Solr6.6 配置中文分词库mmseg4j
1、准备
首先安装solr:参照搜索引擎Solr-6.6.0搭建,如果版本高于6,可能会不支持,需要改mmseg4j包
mmseg4j包下载: mmseg4j-solr-2.3.0-with-mmseg4j-core.zip 或https://pan.baidu.com/s/1dD7qMFf#list/path=%2F
开源地址:https://github.com/chenlb/mmseg4j-solr
解压下载的压缩包mmseg4j-solr-2.3.0-with-mmseg4j-core.zip,得到mmseg4j-core-1.10.0.jar和mmseg4j-solr-2.3.0.jar把这两个文件拷贝到tomcat的webapps\solr\WEB-INF\lib路径下

2、建立core
建立mycore,具体参见搜索引擎Solr-6.6.0搭建的“四、Solr6.6.0环境搭建”部分。
3、修改配置文件
修改mycore/conf的配置文件managed-schema,增加以下内容:
<!-- mmseg4j fieldType-->
<fieldType name="text_mmseg4j_complex" class="solr.TextField" positionIncrementGap="100" >
<analyzer>
<tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory" mode="complex" />
</analyzer>
</fieldType>
<fieldType name="text_mmseg4j_maxword" class="solr.TextField" positionIncrementGap="100" >
<analyzer>
<tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory" mode="max-word" />
</analyzer>
</fieldType>
<fieldType name="text_mmseg4j_simple" class="solr.TextField" positionIncrementGap="100" >
<analyzer>
<tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory" mode="simple" />
</analyzer>
</fieldType>
启动重新启动tomcat,在浏览器中输入http://localhost:8080/solr/index.html,
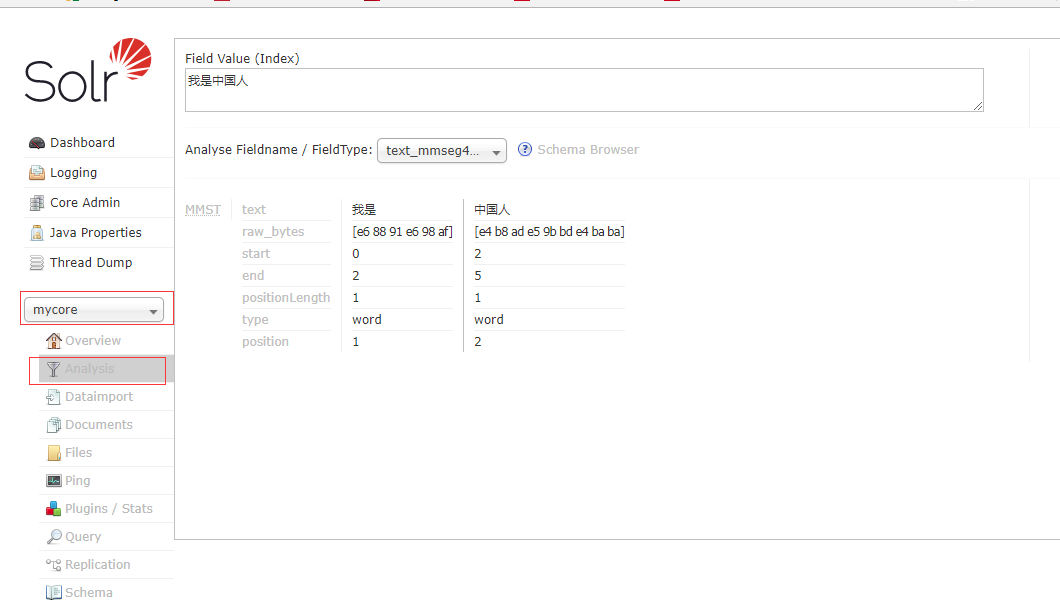
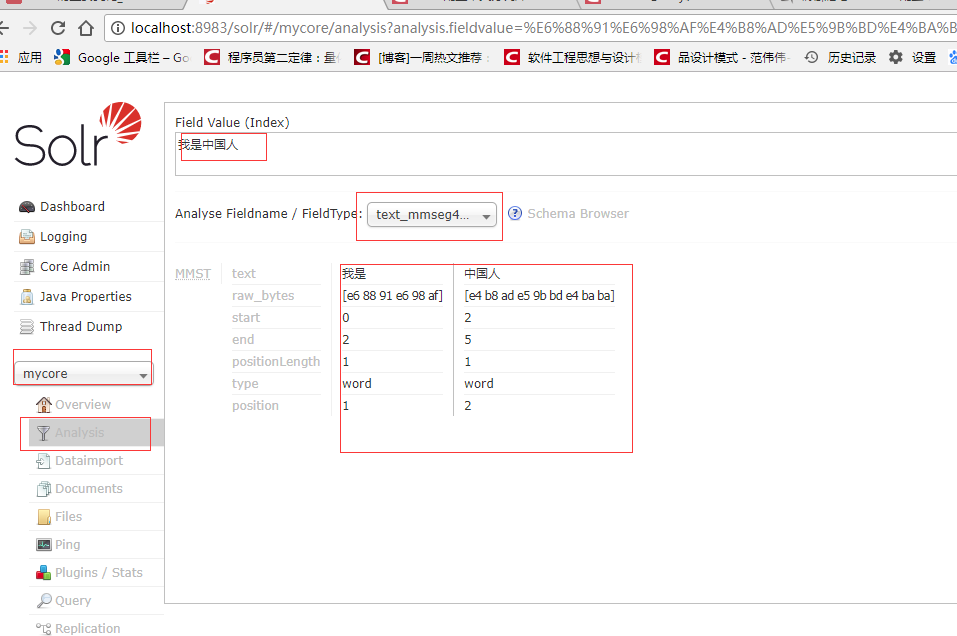
