Hadoop(17)-MapReduce框架原理-MapReduce流程,Shuffle机制,Partition分区
MapReduce工作流程
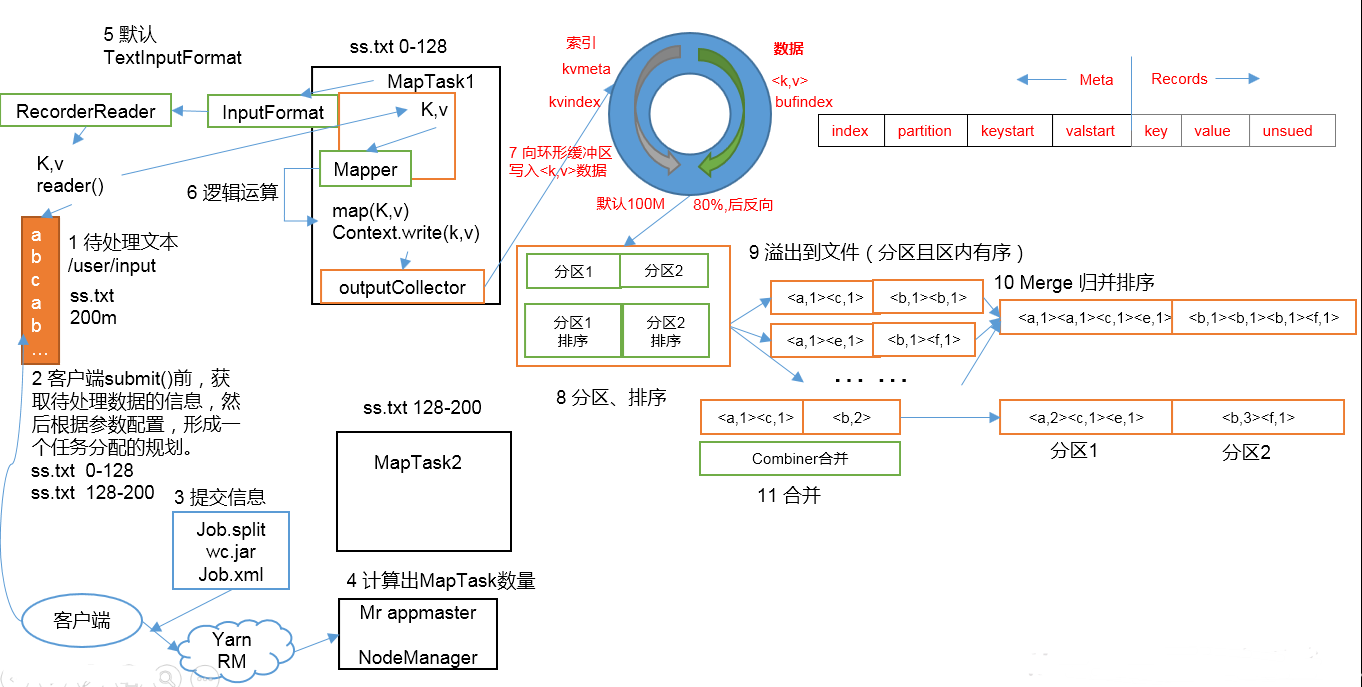
1.准备待处理文件
2.job提交前生成一个处理规划
3.将切片信息job.split,配置信息job.xml和我们自己写的jar包交给yarn
4.yarn根据切片规划计算出MapTask的数量
(以一个MapTask为例)
5.Maptask调用inputFormat生成RecordReader,将自己处理的切片文件内容打散成K,V值
6.MapTask将打散好的K,V值交给Mapper,Mapper经过一系列的处理将KV值写出
7.写出的KV值被outputCollector收集起来,写入一个在内存的环形缓冲区
8,9.当环形缓冲区被写入的空间等于80%时,会触发溢写.此时数据是在内存中,所以在溢写之前,会对数据进行排序,是一个二次排序的快排(先根据分区排序再根据key排序).然后将数据有序的写入到磁盘上.
缓冲区为什么是环形的?这样做是为了可以在缓冲区的任何地方进行数据的写入.

