – 如果
True,将会变成一个双向RNN,默认为False。
下面是代码:
# encoding:utf-8
import torch
import numpy as np
import matplotlib.pyplot as plt # 导入作图相关的包
from torch import nn # 定义RNN模型
class Rnn(nn.Module):
def __init__(self, INPUT_SIZE):
super(Rnn, self).__init__() # 定义RNN网络,输入单个数字.隐藏层size为[feature, hidden_size]
self.rnn = nn.RNN(
input_size=INPUT_SIZE,
hidden_size=32,
num_layers=1,
batch_first=True # 注意这里用了batch_first=True 所以输入形状为[batch_size, time_step, feature]
)
# 定义一个全连接层,本质上是令RNN网络得以输出
self.out = nn.Linear(32, 1) # 定义前向传播函数
def forward(self, x, h_state):
# 给定一个序列x,每个x.size=[batch_size, feature].同时给定一个h_state初始状态,RNN网络输出结果并同时给出隐藏层输出
r_out, h_state = self.rnn(x, h_state)
outs = []
for time in range(r_out.size(1)): # r_out.size=[1,10,32]即将一个长度为10的序列的每个元素都映射到隐藏层上.
outs.append(self.out(r_out[:, time, :])) # 依次抽取序列中每个单词,将之通过全连接层并输出.r_out[:, 0, :].size()=[1,32] -> [1,1]
return torch.stack(outs, dim=1), h_state # stack函数在dim=1上叠加:10*[1,1] -> [1,10,1] 同时h_state已经被更新 TIME_STEP = 10
INPUT_SIZE = 1
LR = 0.02 model = Rnn(INPUT_SIZE)
print(model) loss_func = nn.MSELoss() # 使用均方误差函数
optimizer = torch.optim.Adam(model.parameters(), lr=LR) # 使用Adam算法来优化Rnn的参数,包括一个nn.RNN层和nn.Linear层 h_state = None # 初始化h_state为None for step in range(300):
# 人工生成输入和输出,输入x.size=[1,10,1],输出y.size=[1,10,1]
start, end = step * np.pi, (step + 1)*np.pi steps = np.linspace(start, end, TIME_STEP, dtype=np.float32)
