Selenium2+python自动化49-判断文本(text_to_be_present_in_element)
前言
在做结果判断的时候,经常想判断某个元素中是否存在指定的文本,如登录后判断页面中是账号是否是该用户的用户名。
在前面的登录案例中,写了一个简单的方法,但不是公用的,在EC模块有个方法是可以专门用来判断元素中存在指定文本的:text_to_be_present_in_element。
另外一个差不多复方法判断元素的value值:text_to_be_present_in_element_value。
一、源码分析
class text_to_be_present_in_element(object):
""" An expectation for checking if the given text is present in the
specified element.
locator, text
"""
'''翻译:判断元素中是否存在指定的文本,参数:locator, text'''
def __init__(self, locator, text_):
self.locator = locator
self.text = text_
def __call__(self, driver):
try:
element_text = _find_element(driver, self.locator).text
return self.text in element_text
except StaleElementReferenceException:
return False
1.翻译:判断元素中是否存在指定的文本,两个参数:locator, text
2.__call__里返回的是布尔值:Ture和False
二、判断文本
1.判断百度首页上,“糯米”按钮这个元素中存在文本:糯米
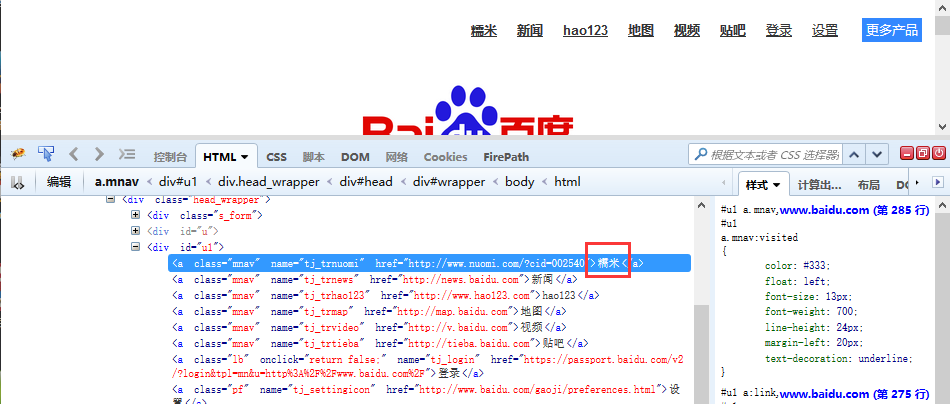
2.locator参数是定位的方法
3.text参数是期望的值
三、失败案例
1.如果判断失败,就返回False

四、判断value的方法
class text_to_be_present_in_element_value(object):
"""
An expectation for checking if the given text is present in the element's
locator, text
"""
def __init__(self, locator, text_):
self.locator = locator
self.text = text_
def __call__(self, driver):
try:
element_text = _find_element(driver,
self.locator).get_attribute("value")
if element_text:
return self.text in element_text
else:
return False
except StaleElementReferenceException:
return False
1.这个方法跟上面的差不多,只是这个是判断的value的值
2.这里举个简单案例,判断百度搜索按钮的value值

五、参考代码
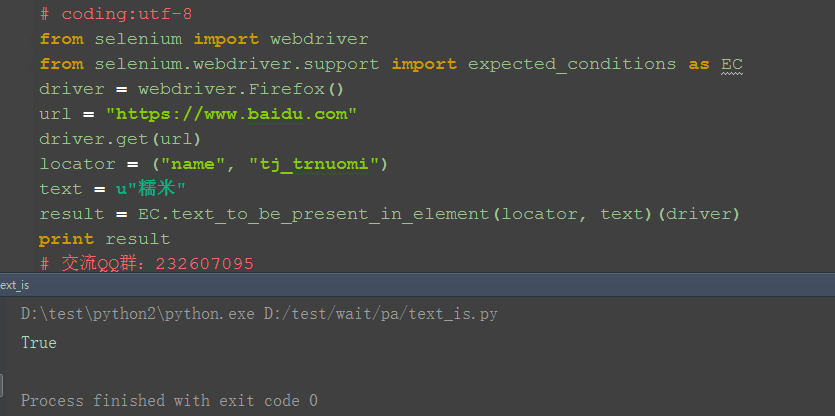
# coding:utf-8
from selenium import webdriver
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Firefox()
url = "https://www.baidu.com"
driver.get(url)
locator = ("name", "tj_trnuomi")
text = u"糯米"
result = EC.text_to_be_present_in_element(locator, text)(driver)
print result
# 交流QQ群:232607095
# 下面是失败的案例
text1 = u"糯米网"
result1 = EC.text_to_be_present_in_element(locator, text1)(driver)
print result1
locator2 = ("id", "su")
text2 = u"百度一下"
result2 = EC.text_to_be_present_in_element_value(locator2, text2)(driver)
print result2
学习过程中有遇到疑问的,可以加selenium(python+java) QQ群交流:646645429
觉得对你有帮助,就在右下角点个赞吧!
selenium+python高级教程》已出书:selenium webdriver基于Python源码案例
(购买此书送对应PDF版本)

