【Hadoop】MapReduce练习:分科目等级并按分区统计学生以及人数
需求
背景:学校的学生的是一个非常大的生成数据的集体,比如每次考试的成绩
现有一个班级的学生一个月的考试成绩数据。
科目 姓名 分数
需求:求出每门成绩中属于甲级的学生人数和总人数
乙级的学生人数和总人数
丙级的学生人数和总人数
甲级(90及以上)乙级(80到89)丙级(0到79)
处理数据结果:
甲级分区
课程\t甲级\t学生1,学生2,...\t总人数
乙级分区
课程\t乙级\t学生1,学生2,...\t总人数
丙级分区
课程\t丙级\t学生1,学生2,...\t总人数
文档格式
English,liudehua,80
English,lijing,79
English,nezha,85
English,jinzha,60
English,muzha,71
English,houzi,99
English,libai,88
English,hanxin,66
English,zhugeliang,95
Math,liudehua,74
Math,lijing,72
Math,nezha,95
Math,jinzha,61
Math,muzha,37
Math,houzi,37
Math,libai,84
Math,hanxin,89
Math,zhugeliang,93
Computer,liudehua,54
Computer,lijing,73
Computer,nezha,86
Computer,jinzha,96
Computer,muzha,76
Computer,houzi,92
Computer,libai,73
Computer,hanxin,82
Computer,zhugeliang,100
代码示例
StuDriver
import org.apache.hadoop.io.Text;
import stuScore.JobUtils;
public class StuDriver {
public static void main(String[] args) {
String[] paths = {"F:/stu_score.txt", "F:/output"};
JobUtils.commit(paths, true, 3, false, StuDriver.class,
StuMapper.class, Text.class, Text.class, null, StuPartitioner.class, StuReduce.class,
Text.class, Text.class);
}
}
JobUtils
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.File;
import java.io.IOException;
public class JobUtils {
private static Configuration conf;
static {
conf = new Configuration();
}
/**
* 提交job
*
* @param paths 输入输出路径数组
* @param isPartition 是否包含自定义分区类
* @param reduceNumber reduce数量(若自定义分区为true,则此项必须>=自定义分区数)
* @param isGroup 是否分组
* @param params 可变参数
*/
public static void commit(String[] paths, boolean isPartition, int reduceNumber, boolean isGroup, Class... params) {
try {
Job job = Job.getInstance(conf);
job.setJarByClass(params[0]);
job.setMapperClass(params[1]);
job.setMapOutputKeyClass(params[2]);
job.setMapOutputValueClass(params[3]);
if(isGroup) {
job.setGroupingComparatorClass(params[4]);
}
if (isPartition) {
job.setPartitionerClass(params[5]);//设置自定义分区;
}
if (reduceNumber > 0) {
job.setNumReduceTasks(reduceNumber);
job.setReducerClass(params[6]);
job.setOutputKeyClass(params[7]);
job.setOutputValueClass(params[8]);
} else {
job.setNumReduceTasks(0);
}
FileInputFormat.setInputPaths(job, new Path(paths[0]));
FileOutputFormat.setOutputPath(job, new Path(paths[1]));
job.waitForCompletion(true);
} catch (InterruptedException | ClassNotFoundException | IOException e) {
e.printStackTrace();
}
}
}
StuMapper
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class StuMapper extends Mapper<LongWritable, Text, Text, Text> {
Text k = new Text();
Text v = new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] splits = line.split(",");
int score = Integer.parseInt(splits[2]);
String level;
if (score >= 90) {
level = "甲级";
} else if (score < 90 && score >= 80) {
level = "乙级";
} else {
level = "丙级";
}
k.set(splits[0] + "\t" + level);
v.set(splits[1]);
context.write(k, v);
}
}
StuReduce
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class StuReduce extends Reducer<Text,Text,Text, Text> {
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
StringBuilder builder = new StringBuilder();
int count =0;
for (Text v : values) {
builder.append(v+",");
count++;
}
builder.replace(builder.length()-1,builder.length(),"\t");
builder.append(count);
context.write(key,new Text(builder.toString()));
}
}
StuPartitioner
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;
public class StuPartitioner extends Partitioner<Text, Text> {
@Override
public int getPartition(Text text, Text text2, int i) {
String line = text.toString();
if(line.contains("甲级")){
return 0;
}else if(line.contains("乙级")){
return 1;
}else{
return 2;
}
}
}
输出结果
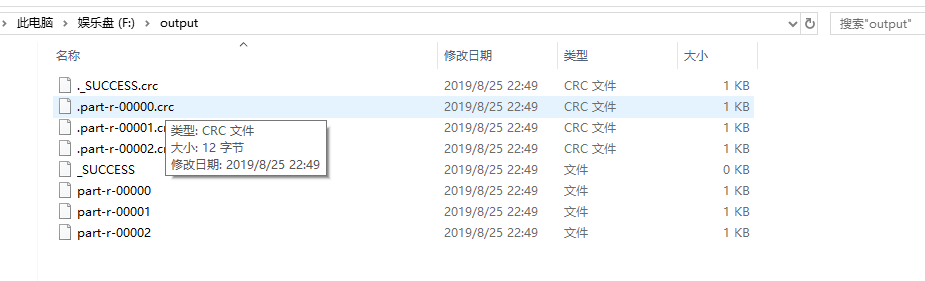



【Hadoop】MapReduce练习:分科目等级并按分区统计学生以及人数的更多相关文章
- Hadoop MapReduce编程 API入门系列之分区和合并(十四)
不多说,直接上代码. 代码 package zhouls.bigdata.myMapReduce.Star; import java.io.IOException; import org.apache ...