在管理界面选择分析,输入“我是中国人” 类型选择上面的三种的一种进行分析如下:
4、直接启动solr自带的Jetty,不用tomcat
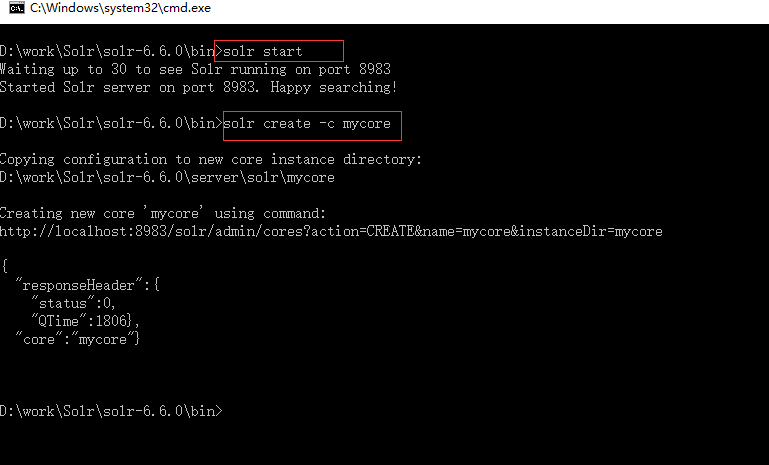
进入solr6.6的bin目录,启动solr,通过命令建立core
solr create -c mycore
这样在solr-6.6.0\server\solr目录下生成mycore

修改mycore\conf文件夹下的配置文件managed-schema,在最后新增一项内容
<!-- mmseg4j fieldType-->
<fieldType name="text_mmseg4j_complex" class="solr.TextField" positionIncrementGap="100" >
<analyzer>
<tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory" mode="complex" />
</analyzer>
</fieldType>
<fieldType name="text_mmseg4j_maxword" class="solr.TextField" positionIncrementGap="100" >
<analyzer>
<tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory" mode="max-word" />
</analyzer>
</fieldType>
<fieldType name="text_mmseg4j_simple" class="solr.TextField" positionIncrementGap="100" >
<analyzer>
<tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory" mode="simple" />
</analyzer>
</fieldType>
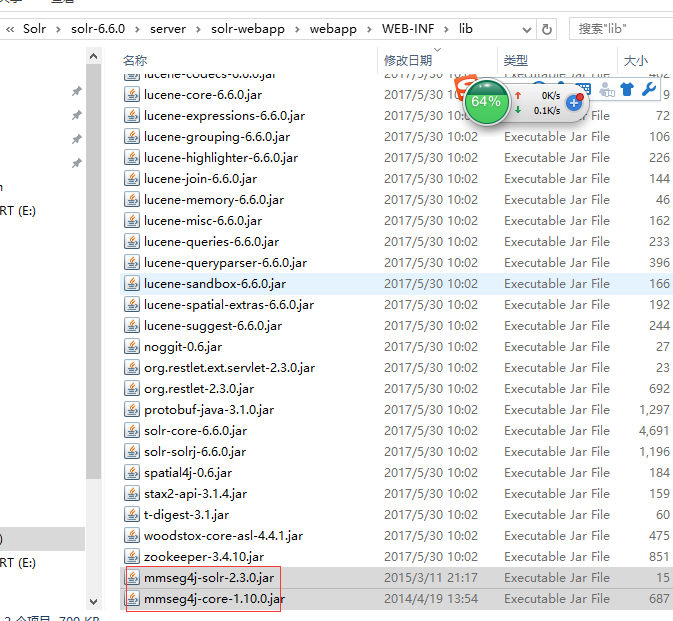
把mmseg4j-core-1.10.0.jar和mmseg4j-solr-2.3.0.jar拷贝到solr-6.6.0\server\solr-webapp\webapp\WEB-INF\lib文件夹下
执行命令solr stop -all
重新启动solr
重新打开浏览器输入:http://localhost:8983/solr/#/
或者直接修改solr-6.6.0\server\solr\configsets\data_driven_schema_configs\conf文件夹下的配置文件managed-schema,在最后新增以下内容:
<!-- mmseg4j fieldType-->
