scikit-learn中的机器学习算法封装——kNN
接前面 https://www.cnblogs.com/Liuyt-61/p/11738399.html
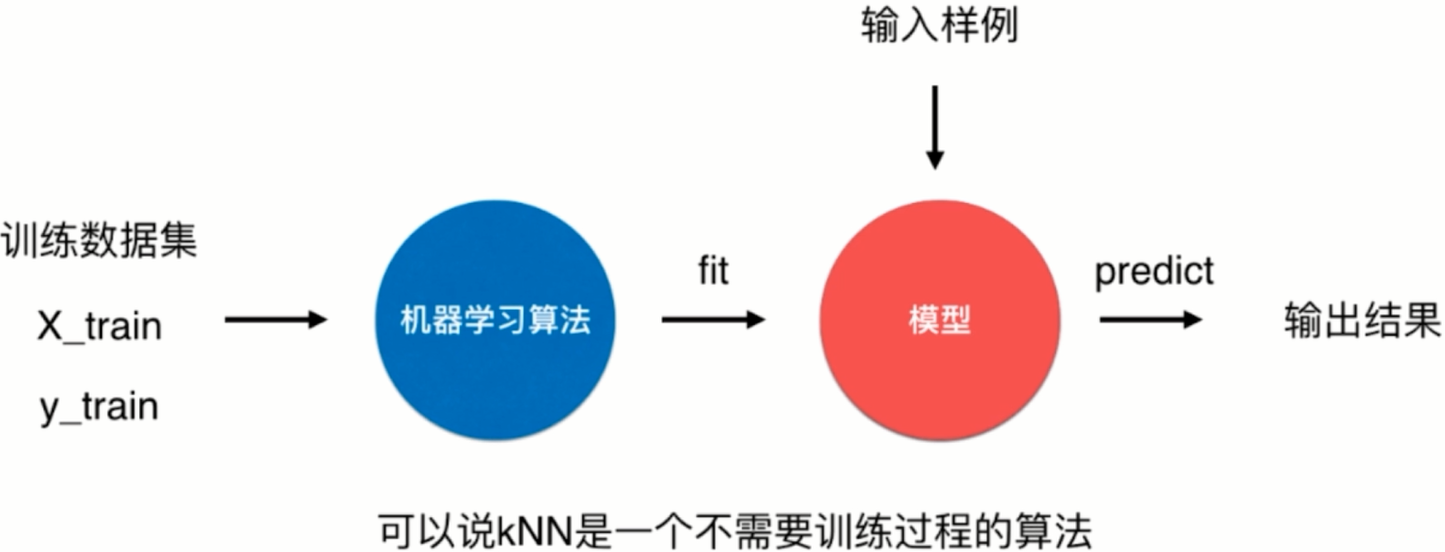
回过头来看这张图,什么是机器学习?就是将训练数据集喂给机器学习算法,在上面kNN算法中就是将特征集X_train和Y_train传给机器学习算法,然后拟合(fit)出一个模型,然后输入样例到该模型进行预测(predict)输出结果。
而对于kNN来说,算法的模型其实就是自身的训练数据集,所以可以说kNN是一个不需要训练过程的算法。
k近邻算法是非常特殊的,可以被认为是没有模型的算法
为了和其他算法统一,可以认为训练数据集就是模型本身
使用scikit-learn中的kNN实现
#先导入我们需要的包
from sklearn.neighbors import KNeighborsClassifier #特征点的集合
raw_data_X = [[3.393533211, 2.331273381],
[3.110073483, 1.781539638],
[1.343808831, 3.368360954],
[3.582294042, 4.679179110],
[2.280362439, 2.866990263],
[7.423436942, 4.696522875],
[5.745051997, 3.533989803],
[9.172168622, 2.511101045],
[7.792783481, 3.424088941],
[7.939820817, 0.791637231]
]
#0就代表良性肿瘤,1就代表恶性肿瘤
raw_data_y = [, , , , , , , , , ]
#我们使用raw_data_X和raw_data_y作为我们的训练集
X_train = np.array(raw_data_X) #训练数据集的特征
Y_train = np.array(raw_data_y) #训练数据集的结果(标签) #首先我们需要对包中的KNeighborsClassifier进行实例化,其中可以传入k的值作为参数
kNN_classifier = KNeighborsClassifier(n_neighbors=)
#然后先执行fit方法进行拟合操作得出模型,将训练数据集作为参数传入
kNN_classifier.fit(X_train,Y_train)
#执行predict预测操作,传入样本数据
#因为使用scikit-learn中的kNN算法是对一组矩阵形式的数据进行一条条的预测,所以我们传入的样本数据集参数也应该先转换为矩阵的形式
X_predict = x.reshape(,-) #因为我们已知我们传入的数据只有一行
y_predict = kNN_classifier.predict(X_predict)
In[]: y_predict
Out[]: array([])
#所以此时的y_predict即为我们所需要的样本的预测结果
In[]: y_predict[]
Out[]:
基于scikit-learn的fit-predict模式,进行重写我们的Python实现,进行简单的自定义fit和predict方法实现kNN
import numpy as np
from math import sqrt
from collections import Counter class KNNClassifier: def __init__(self, k):
'''初始化KNN分类器'''
#使用断言进行判定传入的参数的合法性
assert k >= , "k must be valid"
self.k = k;