x_np = np.sin(steps)
y_np = np.cos(steps) x = torch.from_numpy(x_np[np.newaxis, :, np.newaxis])
y = torch.from_numpy(y_np[np.newaxis, :, np.newaxis]) # 将x通过网络,长度为10的序列通过网络得到最终隐藏层状态h_state和长度为10的输出prediction:[1,10,1]
prediction, h_state = model(x, h_state)
h_state = h_state.data # 这一步只取了h_state.data.因为h_state包含.data和.grad 舍弃了梯度
# 反向传播
loss = loss_func(prediction, y)
optimizer.zero_grad()
loss.backward() # 优化网络参数具体应指W_xh, W_hh, b_h.以及W_hq, b_q
optimizer.step() # 对最后一次的结果作图查看网络的预测效果
plt.plot(steps, y_np.flatten(), 'r-')
plt.plot(steps, prediction.data.numpy().flatten(), 'b-')
plt.show()
最后一步预测和实际y的结果作图如下:
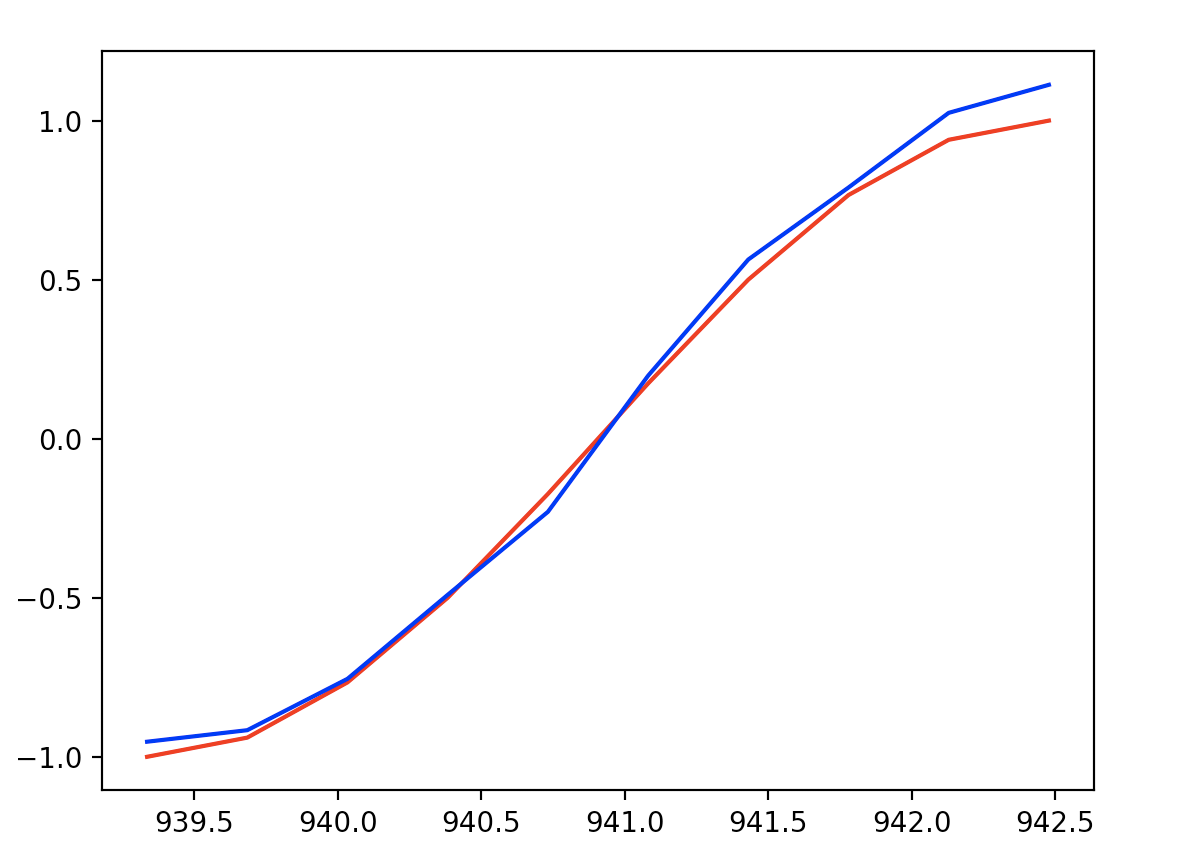
可看出,训练RNN网络之后,对网络输入一个序列sinx,能正确输出对应的序列cosx
使用torch实现RNN的更多相关文章
- PyTorch官方中文文档:torch.nn
torch.nn Parameters class torch.nn.Parameter() 艾伯特(http://www.aibbt.com/)国内第一家人工智能门户,微信公众号:aibbtcom ...
- pytorch实现rnn并且对mnist进行分类
1.RNN简介 rnn,相比很多人都已经听腻,但是真正用代码操练起来,其中还是有很多细节值得琢磨. 虽然大家都在说,我还是要强调一次,rnn实际上是处理的是序列问题,与之形成对比的是cnn,cnn不能 ...
- 从网络架构方面简析循环神经网络RNN
一.前言 1.1 诞生原因 在普通的前馈神经网络(如多层感知机MLP,卷积神经网络CNN)中,每次的输入都是独立的,即网络的输出依赖且仅依赖于当前输入,与过去一段时间内网络的输出无关.但是在现实生活中 ...
- [PyTorch] rnn,lstm,gru中输入输出维度
本文中的RNN泛指LSTM,GRU等等 CNN中和RNN中batchSize的默认位置是不同的. CNN中:batchsize的位置是position 0. RNN中:batchsize的位置是pos ...