<fieldType name="text_mmseg4j_complex" class="solr.TextField" positionIncrementGap="100" >
<analyzer>
<tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory" mode="complex" />
</analyzer>
</fieldType>
<fieldType name="text_mmseg4j_maxword" class="solr.TextField" positionIncrementGap="100" >
<analyzer>
<tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory" mode="max-word" />
</analyzer>
</fieldType>
<fieldType name="text_mmseg4j_simple" class="solr.TextField" positionIncrementGap="100" >
<analyzer>
<tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory" mode="simple" />
</analyzer>
</fieldType>
这样在新建core的时候就不用每次都修改单个core的managed-schema配置文件了
参照资料:http://blog.csdn.net/jiangchao858/article/details/53026374
Solr6.6 配置中文分词库mmseg4j的更多相关文章
- 转:solr6.0配置中文分词器IK Analyzer
solr6.0中进行中文分词器IK Analyzer的配置和solr低版本中最大不同点在于IK Analyzer中jar包的引用.一般的IK分词jar包都是不能用的,因为IK分词中传统的jar不支持s ...
- 我与solr(六)--solr6.0配置中文分词器IK Analyzer
转自:http://blog.csdn.net/linzhiqiang0316/article/details/51554217,表示感谢. 由于前面没有设置分词器,以至于查询的结果出入比较大,并且无 ...
- Solr6.5配置中文分词IKAnalyzer和拼音分词pinyinAnalyzer (二)
之前在 Solr6.5在Centos6上的安装与配置 (一) 一文中介绍了solr6.5的安装.这篇文章主要介绍创建Solr的Core并配置中文IKAnalyzer分词和拼音检索. 一.创建Core: ...
- Solr6.5配置中文分词器
Solr作为搜索应用服务器,我们在使用过程中,不可避免的要使用中文搜索.以下介绍solr自带的中文分词器和第三方分词器IKAnalyzer. 注:下面操作在Linux下执行,所添加的配置在windo ...