当第一次溢写时,数据会从余下的20%空间中的中间位置,再分左右继续写入,也就是从第一次是从上往下写数据变成了从下往上写数据
10,11.当多次溢写产生多个有序的文件后,会触发归并排序,将多个有序的文件合并成一个有序的大文件.当文件数>=10个时,会触发归并排序,取文件的一小部分放入内存的缓冲区,再生成一个小文件部分大小x文件数的缓冲区,逐个比较放入大文件缓冲区,依次比较下去,再将大文件缓冲写入到磁盘,归并结束后将大文件放在文件列表的末尾,继续重复此动作,直到合并成一个大文件.此次归并排序的时间复杂度要求较低.
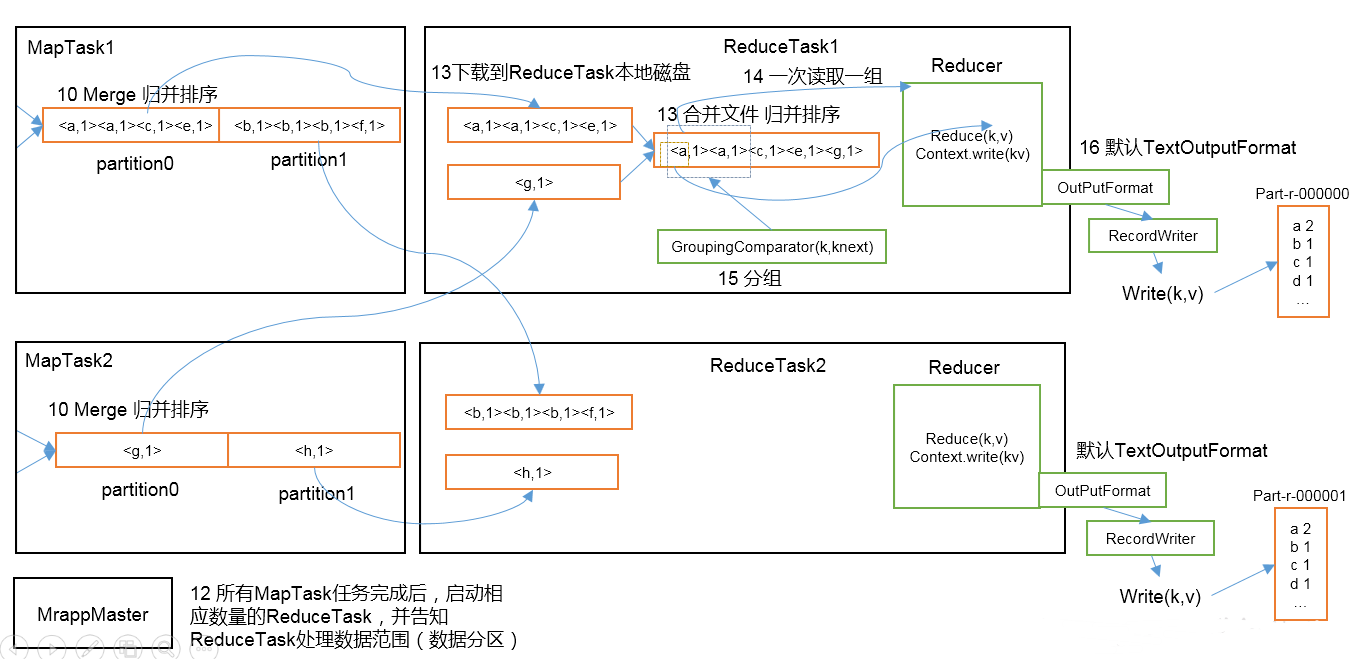
12.当所有的MapTask执行完任务后,启动相应数量的ReduceTask,并告知每一个ReduceTask应该处理的数据分区
13.ReduceTask将指定分区的文件下载到本地,如有多个分区文件的话,ReduceTask上将会有多个大文件,再一次归并排序,形成一个大文件.
