Word2Vec词向量(一)
一、词向量基础(一)来源背景
word2vec是google在2013年推出的一个NLP工具,它的特点是将所有的词向量化,这样词与词之间就可以定量的去度量他们之间的关系,挖掘词之间的联系。虽然源码是开源的,但是谷歌的代码库国内无法访问,
因此本文的讲解word2vec原理以Github上的word2vec代码为准。
最早的词向量是使用one-hot编码表示的(就是有多少个词就有多少维度,每个词对应的位置是1, 其他位置是0), 如下图:
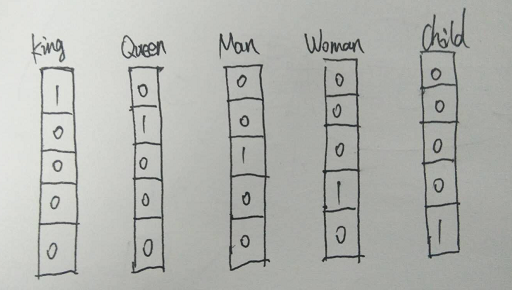
这样表示最大的确定就是我们的词汇表一般都非常大,比如达到百万级别,这样每个词都用百万维的向量来表示简直是内存的灾难。
分布式表示可以解决One-hot方式的问题,它的思路是通过训练,将每个词都映射到一个较短的词向量上来。所有的这些词向量就构成了向量空间,
进而可以用普通的统计学的方法来研究词与词之间的关系。这个较短的词向量维度是多大呢?这个一般需要我们在训练时自己来指定。
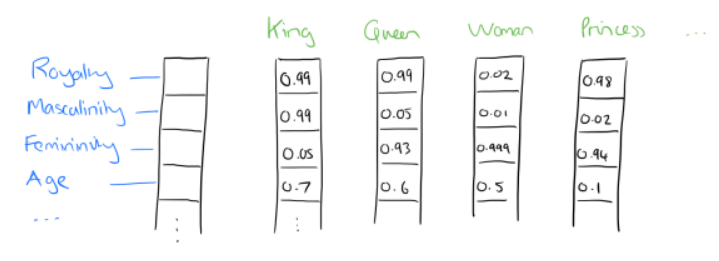
比如下图我们将词汇表里的词用"Royalty","Masculinity", "Femininity"和"Age"4个维度来表示,King这个词对应的词向量可能是(0.99,0.99,0.05,0.7)(0.99,0.99,0.05,0.7)。
当然在实际情况中,我们并不能对词向量的每个维度做一个很好的解释。
有了用分布式表示的较短的词向量,我们就可以较容易的分析词之间的关系了,比如我们将词的维度降维到2维,有一个有趣的研究表明,用下图的词向量表示我们的词时,我们可以发现:
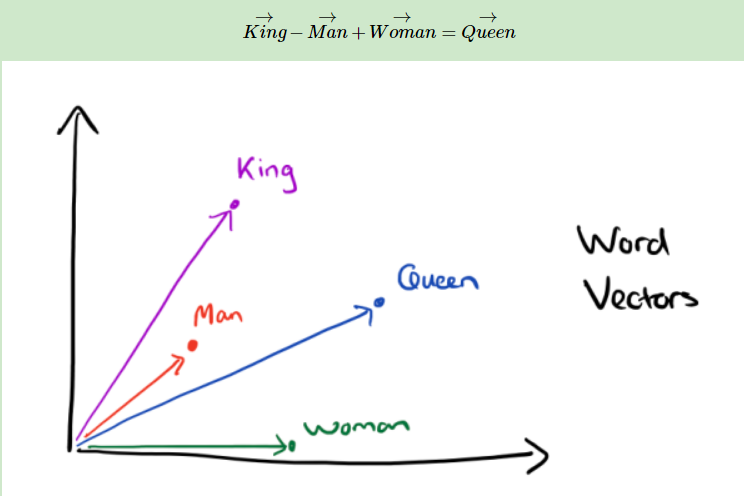
可见我们只要得到了词汇表里所有词对应的词向量,那么我们就可以做很多有趣的事情了。不过,怎么训练得到合适的词向量呢?一个很常见的方法是使用神经网络语言模型。
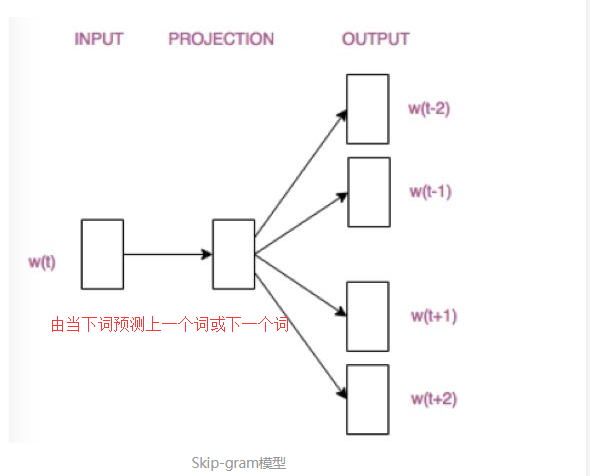
二、词向量基础(CBOW与Skip-Gram模型)
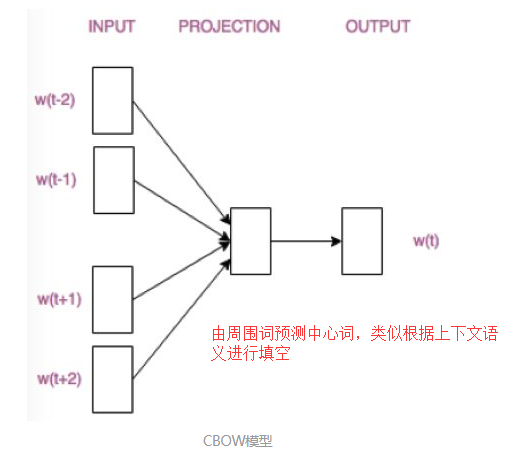
通俗解释:
CBOW((Continuous Bag-of-Words)模型根据中心词W(t)周围的词来预测中心词
Skip-gram模型则根据中心词W(t)来预测周围词
Word2Vec词向量(一)的更多相关文章
- 文本分布式表示(三):用gensim训练word2vec词向量
今天参考网上的博客,用gensim训练了word2vec词向量.训练的语料是著名科幻小说<三体>,这部小说我一直没有看,所以这次拿来折腾一下. <三体>这本小说里有不少人名和一 ...