- Hanlp等七种优秀的开源中文分词库推荐
Hanlp等七种优秀的开源中文分词库推荐 中文分词是中文文本处理的基础步骤,也是中文人机自然语言交互的基础模块.由于中文句子中没有词的界限,因此在进行中文自然语言处理时,通常需要先进行分词. 纵观整个 ...
- Slackware Linux or FreeBSD 配置中文环境。
配置中文环境. Slackware Linux 如果在控制面板的语言与地区选项中没有找到中文,那说明在安装系统选择软件的时候没有将国际语言支持包选上,可以从slackware的安装盘或ISO文件中提取 ...
- centos7 学习1 KDE配置中文
安装kde桌面后没有中文,可以用以下方法配置中文 #yum list kde*chinese 会显示可以安装的包,我的显示如下 kde-l10n-Chinese.noarch -.fc14 @upda ...
- 沈逸老师ubuntu速学笔记(1)--安装flashplayer,配置中文输入法以及常用命令
开篇首先感谢程序员在囧途(www.jtthink.com)以及沈逸老师,此主题笔记主要来源于沈老师课程.同时也感谢少年郎,秦少.花旦等同学分享大家的学习笔记. 1.安装flash player ctr ...
- 5.Solr4.10.3中配置中文分词器
转载请出自出处:http://www.cnblogs.com/hd3013779515/ 1.下载IK Analyzer 2012FF_hf1.zip并上传到/home/test 2.按照如下命令安装 ...
随机推荐
- mysql六:索引原理与慢查询优化
一 介绍 为何要有索引? 一般的应用系统,读写比例在10:1左右,而且插入操作和一般的更新操作很少出现性能问题,在生产环境中,我们遇到最多的,也是最容易出问题的,还是一些复杂的查询操作,因此对查询语句 ...
- 定制一个支持中英文的简单LaTex模板
平常写汇报文档什么的,word排版有时还是比较费劲,遂定制一个简单的LaTex模板,中文默认为宋体,英文为LaTex默认字体,支持彩色高亮展示,有目录书签,有页眉展示,大致如下: LaTex代码如下: ...
- owasp zap 安全审计工具 功能详解
一.persist session 该功能主要保存扫描分析的结果,方便下次继续分析 二.扫描策略 1.修改策略 A.入口 B.具体设置页面 C.设置完成后,发起主动扫描,在弹出的窗口可以选择策略 D. ...
- 执行程序(例如UltraEdit)在WIN7下添加到右键菜单
把下面提供的代码复制到记事本,保存为注册表文件(*.reg),右键合并即可.注意把最后一行换成你自己的路径. Windows Registry Editor Version 5.00 [HKEY_CL ...
- ZCMU训练赛-B(dp/暴力)
B - Break Standard Weight The balance was the first mass measuring instrument invented. In its tradi ...
- HDU 2829 Lawrence
$dp$,斜率优化. 设$dp[i][j]$表示前$i$个数字切了$j$次的最小代价.$dp[i][j]=dp[k][j-1]+p[k+1][i]$.观察状态转移方程,可以发现是一列一列推导出来的.可 ...
- 二分+Kruskal【p2798】爆弹虐场
Description 某年某月某日,Kiana 结识了一名爆弹虐场的少年. Kiana 仗着自己多学了几年OI,所以还可以勉勉强强给这位少年 讲一些自己擅长的题.具体来说,Kiana 先给这位少年灌 ...
- SQL Loader with utf8
alter this line in your control file characterset UTF8 to this characterset UTF8 length semantics ch ...
- struts2 action 字段问题
struts2最多只能解释两级字段,比如user.username,像user.info.age在类中属性类的三段字符不能识别,只能先用user,info 然后在user.setInfo(info);
- [BZOJ2655]calc(拉格朗日插值法+DP)
2655: calc Time Limit: 30 Sec Memory Limit: 512 MBSubmit: 428 Solved: 246[Submit][Status][Discuss] ...