Selenium2+python自动化49-判断文本(text_to_be_present_in_element)的更多相关文章
- Selenium2+python自动化49-判断文本(text_to_be_present_in_element)【转载】
前言 在做结果判断的时候,经常想判断某个元素中是否存在指定的文本,如登录后判断页面中是账号是否是该用户的用户名. 在前面的登录案例中,写了一个简单的方法,但不是公用的,在EC模块有个方法是可以专门用来 ...
- Selenium2+python自动化23-富文本(自动发帖)
前言 富文本编辑框是做web自动化最常见的场景,有很多小伙伴遇到了不知道无从下手,本篇以博客园的编辑器为例,解决如何定位富文本,输入文本内容 一.加载配置 1.打开博客园写随笔,首先需要登录,这里为了 ...
- Selenium2+python自动化24-js处理富文本(带iframe)
前言 上一篇Selenium2+python自动化23-富文本(自动发帖)解决了富文本上iframe问题,其实没什么特别之处,主要是iframe的切换,本篇讲解通过js的方法处理富文本上iframe的 ...
- Selenium2+python自动化24-js处理富文本(带iframe)【转载】
前言 上一篇Selenium2+python自动化23-富文本(自动发帖)解决了富文本上iframe问题,其实没什么特别之处,主要是iframe的切换,本篇讲解通过js的方法处理富文本上iframe的 ...
- Selenium2+python自动化23-富文本(自动发帖)【转载】
前言 富文本编辑框是做web自动化最常见的场景,有很多小伙伴遇到了不知道无从下手,本篇以博客园的编辑器为例,解决如何定位富文本,输入文本内容 一.加载配置 1.打开博客园写随笔,首先需要登录,这里为了 ...
- Selenium2+Python自动化学习笔记(第1天)
参考[http://blog.csdn.net/henni_719/article/details/51096531]大神写的笔记,多谢大神共享. 哈哈,今天又找到一位大神写的Selenium2+Py ...
- Selenium2+python自动化(学习笔记3)
1.加载firefox配置 参考代码: # coding=utf-8from selenium import webdriver# 配置文件地址,打开Firefox点右上角设置--帮助--故障排除信息 ...
- Selenium2+python自动化13-Alert
不是所有的弹出框都叫alert,在使用alert方法前,先要识别出它到底是不是alert.先认清楚alert长什么样子,下次碰到了,就可以用对应方法解决.alert\confirm\prompt弹出框 ...
- Selenium2+python自动化28-table定位
前言 在web页面中经常会遇到table表格,特别是后台操作页面比较常见.本篇详细讲解table表格如何定位. 一.认识table 1.首先看下table长什么样,如下图,这种网状表格的都是table ...
随机推荐
- ssm使用Ajax的formData进行异步图片上传返回图片路径,并限制格式和大小
之前整理过SSM的文件上传,这次直接用代码了. 前台页面和js //form表单 <form id= "uploadForm" enctype="multipart ...
- CCF CSP 201709-2 公共钥匙盒
CCF计算机职业资格认证考试题解系列文章为meelo原创,请务必以链接形式注明本文地址 CCF CSP 201709-2 公共钥匙盒 问题描述 有一个学校的老师共用N个教室,按照规定,所有的钥匙都必须 ...
- Spark(十四)SparkStreaming的官方文档
一.SparkCore.SparkSQL和SparkStreaming的类似之处 二.SparkStreaming的运行流程 2.1 图解说明 2.2 文字解说 1.我们在集群中的其中一台机器上提交我 ...
- Tomcat --> Cannot create a server using the selected type
今天在eclipse想把之前的Tomcat 6删掉,重新配置一个,不料没有下一步 Cannot create a server using the selected type 这句话出现在窗口上面,应 ...
- scala递归实现换零钱算法
import scala.collection.mutable.ArrayBuffer import scala.util.control.Breaks object Exchange { def d ...
- 通过GeneXus如何快速构建微服务架构
概览 “微服务”是一个非常广泛的话题,在过去几年里,市面上存在着各种不同的定义. 虽然对这种架构方式没有一个非常精确的定义,但仍然有一些概念具有代表性. 微服务有着许多围绕业务能力.自动化部署.终端智 ...
- 机器学习:KNN-近邻算法
一.理论知识 1.K近邻(k-Nearest Neighbor,简称KNN)学习是一种常用的监督学习. 工作机制:给定测试样本,基于某种距离度量找出训练集中与其最靠近的k个训练样本,然后基于这k个的信 ...
- [转]kali中eth0网卡突然消失解决方案
前言 不知道怎么kali的eth0网卡突然消失了.这可有点难受啊.在网上查找了一番找到了解决办法,特此记录. 问题 怎么办? 解决办法 首先使用ifconfig -a命令查看所有的网卡接口 发现 ...
- rest framework 类 继承图
- 【BZOJ 2688】 2688: Green Hackenbush (概率DP+博弈-树上删边)
2688: Green Hackenbush Time Limit: 10 Sec Memory Limit: 128 MBSubmit: 42 Solved: 16 Description ...