python中常用的九种预处理方法
本文总结的是我们大家在python中常见的数据预处理方法,以下通过sklearn的preprocessing模块来介绍;
1. 标准化(Standardization or Mean Removal and Variance Scaling)
变换后各维特征有0均值,单位方差。也叫z-score规范化(零均值规范化)。计算方式是将特征值减去均值,除以标准差。
|
1
|
sklearn.preprocessing.scale(X) |
一般会把train和test集放在一起做标准化,或者在train集上做标准化后,用同样的标准化器去标准化test集,此时可以用scaler
|
1
2
3
|
scaler = sklearn.preprocessing.StandardScaler().fit(train)scaler.transform(train)scaler.transform(test) |
实际应用中,需要做特征标准化的常见情景:SVM
2. 最小-最大规范化
最小-最大规范化对原始数据进行线性变换,变换到[0,1]区间(也可以是其他固定最小最大值的区间)
|
1
2
|
min_max_scaler = sklearn.preprocessing.MinMaxScaler()min_max_scaler.fit_transform(X_train) |
3.规范化(Normalization)
规范化是将不同变化范围的值映射到相同的固定范围,常见的是[0,1],此时也称为归一化。
将每个样本变换成unit norm。
|
1
2
|
X = [[ 1, -1, 2],[ 2, 0, 0], [ 0, 1, -1]]sklearn.preprocessing.normalize(X, norm='l2') |
得到:
|
1
|
array([[ 0.40, -0.40, 0.81], [ 1, 0, 0], [ 0, 0.70, -0.70]]) |
可以发现对于每一个样本都有,0.4^2+0.4^2+0.81^2=1,这就是L2
norm,变换后每个样本的各维特征的平方和为1。类似地,L1 norm则是变换后每个样本的各维特征的绝对值和为1。还有max
norm,则是将每个样本的各维特征除以该样本各维特征的最大值。
在度量样本之间相似性时,如果使用的是二次型kernel,需要做Normalization
4. 特征二值化(Binarization)
给定阈值,将特征转换为0/1
|
1
2
|
binarizer = sklearn.preprocessing.Binarizer(threshold=1.1)binarizer.transform(X) |
5. 标签二值化(Label binarization)
|
1
|
lb = sklearn.preprocessing.LabelBinarizer() |
6. 类别特征编码
有时候特征是类别型的,而一些算法的输入必须是数值型,此时需要对其编码。
|
1
2
3
|
enc = preprocessing.OneHotEncoder()enc.fit([[0, 0, 3], [1, 1, 0], [0, 2, 1], [1, 0, 2]])enc.transform([[0, 1, 3]]).toarray() #array([[ 1., 0., 0., 1., 0., 0., 0., 0., 1.]]) |
上面这个例子,第一维特征有两种值0和1,用两位去编码。第二维用三位,第三维用四位。
另一种编码方式
|
1
|
newdf=pd.get_dummies(df,columns=["gender","title"],dummy_na=True) |
7.标签编码(Label encoding)
|
1
2
3
4
5
6
|
le = sklearn.preprocessing.LabelEncoder() le.fit([1, 2, 2, 6]) le.transform([1, 1, 2, 6]) #array([0, 0, 1, 2]) #非数值型转化为数值型le.fit(["paris", "paris", "tokyo", "amsterdam"])le.transform(["tokyo", "tokyo", "paris"]) #array([2, 2, 1]) |
8.特征中含异常值时
|
1
|
sklearn.preprocessing.robust_scale |
9.生成多项式特征
这个其实涉及到特征工程了,多项式特征/交叉特征。
|
1
2
|
poly = sklearn.preprocessing.PolynomialFeatures(2)poly.fit_transform(X) |
原始特征: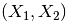
转化后: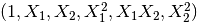
总结
以上就是为大家总结的python中常用的九种预处理方法分享,希望这篇文章对大家学习或者使用python能有一定的帮助,如果有疑问大家可以留言交流。
python中常用的九种预处理方法的更多相关文章
- python中常用的九种数据预处理方法分享
Spyder Ctrl + 4/5: 块注释/块反注释 本文总结的是我们大家在python中常见的数据预处理方法,以下通过sklearn的preprocessing模块来介绍; 1. 标准化(St ...
