11_Hive TransForm 案例
1.需求:将Json格式的数据处理后插入新表中
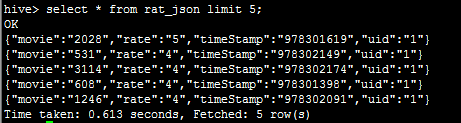
数据文件如下:rating.json,文件格式:{"movie":"2858","rate":"5","timeStamp":"978159467","uid":"17"}
{"movie":"2028","rate":"5","timeStamp":"978301619","uid":"1"}
{"movie":"531","rate":"4","timeStamp":"978302149","uid":"1"}
{"movie":"3114","rate":"4","timeStamp":"978302174","uid":"1"}
{"movie":"608","rate":"4","timeStamp":"978301398","uid":"1"}
{"movie":"1246","rate":"4","timeStamp":"978302091","uid":"1"}
{"movie":"1357","rate":"5","timeStamp":"978298709","uid":"2"}
{"movie":"3068","rate":"4","timeStamp":"978299000","uid":"3"}
{"movie":"1537","rate":"4","timeStamp":"978299620","uid":"3"}
{"movie":"434","rate":"2","timeStamp":"978300174","uid":"4"}
{"movie":"2126","rate":"3","timeStamp":"978300123","uid":"5"}
{"movie":"2067","rate":"5","timeStamp":"978298625","uid":"6"}
{"movie":"1265","rate":"3","timeStamp":"978299712","uid":"7"}
实现步骤:
1.使用Hive创建原始表rate_json,并将rating.json文件加载到该表
hive> create table rat_json(line string) row format delimited;
hive> load data local inpath '/root/rating.json' into table rat_json;
2.实现方案1:自定义函数实现json数据字段的切分
2.1:开发java类继承UDF,然后重载evaluate方法
2.2:上传jar包至服务器,并将jar包添加到hive的classpath下:hive>add jar /data/udf.jar;
2.3:创建临时函数与开发好的java class关联:create temporary function parsejson as 'cn.hive.demo.JsonParser';
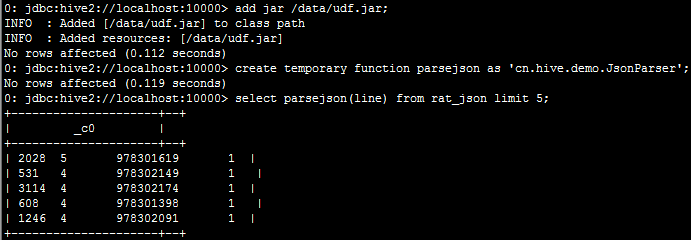
3.实现方案2:使用内置函数split进行字段切分,然后保存到一张新表中;

insert overwrite table t_rating
select split(parsejson(line),'\t')[0]as movieid,split(parsejson(line),'\t')[1] as rate,
split(parsejson(line),'\t')[2] as timestring,split(parsejson(line),'\t')[3] as uid
from rat_json limit 10;

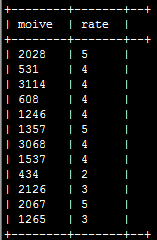
4.实现方案3:使用内置jason函数;
select get_json_object(line,'$.movie') as moive,get_json_object(line,'$.rate') as rate from rat_json;
5.实现方案4:Hive的 Transform 关键字提供了在SQL中调用自写脚本的功能,适合实现Hive中没有的功能又不想写UDF的情况
使用transform+python脚本的方式
根据上述过程,将原始表rat_json中的json格式的数据进行切分并存储到t_rating表中:
5.1:编辑一个Python脚本:weekday_mapper.py
#!/bin/python
import sys
import datetime for line in sys.stdin://标准输出到屏幕上的东西
line = line.strip()
movieid, rating, unixtime,userid = line.split('\t')//t_rating表输出到屏幕上的数据是以table键隔开显示的
weekday = datetime.datetime.fromtimestamp(float(unixtime)).isoweekday()
print '\t'.join([movieid, rating, str(weekday),userid])
5.2:将文件加入hive的classpath:hive> add file /root/weekday_mapper.py;
5.3:执行查询
hive>create table u_data_new as
SELECT
TRANSFORM (movieid, rate, timestring,uid)
USING 'python weekday_mapper.py'
AS (movieid, rate, weekday,uid)
FROM t_rating;
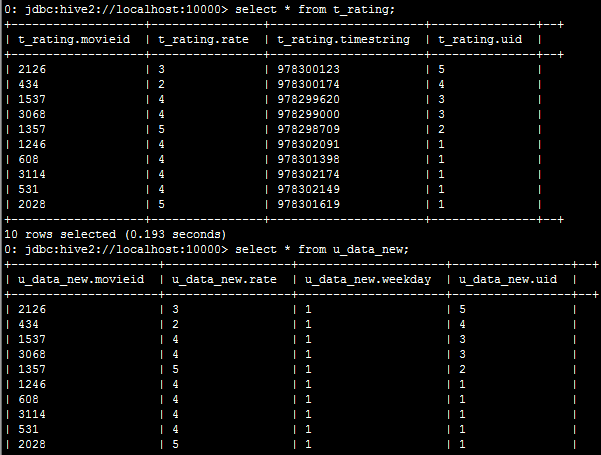
使用transform+python的方式去转换unixtime为weekday
11_Hive TransForm 案例的更多相关文章
- day11hadoop高可用和Hive
PS:视频一直就是在演示 高可用(比较偏运维一点) PS:Active是对外提供服务的,standBy是从属备用的:但是他们是怎样保证同步的数据的呢?一个运行中zookeeper上的第三方那个工具 ...