14.15,如果有分组要求的话,ReduceTask会将数据一组一组的交给Reduce,处理完后准备将数据写出
16.Reduce调用output生成RecordWrite将数据写入到指定路径中
Shuffle机制
上图中,数据从Mapper写出来之后到数据进入到Reduce之前,这一阶段就叫做Shuffle
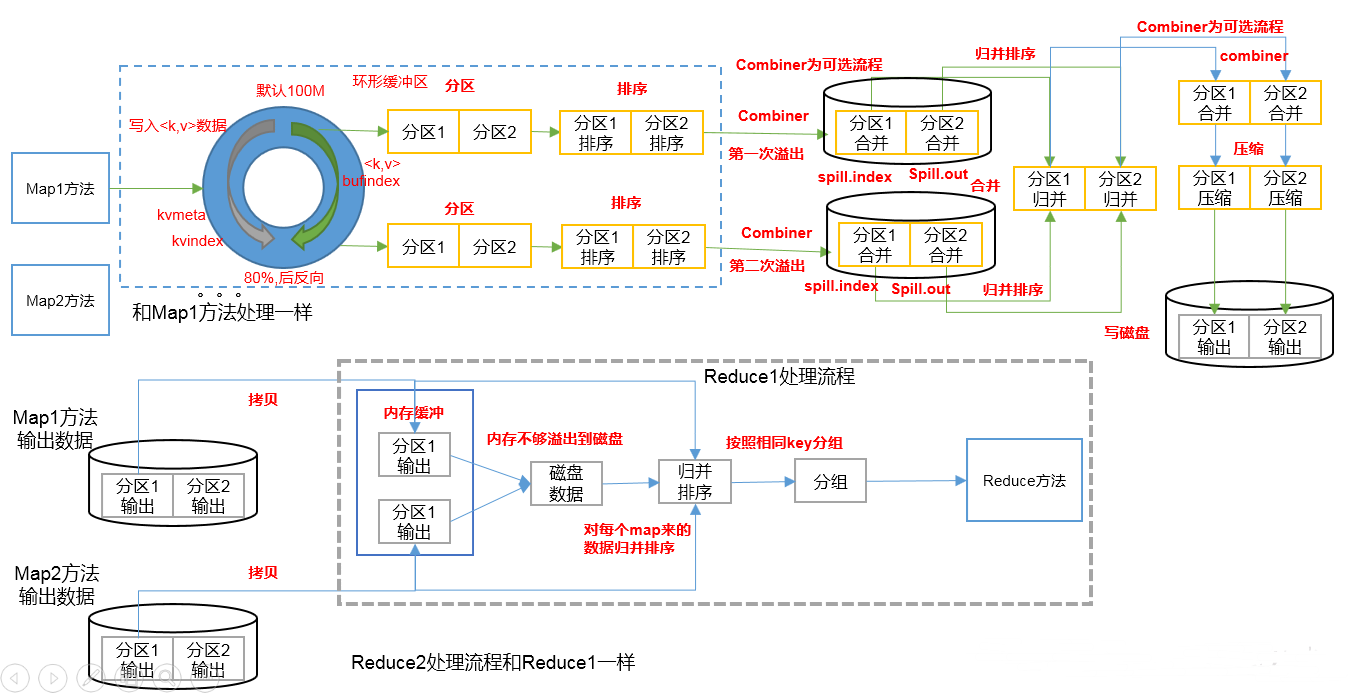
Shuffle时,会有三次排序,第一次是数据从环形缓冲区写入到磁盘时,会有一次快排,第二次是在MapTask中,将多个分区且内部有序的小文件归并成一个分区且内部有序的大文件,第三次是在ReduceTask中,从多个MapTask中获取指定分区的大文件,再进行一个归并排序,合并成一个大文件.
