python中常用的九种预处理方法
本文总结的是我们大家在python中常见的数据预处理方法,以下通过sklearn的preprocessing模块来介绍;
1. 标准化(Standardization or Mean Removal and Variance Scaling)
变换后各维特征有0均值,单位方差。也叫z-score规范化(零均值规范化)。计算方式是将特征值减去均值,除以标准差。
|
1
|
sklearn.preprocessing.scale(X) |
一般会把train和test集放在一起做标准化,或者在train集上做标准化后,用同样的标准化器去标准化test集,此时可以用scaler
|
1
2
3
|
scaler = sklearn.preprocessing.StandardScaler().fit(train)scaler.transform(train)scaler.transform(test) |
实际应用中,需要做特征标准化的常见情景:SVM
2. 最小-最大规范化
最小-最大规范化对原始数据进行线性变换,变换到[0,1]区间(也可以是其他固定最小最大值的区间)
|
1
2
|
min_max_scaler = sklearn.preprocessing.MinMaxScaler()min_max_scaler.fit_transform(X_train) |
3.规范化(Normalization)
规范化是将不同变化范围的值映射到相同的固定范围,常见的是[0,1],此时也称为归一化。
将每个样本变换成unit norm。
|
1
2
|
X = [[ 1, -1, 2],[ 2, 0, 0], [ 0, 1, -1]]sklearn.preprocessing.normalize(X, norm='l2') |
得到:
|
1
|
array([[ 0.40, -0.40, 0.81], [ 1, 0, 0], [ 0, 0.70, -0.70]]) |
可以发现对于每一个样本都有,0.4^2+0.4^2+0.81^2=1,这就是L2
norm,变换后每个样本的各维特征的平方和为1。类似地,L1 norm则是变换后每个样本的各维特征的绝对值和为1。还有max
norm,则是将每个样本的各维特征除以该样本各维特征的最大值。
在度量样本之间相似性时,如果使用的是二次型kernel,需要做Normalization
4. 特征二值化(Binarization)
给定阈值,将特征转换为0/1
|
1
2
|
binarizer = sklearn.preprocessing.Binarizer(threshold=1.1)binarizer.transform(X) |
5. 标签二值化(Label binarization)
|
1
|
lb = sklearn.preprocessing.LabelBinarizer() |
6. 类别特征编码
有时候特征是类别型的,而一些算法的输入必须是数值型,此时需要对其编码。
|
1
2
3
|
enc = preprocessing.OneHotEncoder()enc.fit([[0, 0, 3], [1, 1, 0], [0, 2, 1], [1, 0, 2]])enc.transform([[0, 1, 3]]).toarray() #array([[ 1., 0., 0., 1., 0., 0., 0., 0., 1.]]) |
上面这个例子,第一维特征有两种值0和1,用两位去编码。第二维用三位,第三维用四位。
另一种编码方式
|
1
|
newdf=pd.get_dummies(df,columns=["gender","title"],dummy_na=True) |
7.标签编码(Label encoding)
|
1
2
3
4
5
6
|
le = sklearn.preprocessing.LabelEncoder() le.fit([1, 2, 2, 6]) le.transform([1, 1, 2, 6]) #array([0, 0, 1, 2]) #非数值型转化为数值型le.fit(["paris", "paris", "tokyo", "amsterdam"])le.transform(["tokyo", "tokyo", "paris"]) #array([2, 2, 1]) |
8.特征中含异常值时
|
1
|
sklearn.preprocessing.robust_scale |
9.生成多项式特征
这个其实涉及到特征工程了,多项式特征/交叉特征。
|
1
2
|
poly = sklearn.preprocessing.PolynomialFeatures(2)poly.fit_transform(X) |
原始特征: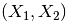
转化后: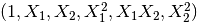
总结
以上就是为大家总结的python中常用的九种预处理方法分享,希望这篇文章对大家学习或者使用python能有一定的帮助,如果有疑问大家可以留言交流。
python中常用的九种预处理方法的更多相关文章
- python中常用的九种数据预处理方法分享
Spyder Ctrl + 4/5: 块注释/块反注释 本文总结的是我们大家在python中常见的数据预处理方法,以下通过sklearn的preprocessing模块来介绍; 1. 标准化(St ...