- python中常用的导包的方法和常用的库
python中常用的导包的方法 导入包和包名的方法:1.import package.module 2.from package.module import * 例一: ...
- css中常用的几种居中方法
在前端面试中,大都会问你div居中的方法: 文笔不好,就随便寥寥几句话概括了, 不过以后文笔肯定会变得更好一些的. 今天我们就细数一下几种方法: 1,使用position:absolute,设置lef ...
- Java常用的九种排序方法及代码实现
package com.algorithm.Demo; import java.util.ArrayList; import java.util.Arrays; import java.util.Li ...
- Python中class的三种继承方法
class parent(object): def implicit(self): print("Parent implicit()") def override(self): p ...
- 【转载】Python编程中常用的12种基础知识总结
Python编程中常用的12种基础知识总结:正则表达式替换,遍历目录方法,列表按列排序.去重,字典排序,字典.列表.字符串互转,时间对象操作,命令行参数解析(getopt),print 格式化输出,进 ...
- Python编程中常用的12种基础知识总结
原地址:http://blog.jobbole.com/48541/ Python编程中常用的12种基础知识总结:正则表达式替换,遍历目录方法,列表按列排序.去重,字典排序,字典.列表.字符串互转,时 ...
- C#中常用的几种读取XML文件的方法
1.C#中常用的几种读取XML文件的方法:http://blog.csdn.net/tiemufeng1122/article/details/6723764/
- .NET中常用的几种解析JSON方法
一.基本概念 json是什么? JSON:JavaScript 对象表示法(JavaScript Object Notation). JSON 是一种轻量级的数据交换格式,是存储和交换文本信息的语法. ...
随机推荐
- Turbine聚合https微服务
- thinkphp5 引用 phpass加密算法
引入phpass thinkPHP5 放到扩展目录里 自动加载配置 直接实例化 // 初始化散列器为不可移植(这样更安全) $PasswordHashs = new \PasswordHashs(8, ...
- [CF788B]Weird journey_欧拉回路
Weird journey 题目链接:http://codeforces.com/contest/788/problem/B 数据范围:略. 题解: 我们发现就是要求,把每条无向边拆成两条无向边,其中 ...
- 为什么 Python 中的 True 等于 1
开始的时候,需要用以下函数来做一个判断,根据返回的值来做一些后续判断处理: def is_success(param): if not param: return False return True ...
- Paypal、Stripe、Braintree,跨境电商金流第三方支付该用哪家?
在台湾做跨境电子商务生意,电商网站的金流肯定是一个最大的麻烦,Paypal或是Stripe和Braintree则是国际上大家最常用的金流整合第三方支付服务商.这些金流服务大幅简化网站付费过程,都让消费 ...
- Excel常用操作1
1.数据透视 所在选项卡:插入-数据透视表 例如:查看下表中各个工龄的平均工资 数据透视:选择所有数据--数据透视表--数据透视字段:选择工作经验和salary 切片器的使用,根据工作经验进行切片(还 ...
- Oracle查询部门工资最高员工的两种方法 1、MAX()函数 2、RANK()函数
本文以SCOTT用户下初始的EMP表为参考.代码可直接使用. 查询EMP表结构的语句如下,[代码1]: DESC EMP; EMP表结构如下:[结果1]: SQL> DESC EMP ...
- zcat +文件名.gz | grep "查找内容"
linux gz查看 zcat +文件名.gz | grep "查找内容" 解压 rar x xxxx.rar
- java——内存中的数组
数组是一种引用类型,数组引用变量只是一个引用,数组元素和数组变量在内存中时分开存放的,下面我们看一下基本类型的数组和引用类型的数组在内存中的地址分布情况 基本类型数组: 我们先来看一段代码: publ ...
- 为什么用JS取不到cookie的值?解决方法如下!
注意:cookie是基于域名来储存的.要放到测试服务器上或者本地localhost服务器上才会生效.cookie具有不同域名下储存不可共享的特性.单纯的本地一个html页面打开是无效的. 明明在浏览中 ...