以WordCount为例,试想一下,在第一次从环形缓冲区写入到磁盘时,排好序的数据为(w1,1),(w1,1),(w1,1),(w2,1),(w2,1),(w3,1),这样的数据会增加网络传输量,所以在这里可以使用Combiner进行数据合并.最后形成的数据是(w1,3),(w2,2),(w3,1),后续会详细讲解~
Partition分区
将Mapper想象成一个水池,数据是池里的水.默认分一个区,只有一根水管.如果只有一个ReduceTask,则水会全部顺着唯一的水管流入到ReduceTask中.如果此时有3根水管,则水会被分成三股水流流入到3个ReduceTask中,而且哪些水进哪个水管,并不受我们主观控制,也就是数据处理速度加快了~~Partition分区就决定了分几根水管.试想一下,如果有4根水管,末端只有3个ReduceTask,那么有一股水流会丢失.也就是造成数据丢失,程序会报错.如果只有2根水管,那么则有一个ReduceTask无事可做,最后生成的是一个空文件,浪费资源
所以,一般来说,有几个ReduceTask就要分几个区,至于partition和ReduceTask设置为几,要看集群性能,数据集,业务,经验等等~
对应流程图上,也就是从环形缓冲区写入到磁盘时,会分区



collector出现了,除了将key,value收集到缓冲区中之外,还收集了partition分区


key.hashCode() & Integer.MAX_VALUE,保证取余前的数为正数
比如,numReduceTasks = 3, 一个数n对3取余,结果会有0,1,2三种可能,也就是分三个区,再一次印证了要 reduceTask number = partition number
默认分区是根据key的hashcode和reduceTasks的个数取模得到的,用户无法控制哪个key存储到哪个分区上
案例演练
以12小章的统计流量案例为例,大数据-Hadoop生态(12)-Hadoop序列化和源码追踪
将手机号136、137、138、139开头都分别放到一个独立的4个文件中,其他开头的放到一个文件中
自定义Partition类
package com.atguigu.partitioner; import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner; public class MyPartitioner extends Partitioner<Text, FlowBean> {
public int getPartition(Text text, FlowBean flowBean, int numPartitions) {
//1. 截取手机前三位
String start = text.toString().substring(0, 3); //2. 按照手机号前三位返回分区号
switch (start) {
case "136":
return 0;
case "137":
return 1;
case "138":
return 2;
case "139":
return 3;
default:
return 4;
} }
}
Driver类的main()中增加以下代码
job.setPartitionerClass(MyPartitioner.class); job.setNumReduceTasks(5);
输出结果,5个文件

如果job.setNumReduceTasks(10),会生成10个文件,其中5个是空文件
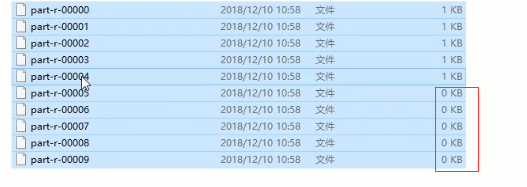
如果job.setNumReduceTasks(2),程序会直接执行失败报异常

如果job.setNumReduceTasks(1),程序会运行成功,因为如果numReduceTasks=1时,根本就不会执行分区的过程
如果是以下情况,也会执行失败.MapReduce会认为你分了41个区,所以分区号必须从0开始,逐一累加.
job.setNumReduceTasks(5)
switch (start) {
case "136":
return 0;
case "137":
return 1;
case "138":
return 2;
case "139":
return 3;
default:
return 40;
}

Hadoop(17)-MapReduce框架原理-MapReduce流程,Shuffle机制,Partition分区的更多相关文章
- MapReduce框架中的Shuffle机制
Shuffle是map和reduce中间的数据调度过程,包括:缓存.分区.排序等. Shuffle数据调度过程: map task处理hdfs文件,调用map()方法,map task的collect ...
- java大数据最全课程学习笔记(6)--MapReduce精通(二)--MapReduce框架原理
目前CSDN,博客园,简书同步发表中,更多精彩欢迎访问我的gitee pages 目录 MapReduce精通(二) MapReduce框架原理 MapReduce工作流程 InputFormat数据 ...
- MapReduce框架原理--Shuffle机制
Shuffle机制 Mapreduce确保每个reducer的输入都是按键排序的.系统执行排序的过程(Map方法之后,Reduce方法之前的数据处理过程)称之为Shuffle. partition分区 ...
- 【hadoop代码笔记】Mapreduce shuffle过程之Map输出过程
一.概要描述 shuffle是MapReduce的一个核心过程,因此没有在前面的MapReduce作业提交的过程中描述,而是单独拿出来比较详细的描述. 根据官方的流程图示如下: 本篇文章中只是想尝试从 ...