- Hadoop MapReduce编程 API入门系列之薪水统计(三十一)
不多说,直接上代码. 代码 package zhouls.bigdata.myMapReduce.SalaryCount; import java.io.IOException; import jav ...
- Hadoop Mapreduce分区、分组、二次排序过程详解[转]
原文地址:Hadoop Mapreduce分区.分组.二次排序过程详解[转]作者: 徐海蛟 教学用途 1.MapReduce中数据流动 (1)最简单的过程: map - reduce (2) ...
- Hadoop mapreduce自定义分区HashPartitioner
本文发表于本人博客. 在上一篇文章我写了个简单的WordCount程序,也大致了解了下关于mapreduce运行原来,其中说到还可以自定义分区.排序.分组这些,那今天我就接上一次的代码继续完善实现自定 ...
- Hadoop MapReduce执行过程详解(带hadoop例子)
https://my.oschina.net/itblog/blog/275294 摘要: 本文通过一个例子,详细介绍Hadoop 的 MapReduce过程. 分析MapReduce执行过程 Map ...
- Hadoop MapReduce 二次排序原理及其应用
关于二次排序主要涉及到这么几个东西: 在0.20.0 以前使用的是 setPartitionerClass setOutputkeyComparatorClass setOutputValueGrou ...
- 三种方法实现Hadoop(MapReduce)全局排序(1)
我们可能会有些需求要求MapReduce的输出全局有序,这里说的有序是指Key全局有序.但是我们知道,MapReduce默认只是保证同一个分区内的Key是有序的,但是不保证全局有序.基于此,本文提供三 ...
- hadoop MapReduce
简单介绍 官方给出的介绍是hadoop MR是一个用于轻松编写以一种可靠的.容错的方式在商业化硬件上的大型集群上并行处理大量数据的应用程序的软件框架. MR任务通常会先把输入的数据集切分成独立的块(可 ...
- Hadoop Mapreduce 案例 wordcount+统计手机流量使用情况
mapreduce设计思想 概念:它是一个分布式并行计算的应用框架它提供相应简单的api模型,我们只需按照这些模型规则编写程序,即可实现"分布式并行计算"的功能. 案例一:word ...
随机推荐
- C# 集合(9) 持续更新
数组的大小是固定的.如果元素个数动态,就使用集合类. List<T>是与数组相当的集合类.其他的集合:队列.栈.链表.字典和集. .NET Framework 1.0 包括非泛型集合类,如 ...
- mybatis中foreach使用方法
作者:学无先后 达者为先 作者:偶尔记一下 foreach一共有三种类型,分别为List,[](array),Map三种. 下面表格是我总结的各个属性的用途和注意点. foreach属性 属性 描述 ...
- 莫比乌斯函数介绍&&基础
定义 设正整数$N$按照算术基本定理分解质因数为$N=p_1^{c_1}p_2^{c_2} \cdots P_m^{c_m}$,定义函数: $$\mu(N)= \left\{\begin{matrix ...
- 配置NFS共享
NFS(网络文件系统)-------> linux与linux平台 服务器端: 1.安装软件nfs-utils(服务:nfs-server) 2.创建共享目录:mkdir /nfs_dir 3. ...
- [Python自学] day-18 (1) (JS正则、第三方组件)
一.JS的正则表达式 JS正则提供了两个方法: test():用于判断字符串是否符合规定: exec():获取匹配的数据: 1.test() 定义一个正则表达式: reg = /\d+/; // 用于 ...
- 【luoguP1182】数列分段 Section II
题目描述 对于给定的一个长度为N的正整数数列A-i,现要将其分成M(M≤N)段,并要求每段连续,且每段和的最大值最小. 关于最大值最小: 例如一数列4 2 4 5 1要分成3段 将其如下分段: [4 ...
- MIME协议(五) -- MIME邮件的编码方式
5 MIME邮件的编码方式 由于每个ASCII码字符只占用一个字节(8个bit位),且最高bit位总为0,即ASCII码字符中的有真正意义的信息只是后面的7个低bit位,而传统的SMTP协议又是基于 ...
- Codeforces 1106E. Lunar New Year and Red Envelopes(DP)
E. Lunar New Year and Red Envelopes 题意: 在长度为n的时间轴上,有k个红包,每个红包有领取时间段[s,t],价值w,以及领了个这个红包之后,在时间d到来之前无法再 ...
- H5页面验收流程及性能验收标准
1,接入方需要保证H5页面兼容性.功能正常以及满足H5约束规范 2,有支付功能的必须要有订单业务以及订单入口,存在有效订单 3,提前X个工作日提交验收,需要抄送相关设计.产品.H5性能验收负责人进行验 ...
- Linux-常用shell简介及shell基本操作
1.查询shell环境变量,切换shell种类 表明目前使用的shell种类是bash. 要想改变shell种类,在终端输入想要运行的shell名称即可.在切换shell种类的过程中,可能会操 ...