- python中常用的导包的方法和常用的库
python中常用的导包的方法 导入包和包名的方法:1.import package.module 2.from package.module import * 例一: ...
- css中常用的几种居中方法
在前端面试中,大都会问你div居中的方法: 文笔不好,就随便寥寥几句话概括了, 不过以后文笔肯定会变得更好一些的. 今天我们就细数一下几种方法: 1,使用position:absolute,设置lef ...
- Java常用的九种排序方法及代码实现
package com.algorithm.Demo; import java.util.ArrayList; import java.util.Arrays; import java.util.Li ...
- Python中class的三种继承方法
class parent(object): def implicit(self): print("Parent implicit()") def override(self): p ...
- 【转载】Python编程中常用的12种基础知识总结
Python编程中常用的12种基础知识总结:正则表达式替换,遍历目录方法,列表按列排序.去重,字典排序,字典.列表.字符串互转,时间对象操作,命令行参数解析(getopt),print 格式化输出,进 ...
- Python编程中常用的12种基础知识总结
原地址:http://blog.jobbole.com/48541/ Python编程中常用的12种基础知识总结:正则表达式替换,遍历目录方法,列表按列排序.去重,字典排序,字典.列表.字符串互转,时 ...
- C#中常用的几种读取XML文件的方法
1.C#中常用的几种读取XML文件的方法:http://blog.csdn.net/tiemufeng1122/article/details/6723764/
- .NET中常用的几种解析JSON方法
一.基本概念 json是什么? JSON:JavaScript 对象表示法(JavaScript Object Notation). JSON 是一种轻量级的数据交换格式,是存储和交换文本信息的语法. ...
随机推荐
- go context源码解析
go 的context贯穿整个goroutine的运行控制的中枢,可以实现执行的生命周期的控制. Context是一个接口,他派生了context.emptyCtx(TODO),cancelCtx,t ...
- linux centos7 开启 mysql 3306 端口 外网访问 的实践
第〇步:思路 3306 端口能否被外网访问,主要要考虑: (1)mysql的3306 端口是否开启?是否没有更改端口号? (2)mysql 是否允许3306 被外网访问? (3)linux 是否已经开 ...
- 基于Spring Boot的可直接运行的分布式ID生成器的实现以及SnowFlake算法详解
背景 最近对snowflake比较感兴趣,就看了一些分布式唯一ID生成器(发号器)的开源项目的源码,例如百度的uid-generator,美团的leaf.大致看了一遍后感觉uid-generator代 ...
- 最新 美团java校招面经 (含整理过的面试题大全)
从6月到10月,经过4个月努力和坚持,自己有幸拿到了网易雷火.京东.去哪儿.美团等10家互联网公司的校招Offer,因为某些自身原因最终选择了美团.6.7月主要是做系统复习.项目复盘.LeetCode ...
- STL源码剖析-学习笔记
1.模板是一个公式或是蓝图,本身不是类或是函数,需进行实例化的过程.这个过程是在编译期完成的,编译器根据传递的实参,推断出形参的类型,从而实例化相应的函数 2. 后续补充-.
- 南柯33的Python学习笔记第(一)部分
Python基础 1.Python简介 1.1 Python是什么编程语言 从编程语言的几个方向来说 编译型和解释型 什么是编译型?什么是解释型? 编译型:就是把源代码一下全部都编译成二进制文件(优点 ...
- [转帖]Linux 中的零拷贝技术,第 2 部分
Linux 中的零拷贝技术,第 2 部分 https://www.ibm.com/developerworks/cn/linux/l-cn-zerocopy2/index.html Linux 中 ...
- Word 查找替换高级玩法系列之 -- 替换手机号中间几位数字
1.打开"查找和替换"对话框.切换到"开始"选项卡,在"编辑"组中选择"替换".或者按下快捷键"Ctrl+H& ...
- Python之字符与编码笔记
概述 类型 str 字符串 bytes 字节 bytearray 字节数组 字符串编码架构 字符集:赋值一个编码到某个字符,以便在内存中表示 编码 Ecoding:转换字符到原始字节形式 解码 Dec ...
- C# LoadXml System.Xml.XmlException: Data at the root level is invalid. Line 1, position 1.
去掉BOM头 writer = new XmlTextWriter(stream, new UnicodeEncoding(false,false)); 如果是UTF8 writer = new Xm ...