- hadoop笔记之MapReduce的运行流程
MapReduce的运行流程 MapReduce的运行流程 基本概念: Job&Task:要完成一个作业(Job),就要分成很多个Task,Task又分为MapTask和ReduceTask ...
- MapReduce实例2(自定义compare、partition)& shuffle机制
MapReduce实例2(自定义compare.partition)& shuffle机制 实例:统计流量 有一份流量数据,结构是:时间戳.手机号.....上行流量.下行流量,需求是统计每个用 ...
- MapReduce(五) mapreduce的shuffle机制 与 Yarn
一.shuffle机制 1.概述 (1)MapReduce 中, map 阶段处理的数据如何传递给 reduce 阶段,是 MapReduce 框架中最关键的一个流程,这个流程就叫 Shuffle:( ...
- hadoop的mapReduce和Spark的shuffle过程的详解与对比及优化
https://blog.csdn.net/u010697988/article/details/70173104 大数据的分布式计算框架目前使用的最多的就是hadoop的mapReduce和Spar ...
- MapReduce框架原理
MapReduce框架原理 3.1 InputFormat数据输入 3.1.1 切片与MapTask并行度决定机制 1.问题引出 MapTask的并行度决定Map阶段的任务处理并发度,进而影响到整个J ...
随机推荐
- wxpython grid
构建Grid方法,效果如下: 其它构建grid方法和grid的使用见:还可以见下载资源中的wxpython教程第5章的 gridGeneric.py gridModel.py gridNoModel. ...
- python 后台运行命令
nohup python a.py > a.log 2>&1 & 在窗口中单开虚拟session: tmux new -s "name" 推出虚拟窗口 ...
- Mysql 服务无法启动解决办法
1.我使用的是MySQL-5.7.10-winx64 版本,在安装后启动服务时出现 “服务无法启动”错误 2.解决办法为删除安装目录中的data文件,然后打开cmd调到自己的安装目录下输入mysqld ...
- Python 基于固定 IP 来命名 ARM 虚拟机的实现
问题描述 希望通过 Python 批量创建 ARM 虚拟机,并且在虚拟机命名时加入固定 IP 信息,方便管理维护. 问题分析 在创建 ARM 虚拟机之前,先创建固定 IP,然后获取固定 IP 地址,创 ...
- Web系统常见安全漏洞及解决方案-SQL盲注
关于web安全测试,目前主要有以下几种攻击方法: 1.XSS 2.SQL注入 3.跨目录访问 4.缓冲区溢出 5.cookies修改 6.Htth方法篡改(包括隐藏字段修改和参数修改) 7.CSRF ...
- 玩得一手好注入之order by排序篇
看了之前Gr36_前辈在先知上的议题,其中有提到排序注入,这个在最近经常遇到这样的问题,所以先总结下order by 排序注入的知识. 0×00 背景 看了之前Gr36_前辈在先知上的议题,其中有提到 ...
- day009-IO流
什么叫流?就是数据的流动.以内存为基准,分为输入input和输出output.输入也叫做读取数据,输出也叫写出数据. 分类 按数据的流向分: 输入流.输出流 按数据类型分: 字节流.字符流 1. ...
- HDU 1853 MCMF
题意:给定一个有向带权图,使得每一个点都在一个环上,而且权之和最小. 分析:每个点在一个环上,入度 = 出度 = 1,拆点入点,出点,s到所有入点全部满载的最小费用MCMF; #include < ...
- Uva 10061 进制问题
题目大意:让求n!在base进制下的位数以及末尾0的连续个数. 多少位 log_{10}256=log_{10}210^2+log_{10}510^1+log_{10}6*10^0 可以发现,只和最高 ...
- 2018.10.30 mac环境下卸载和安装mysql及安装过程遇到的一些问题解决方案
Mac下mysql的安装与卸载 配置初始化密码修改 第一:首先去官网网站下载Mysql软件 https://downloads.mysql.com/archives/community/ 记住选择对应 ...