- word2vec词向量训练及中文文本类似度计算
本文是讲述怎样使用word2vec的基础教程.文章比較基础,希望对你有所帮助! 官网C语言下载地址:http://word2vec.googlecode.com/svn/trunk/ 官网Python ...
- word2vec词向量处理中文语料
word2vec介绍 word2vec官网:https://code.google.com/p/word2vec/ word2vec是google的一个开源工具,能够根据输入的词的集合计算出词与词之间 ...
- 机器学习之路: python 实践 word2vec 词向量技术
git: https://github.com/linyi0604/MachineLearning 词向量技术 Word2Vec 每个连续词汇片段都会对后面有一定制约 称为上下文context 找到句 ...
- word2vec词向量处理英文语料
word2vec介绍 word2vec官网:https://code.google.com/p/word2vec/ word2vec是google的一个开源工具,能够根据输入的词的集 ...
- 机器学习入门-文本特征-word2vec词向量模型 1.word2vec(进行word2vec映射编码)2.model.wv['sky']输出这个词的向量映射 3.model.wv.index2vec(输出经过映射的词名称)
函数说明: 1. from gensim.model import word2vec 构建模型 word2vec(corpus_token, size=feature_size, min_count ...
- 文本分类实战(一)—— word2vec预训练词向量
1 大纲概述 文本分类这个系列将会有十篇左右,包括基于word2vec预训练的文本分类,与及基于最新的预训练模型(ELMo,BERT等)的文本分类.总共有以下系列: word2vec预训练词向量 te ...
- 文本情感分析(二):基于word2vec、glove和fasttext词向量的文本表示
上一篇博客用词袋模型,包括词频矩阵.Tf-Idf矩阵.LSA和n-gram构造文本特征,做了Kaggle上的电影评论情感分类题. 这篇博客还是关于文本特征工程的,用词嵌入的方法来构造文本特征,也就是用 ...
- PyTorch在NLP任务中使用预训练词向量
在使用pytorch或tensorflow等神经网络框架进行nlp任务的处理时,可以通过对应的Embedding层做词向量的处理,更多的时候,使用预训练好的词向量会带来更优的性能.下面分别介绍使用ge ...
随机推荐
- Linux环境下利用句柄恢复Oracle误删除的数据文件
在误删除Oracle的数据文件后,如果未关闭数据库,文件句柄还没有释放,且被删除的数据文件占用的磁盘块未被复写,则可以利用句柄的方式来恢复数据文件.下面模拟恢复过程. (一)环境 OS版本:redha ...
- udt通信java再次升级1.1版
以前完成了udt的java代码测试,功能基本完成,近几天有时间重新梳理了下源码: 对原通信的关闭统一了方法,close定位过时,由shutdown与shutdownNow代替. 将一些主要方法添加了注 ...
- 1486: [HNOI2009]最小圈
Time Limit: 10 Sec Memory Limit: 64 MBSubmit: 3129 Solved: 1543[Submit][Status][Discuss] Descripti ...
- poj 1236 Network of Schools : 求需要添加多少条边成为强连通图 tarjan O(E)
/** problem: http://poj.org/problem?id=1236 缩点后入度为0的点的总数为需要发放软件的学校个数 缩点后出度为0的点的总数和入度为0的点的总数的最大值为需要增加 ...
- VC中edit控件使用
SetSel(start,end)作用:定制EDIT的所选择内容.间接地可以用于定位光标位置. 使用例子:EXP1:设置光标CEdit* pEdit=(CEdit*)GetDlgItem(I ...
- union的两个子查询是否并行
需求描述 问题:subquery 1 union subquery2,其中union左右的两个子查询是否并行. 场景:业务中性能敏感的业务,希望能加快速度,如果数据库能两个子查询并行执行,既可以节省时 ...
- 通过xshell在linux上安装tomcat8
通过xshell在linux上安装tomcat8 0)去官网下载linux版压缩包(点击去下载) 1)创建存放tomcat的文件夹 mkdir /usr/tomcat 2)通过xftp将其放置到指定文 ...
- Mac系统配置php环境
[写在前面——叨叨叨] -_-#急着配环境的同志们可以绕道.最近学校的实验室里接了一个小项目——考勤刷卡系统,利用RFID在硬件层获取学生卡的ID,通过wifi传输至服务器,进行考勤信息存储,手机端获 ...
- wordpress整站无损搬迁的几种方法 最后一种最完美
网站建设之wordpress整站无损搬迁的几种方法 最后一种最完美 网站搬家,当我们更换php虚拟主机,空间升级或更好空间提供商都会发生,站长们请注意,掌握网站迁移方法,是网站日常维护技术中必须掌握的 ...
- centos7中vsftp的搭建
开启vsftpd:service vsftpd start关闭vsftp:service vsftpd stop 安装vsftpd: yum -y install vsftpd 建立vsftpd帐号: ...