#此处定义为私有变量,外部成员不可访问进行操作
self._X_train = None
self._Y_train = None def fit(seld, X_train, Y_train):
'''根据训练集X_train和Y_train训练kNN分类器'''
assert X_train.shape[] == Y_train.shape[],\
"the size of X_train must be equal to the size of Y_train"
assert self.k <= X_train.shape[],\
"the size of X_train must be at least k" self._X_train = X_train
self._Y_train = Y_train
return self #X_predict 为传入的矩阵形式数据
def predict(self, X_predict):
'''给定待预测数据集X_train,返回表示X_predict的结果向量'''
assert self._X_train is not None and self._Y_train is not None,\
"must fit before predict!"
assert X_predict.shape[] == self._X_train.shape[],\
"the feature number of X_predict must equal to X_train" #使用私有方法_predict(x)进行对x进行预测
#循环遍历X_predict,对其中每一条样本数据集执行私有方法_predict(x),将预测结果存入y_predict中
y_predict = [self._predict(x) for x in X_predict]
return np.array(y_predict) def _predict(self, x):
'''给定单个待预测数据x,返回x的预测结果值'''
'''此处的代码逻辑和重写之前的代码逻辑一样'''
distances = [sqrt(np.sum(x_train - x) ** ) for x_train in self._X_train]
nearest = np.argsort(distances) topk_y = [self._Y_train[i] for i in nearest[:self.k]]
votes = Counter(topk_y)
return votes.most_common()[][] #重写对象的“自我描述”
def __repr__(self):
return "KNN(k=%d)" % self.k
scikit-learn中的机器学习算法封装——kNN的更多相关文章
- 在opencv3中的机器学习算法
在opencv3.0中,提供了一个ml.cpp的文件,这里面全是机器学习的算法,共提供了这么几种: 1.正态贝叶斯:normal Bayessian classifier 我已在另外一篇博文中介 ...
- 在opencv3中实现机器学习算法之:利用最近邻算法(knn)实现手写数字分类
手写数字digits分类,这可是深度学习算法的入门练习.而且还有专门的手写数字MINIST库.opencv提供了一张手写数字图片给我们,先来看看 这是一张密密麻麻的手写数字图:图片大小为1000*20 ...
- opencv3中的机器学习算法之:EM算法
不同于其它的机器学习模型,EM算法是一种非监督的学习算法,它的输入数据事先不需要进行标注.相反,该算法从给定的样本集中,能计算出高斯混和参数的最大似然估计.也能得到每个样本对应的标注值,类似于kmea ...