- Hive的DML操作
1. Load 在将数据加载到表中时,Hive 不会进行任何转换.加载操作是将数据文件移动到与 Hive表对应的位置的纯复制/移动操作. 语法结构: load data [local] inpath ...
- css3 知识点积累
-moz- 兼容火狐浏览器-webkit- 兼容chrome 和safari1.角度 transform:rotate(30dge) 水平线与div 第四象限30度 transform: ...
- 机械表小案例之transform的应用
这个小案例主要是对transform的应用. 时钟的3个表针分别是3个png图片,通过setInterval来让图片转动.时,分,秒的转动角度分别是30,6,6度. 首先,通过new Date函数获取 ...
- 56、Spark Streaming: transform以及实时黑名单过滤案例实战
一.transform以及实时黑名单过滤案例实战 1.概述 transform操作,应用在DStream上时,可以用于执行任意的RDD到RDD的转换操作.它可以用于实现,DStream API中所没有 ...
- H5案例分享:移动端滑屏 touch事件
移动端滑屏 touch事件 移动端触屏滑动的效果的效果在电子设备上已经被应用的越来越广泛,类似于PC端的图片轮播,但是在移动设备上,要实现这种轮播的效果,就需要用到核心的touch事件.处理touch ...
- 通过案例对 spark streaming 透彻理解三板斧之三:spark streaming运行机制与架构
本期内容: 1. Spark Streaming Job架构与运行机制 2. Spark Streaming 容错架构与运行机制 事实上时间是不存在的,是由人的感官系统感觉时间的存在而已,是一种虚幻的 ...
- 通过案例对 spark streaming 透彻理解三板斧之一: spark streaming 另类实验
本期内容 : spark streaming另类在线实验 瞬间理解spark streaming本质 一. 我们最开始将从Spark Streaming入手 为何从Spark Streaming切入 ...
- 精选19款华丽的HTML5动画和实用案例
下面是本人收集的19款超酷HTML5动画和实用案例,觉得不错,分享给大家. 1.HTML5 Canvas火焰喷射动画效果 还记得以前分享过的一款HTML5烟花动画HTML5 Canvas烟花特效,今天 ...
随机推荐
- asp.net mvc 中Html.ValidationSummary显示html
@if (!ViewData.ModelState.IsValid) { <div>@Html.Raw(HttpUtility.HtmlDecode(Html.ValidationSumm ...
- Fabric 查看zookeeper和kafka
进入kafka容器: sudo docker exec -it kafka bash cd opt/kafka 查看Kafka自动创建的topic bin/kafka-tipiccs.sh --lis ...
- [NOI2019]序列
LOJ3158 , Luogu5470 从 \(a_1\dots a_n\) , \(b_1\dots b_n\) 中各选出 \(K\) 个数 , 且至少 \(L\) 组下标在两个数组中都被选择 , ...
- IDEA插件之PMD
1.是什么? PMD 是一个开源静态源代码分析器,它报告在应用程序代码中发现的问题.PMD包含内置规则集,并支持编写自定义规则的功能.PMD不报告编译错误,因为它只能处理格式正确的源文件.PMD报告的 ...
- 【转载】SpringBoot-配置发送邮件遇到的一些问题
前言:前一天调用163邮箱发送邮件还么有问题,今天再调用就各种发送不成功,害的我都关闭授权,还花了一毛钱短信费重新开启授权,最后百度到了一篇文章,非常贴切,在此转载下. 本人遇到的错误代码是554,邮 ...
- poi 3061 尺取例题1
题目传送门/res tp poj 白书题 尺取法例题 #include<iostream> #include<algorithm> using namespace std; c ...
- NIT校赛-- 雷顿女士与平衡树
题意:https://ac.nowcoder.com/acm/contest/2995/E 给你一棵树,节点有权值,让你求所有路径max-min的和. 思路: 我们计算每个点的贡献,对于一个点,当它为 ...
- 为什么要使用 SPL中的 SplQueue实现队列
今天看php的SPL标准库部分里面涉及到数据结构其中有 SplQueue 来实现队列效果,但是我刚接触php的时候学习到的是 使用array的 array_push 和 array_pop 就可以实现 ...
- 关于python中的包,模块导入的问题详解(一)
最近由于初学python,对包,模块的导入问题进行了资料的搜集,查阅,在这里做一个总结: 一: import 模块 在import的过程中发生了什么?我们用一个实验来说明: 以上截图表明:在impor ...
- 计算机网络(TCP/IP)
概述:网络协议通常分不同的层次进行开发,每一层分别不同的通信功能.TCP/IP通常分为4层协议系统. 1.链路层,有时也称为数据链路层或者网络接口层,通常包括操作系统中的设备驱动程序和计算机中对应的网 ...