- Pytorch基础——使用 RNN 生成简单序列
一.介绍 内容 使用 RNN 进行序列预测 今天我们就从一个基本的使用 RNN 生成简单序列的例子中,来窥探神经网络生成符号序列的秘密. 我们首先让神经网络模型学习形如 0^n 1^n 形式的上下文无 ...
- pytorch RNN层api的几个参数说明
classtorch.nn.RNN(*args, **kwargs) input_size – The number of expected features in the input x hidde ...
- 【学习笔记】RNN算法的pytorch实现
一些新理解 之前我有个疑惑,RNN的网络窗口,换句话说不也算是一个卷积核嘛?那所有的网络模型其实不都是一个东西吗?今天又听了一遍RNN,发现自己大错特错,还是没有学明白阿.因为RNN的窗口所包含的那一 ...
- DeepLearning常用库简要介绍与对比
网上近日流传一张DL相关库在Github上的受关注度对比(数据应该是2016/03/15左右统计的): 其中tensorflow,caffe,keras和Theano排名比较靠前. 今日组会报告上tj ...
- pytorch, LSTM介绍
本文中的RNN泛指LSTM,GRU等等 CNN中和RNN中batchSize的默认位置是不同的. CNN中:batchsize的位置是position 0. RNN中:batchsize的位置是pos ...
随机推荐
- Smarty模板引擎原理概述
smarty(模板引擎,模板技术) 使用smarty主要是为了实现逻辑和外在内容的分离: 特点: 1.速度快(因为第二次执行的时候使用第一次执行时生成的编译文件) 2.缓存技术(正是因为缓存技术,使得 ...
- layui 数据表格最简单的点击事件
//定义点击事件 table.on('row(test)', function(obj){ console.log(obj.tr) //得到当前行元素对象 console.log(obj.data) ...
- CF1353E K-periodic Garland(贪心/dp)
Question 有n盏灯,0代表暗,1代表亮,相邻两个1之间为周期k,求出最少的改变次数 Solution First 贪心方法 详见博客https://blog.csdn.net/cheng__y ...
- [VuePress]个人博客 -- 批处理自动化编译提交 -- 排错记录
建了一个VuePress的个人博客 想着写个批处理,自动编译并上传到GitHub. 结果遇到两个问题, 一个是,vuepress build docs编译后,这个命令执行完就exit了 研究了下bat ...
- PowerDesigner使用教程(一)
一.PowerDesigner简介 PowerDesigner是一款功能非常强大的建模工具软件,足以与Rose比肩,同样是当今最著名的建模软件之一.Rose是专攻UML对象模型的建模工具,之后才向数据 ...
- .Net Core之仓储(Repository)模式
我们经常在项目中使用仓储(Repository)模式,来实现解耦数据访问层与业务层.那在.net core使用EF core又是怎么做的呢? 现在我分享一下我的实现方案: 一.在领域层创建Reposi ...
- SpringBoot打包Docker镜像
构建spring boot项目 本地测试访问 打成jar包 在本地运行jar包测试 到这一步就证明jar包没问题 idea下载一个插件 在这创建一个Dockerfile文件 安装插件后会高亮显示. 在 ...
- word dde payload
payload: ctrl+F9 {DDEAUTO c:\\windows\\system32\\cmd.exe "/k calc.exe" } Since this techni ...
- jchdl - GSL Wire
https://mp.weixin.qq.com/s/4w_wwwCd6iBhh0QR2wK81Q org.jchdl.model.gsl.core.datatype.net.Wire.java ...
- 腾讯云EMR大数据实时OLAP分析案例解析
OLAP(On-Line Analytical Processing),是数据仓库系统的主要应用形式,帮助分析人员多角度分析数据,挖掘数据价值.本文基于QQ音乐海量大数据实时分析场景,通过QQ音乐与腾 ...