- 机器学习算法之——KNN、Kmeans
一.Kmeans算法 kmeans算法又名k均值算法.其算法思想大致为:先从样本集中随机选取 kk 个样本作为簇中心,并计算所有样本与这 kk 个“簇中心”的距离,对于每一个样本,将其划分到与其距离最 ...
- 在opencv3中的机器学习算法练习:对OCR进行分类
OCR (Optical Character Recognition,光学字符识别),我们这个练习就是对OCR英文字母进行识别.得到一张OCR图片后,提取出字符相关的ROI图像,并且大小归一化,整个图 ...
- 机器学习算法之:KNN
基于实例的学习方法中,最近邻法和局部加权回归法用于逼近实值或离散目标函数,基于案例的推理已经被应用到很多任务中,比如,在咨询台上存储和复用过去的经验:根据以前的法律案件进行推理:通过复用以前求解的问题 ...
- (原创)(四)机器学习笔记之Scikit Learn的Logistic回归初探
目录 5.3 使用LogisticRegressionCV进行正则化的 Logistic Regression 参数调优 一.Scikit Learn中有关logistics回归函数的介绍 1. 交叉 ...
- 机器学习算法·KNN
机器学习算法应用·KNN算法 一.问题描述 验证码目前在互联网上非常常见,从学校的教务系统到12306购票系统,充当着防火墙的功能.但是随着OCR技术的发展,验证码暴露出的安全问题越来越严峻.目前对验 ...
- (原创)(三)机器学习笔记之Scikit Learn的线性回归模型初探
一.Scikit Learn中使用estimator三部曲 1. 构造estimator 2. 训练模型:fit 3. 利用模型进行预测:predict 二.模型评价 模型训练好后,度量模型拟合效果的 ...
随机推荐
- k8s中删除pod后仍然存在问题
分析: 是因为删除了pod,但是没有删除对应的deployment,删除对应的deployment即可 实例如下: 删除pod [root@test2 ~]# kubectl get pod -n j ...
- 解决RedisDesktopManager连接不上redis问题
linux 下安装redis很简单,在此不做赘述 发现linux上启动redis,测试redis使用正常, 但使用RedisDesktopManager却连接不上,报错如下,报错信息显示:当前使用的P ...
- CF1227D Optimal Subsequences
思路: 首先对于单个查询(k, p)来说,答案一定是a数组中的前k大数.如果第k大的数字有多个怎么办?取索引最小的若干个.所以我们只需对a数组按照值降序,索引升序排序即可. 多个查询怎么办?离线处理. ...
- 使用redis调用lua脚本的方式对接口进行限流
java端实现: //初始化一个redis可执行的lua DefaultRedisScript<List> defaultRedisScript = new DefaultRedisScr ...
- LeetCode 108. 将有序数组转换为二叉搜索树(Convert Sorted Array to Binary Search Tree) 14
108. 将有序数组转换为二叉搜索树 108. Convert Sorted Array to Binary Search Tree 题目描述 将一个按照升序排列的有序数组,转换为一棵高度平衡二叉搜索 ...
- matplotlib实例笔记
下面的图型是在一幅画布上建立的四个球员相关数据的极坐标图 关于这个图的代码如下: #_*_coding:utf-8_*_ import numpy as np import matplotlib.py ...
- Cortex_m7内核cache深入了解和应用
一,cache概述 从下图可以看出,从M7内核才开始有的cache,这对于从M0,M3,M4一路走来的小伙伴来说,多了一个cache就多了一个障碍. Cortex-M7 core with 32K/3 ...
- Android--DES加密
Base64.java import java.io.ByteArrayOutputStream; import java.io.IOException; import java.io.OutputS ...
- Docker 方式部署的应用的版本更新
前言 公司使用 Docker-Compose 的方式部署 Jenkins/Gitlab/Sonar/Confluence/Apollo/Harbor/ELK/MySQL 等一系列开发工具/数据库. 而 ...
- C++11 特性
之前工作中开发/维护的模块大多都是 "远古代码",只能编译 C++98,很多 C++11 的特性都忘得差不多了,再回顾一下 右值引用&转移语义: 消除两个对象交互时不必要的 ...